| The LP Procedure |
Sparse Data Input Format
The sparse format to PROC LP is designed to enable you to specify only the nonzero coefficients in the description of linear programs, integer programs, and mixed-integer programs. The SAS data set that describes the sparse model must contain at least four SAS variables:
- a type variable
- a column variable
- a row variable
- a coefficient variable
The values of the row and column variables are the names of the rows and columns in the model. The values of the coefficient variables define basic coefficients and lower and upper bounds, and identify model variables with types BASIC, FIXED, BINARY, and INTEGER. All character values in the sparse data input format are case insensitive.
The SAS data set can contain multiple pairs of rows and coefficient variables. In this way, more information about the model can be specified in each observation in the data set. See Example 3.2 for details.
| TYPE (_TYPE_) | COL (_COL_) |
| MIN | |
| MAX | |
| EQ | |
| LE | |
| GE | |
| SOSEQ | |
| SOSLE | |
| UNRSTRT | |
| LOWERBD | |
| UPPERBD | |
| FIXED | |
| INTEGER | |
| BINARY | |
| BASIC | |
| PRICESEN | |
| FREE | |
| RHS | _RHS_ |
| RHSSEN | _RHSSEN_ |
| RANGE | _RANGE_ |
- The order of the observations is unimportant.
- Each unique column name appearing in the COL variable defines a unique column in the model.
- Each unique row name appearing in the ROW variable defines a unique row in the model.
- The type of the row is identified when an observation in which the row name appears (in a ROW variable) has type MIN, MAX, LE, GE, EQ, SOSLE, SOSEQ, LOWERBD, UPPERBD, UNRSTRT, FIXED, BINARY, INTEGER, BASIC, FREE, or PRICESEN.
- The type of each row must be identified at least once. If a row is given a type more than once, the multiple definitions must be identical.
- When there are multiple rows named in an observation (that is, when there are multiple ROW variables), the TYPE variable applies to each row named in the observation.
- The type of a column is identified when an observation in which the column name but no row name appears has the type LOWERBD, UPPERBD, UNRSTRT, FIXED, BINARY, INTEGER, BASIC, RHS, RHSSEN, or RANGE. A column type can also be identified in an observation in which both column and row names appear and the row name has one of the preceding types.
- Each column is assumed to be a structural column in the model unless the column is identified as a right-hand-side vector, a right-hand-side change vector, or a range vector. A column can be identified as one of these types using either the keywords RHS, RHSSEN, or RANGE in the TYPE variable, the special column names _RHS_, _RHSSEN_, or _RANGE_, or the RHS, RHSSEN, or RANGE statements following the PROC LP statement.
- A TYPE variable beginning with the character
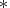 causes the observation to be interpreted as a comment.
causes the observation to be interpreted as a comment.
When the column names appear in the Variable Summary in the PROC LP output, they are listed in alphabetical order. The row names appear in the order in which they appear in the problem data set.
Copyright © 2008 by SAS Institute Inc., Cary, NC, USA. All rights reserved.