The INTPOINT Procedure
-
Overview

-
Getting Started
-
SyntaxFunctional SummaryDictionary of OptionsPROC INTPOINT StatementCAPACITY StatementCOEF StatementCOLUMN StatementCOST StatementDEMAND StatementHEADNODE StatementID StatementLO StatementNAME StatementNODE StatementQUIT StatementRHS StatementROW StatementRUN StatementSUPDEM StatementSUPPLY StatementTAILNODE StatementTYPE StatementVAR Statement
-
DetailsInput Data SetsOutput Data SetsConverting Any PROC INTPOINT Format to an MPS-Format SAS Data SetCase SensitivityLoop ArcsMultiple ArcsFlow and Value BoundsTightening Bounds and Side ConstraintsReasons for InfeasibilityMissing S Supply and Missing D Demand ValuesBalancing Total Supply and Total DemandHow to Make the Data Read of PROC INTPOINT More EfficientStopping Criteria
-
ExamplesProduction, Inventory, Distribution ProblemAltering Arc DataAdding Side ConstraintsUsing Constraints and More Alteration to Arc DataNonarc Variables in the Side ConstraintsSolving an LP Problem with Data in MPS FormatConverting to an MPS-Format SAS Data SetMigration to OPTMODEL: Production, Inventory, Distribution
- References
This section contains information that is useful when you want to solve large constrained network problems. However, much of this information is also useful if you have a large linear programming problem. All of the options described in this section that are not directly applicable to networks (options such as ARCS_ONLY_ARCDATA , ARC_SINGLE_OBS , NNODES= , and NARCS= ) can be specified to improve the speed at which LP data are read.
Many of the models presented to PROC INTPOINT are enormous. They can be considered large by linear programming standards; problems with thousands, even millions, of variables and constraints. When dealing with side constrained network programming problems, models can have not only a linear programming component of that magnitude, but also a larger, possibly much larger, network component.
The majority of network problem’s decision variables are arcs. Like an LP decision variable, an arc has an objective function coefficient, upper and lower value bounds, and a name. Arcs can have coefficients in constraints. Therefore, an arc is quite similar to an LP variable and places the same memory demands on optimization software as an LP variable. But a typical network model has many more arcs and nonarc variables than the typical LP model has variables. And arcs have tail and head nodes. Storing and processing node names require huge amounts of memory. To make matters worse, node names occupy memory at times when a large amount of other data should also reside in memory.
While memory requirements are lower for a model with embedded network component compared with the equivalent LP once optimization starts, the same is usually not true during the data read. Even though nodal flow conservation constraints in the LP should not be specified in the constrained network formulation, the memory requirements to read the latter are greater because each arc (unlike an LP variable) originates at one node and is directed toward another.
PROC INTPOINT has facilities to read data when the available memory is insufficient to store all the data at once. PROC INTPOINT does this by allocating memory for different purposes; for example, to store an array or receive data read from an input SAS data set. After that memory has filled, the information is written to disk and PROC INTPOINT can resume filling that memory with new information. Often, information must be retrieved from disk so that data previously read can be examined or checked for consistency. Sometimes, to prevent any data from being lost, or to retain any changes made to the information in memory, the contents of the memory must be sent to disk before other information can take its place. This process of swapping information to and from disk is called paging. Paging can be very time-consuming, so it is crucial to minimize the amount of paging performed.
There are several steps you can take to make PROC INTPOINT read the data of network and linear programming models more efficiently, particularly when memory is scarce and the amount of paging must be reduced. PROC INTPOINT will then be able to tackle large problems in what can be considered reasonable amounts of time.
PROC INTPOINT is quite flexible in the ways data can be supplied to it. Data can be given by any reasonable means. PROC INTPOINT has convenient defaults that can save you work when generating the data. There can be several ways to supply the same piece of data, and some pieces of data can be given more than once. PROC INTPOINT reads everything, then merges it all together. However, this flexibility and convenience come at a price; PROC INTPOINT may not assume the data has a characteristic that, if possessed by the data, could save time and memory during the data read. Several options can indicate that the data has some exploitable characteristic.
For example, an arc cost can be specified once or several times in the ARCDATA= data set or the CONDATA= data set, or both. Every time it is given in the ARCDATA= data set, a check is made to ensure that the new value is the same as any corresponding value read in a previous observation of the ARCDATA= data set. Every time it is given in the CONDATA= data set, a check is made to ensure that the new value is the same as the value read in a previous observation of the CONDATA= data set, or previously in the ARCDATA= data set. PROC INTPOINT would save time if it knew that arc cost data would be encountered only once while reading the ARCDATA= data set, so performing the time-consuming check for consistency would not be necessary. Also, if you indicate that the CONDATA= data set contains data for constraints only, PROC INTPOINT will not expect any arc information, so memory will not be allocated to receive such data while reading the CONDATA= data set. This memory is used for other purposes and this might lead to a reduction in paging. If applicable, use the ARC_SINGLE_OBS or the CON_SINGLE_OBS option, or both, and the NON_REPLIC= COEFS specification to improve how the ARCDATA= data set and the CONDATA= data set are read.
PROC INTPOINT allows the observations in input data sets to be in any order. However, major time savings can result if you are prepared to order observations in particular ways. Time spent by the SORT procedure to sort the input data sets, particularly the CONDATA= data set, may be more than made up for when PROC INTPOINT reads them, because PROC INTPOINT has in memory information possibly used when the previous observation was read. PROC INTPOINT can assume a piece of data is either similar to that of the last observation read or is new. In the first case, valuable information such as an arc or a nonarc variable number or a constraint number is retained from the previous observation. In the last case, checking the data with what has been read previously is not necessary.
Even if you do not sort the CONDATA= data set, grouping observations that contain data for the same arc or nonarc variable or the same row pays off. PROC INTPOINT establishes whether an observation being read is similar to the observation just read.
In practice, many input data sets for PROC INTPOINT have this characteristic, because it is natural for data for each constraint to be grouped together (when using the dense format of the CONDATA= data set) or data for each column to be grouped together (when using the sparse format of the CONDATA= data set). If data for each arc or nonarc is spread over more than one observation of the ARCDATA= data set, it is natural to group these observations together.
Use the GROUPED= option to indicate whether observations of the ARCDATA= data set, the CONDATA= data set, or both, are grouped in a way that can be exploited during data read.
You can save time if the type data for each row appears near the top of the CONDATA= data set, especially if it has the sparse format. Otherwise, when reading an observation, if PROC INTPOINT does not know if a row is a constraint or special row, the data are set aside. Once the data set has been completely read, PROC INTPOINT must reprocess the data it set aside. By then, it knows the type of each constraint or row or, if its type was not provided, it is assumed to have a default type.
In order for PROC INTPOINT to make better utilization of available memory, you can specify options that indicate the approximate size of the model. PROC INTPOINT then knows what to expect. For example, if you indicate that the problem has no nonarc variables, PROC INTPOINT will not allocate memory to store nonarc data. That memory is better utilized for other purposes. Memory is often allocated to receive or store data of some type. If you indicate that the model does not have much data of a particular type, the memory that would otherwise have been allocated to receive or store that data can be used to receive or store data of another type.
The problem size options are as follows:
These options will sometimes be referred to as Nxxxx= options.
You do not need to specify all these options for the model, but the more you do, the better. If you do not specify some or all of these options, PROC INTPOINT guesses the size of the problem by using what it already knows about the model. Sometimes PROC INTPOINT guesses the size of the model by looking at the number of observations in the ARCDATA= and the CONDATA= data sets. However, PROC INTPOINT uses rough rules of thumb, that typical models are proportioned in certain ways (for example, if there are constraints, then arcs, nonarc variables, or LP variables usually have about five constraint coefficients). If your model has an unusual shape or structure, you are encouraged to use these options.
If you do use the options and you do not know the exact values to specify, overestimate the values. For example, if you specify NARCS=10000 but the model has 10100 arcs, when dealing with the last 100 arcs, PROC INTPOINT might have to page out data for 10000 arcs each time one of the last arcs must be dealt with. Memory could have been allocated for all 10100 arcs without affecting (much) the rest of the data read, so NARCS=10000 could be more of a hindrance than a help.
The point of these Nxxxx= options is to indicate the model size when PROC INTPOINT does not know it. When PROC INTPOINT knows the "real" value, that value is used instead of Nxxxx= .
ARCS_ONLY_ARCDATA indicates that data for only arcs are in the ARCDATA= data set. Memory would not be wasted to receive data for nonarc variables.
Specifying an appropriate value for the BYTES= parameter is particularly important. Specify as large a number as possible, but not so large a number that will cause PROC INTPOINT (that is, the SAS System running underneath PROC INTPOINT) to run out of memory.
PROC INTPOINT reports its memory requirements on the SAS log if you specify the MEMREP option.
Use the parameters that specify default values as much as possible. For example, if there are many arcs with the same cost value c, use DEFCOST= c for arcs that have that cost. Use missing values in the COST variable in the ARCDATA= data set instead of c. PROC INTPOINT ignores missing values, but must read, store, and process nonmissing values, even if they are equal to a default option or could have been equal to a default parameter had it been specified. Sometimes, using default parameters makes the need for some SAS variables in the ARCDATA= and the CONDATA= data sets no longer necessary, or reduces the quantity of data that must be read. The default options are
-
DEFCOST= default cost of arcs, objective function of nonarc variables or LP variables
-
DEFMINFLOW= default lower flow bound of arcs, lower bound of nonarc variables or LP variables
-
DEFCAPACITY= default capacity of arcs, upper bound of nonarc variables or LP variables
-
DEFCONTYPE= LE or DEFCONTYPE=
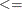 DEFCONTYPE=
EQ or DEFCONTYPE=
= DEFCONTYPE=
GE or DEFCONTYPE=
DEFCONTYPE=
EQ or DEFCONTYPE=
= DEFCONTYPE=
GE or DEFCONTYPE=
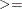
DEFCONTYPE= LE is the default.
The default options themselves have defaults. For example, you do not need to specify DEFCOST= 0 in the PROC INTPOINT statement. You should still have missing values in the COST variable in the ARCDATA= data set for arcs that have zero costs.
If the network has only one supply node, one demand node, or both, use
Do not specify that a constraint has zero right-hand-side values. That is the default. The only time it might be practical to specify a zero rhs is in observations of the CONDATA= data set read early so that PROC INTPOINT can infer that a row is a constraint. This could prevent coefficient data from being put aside because PROC INTPOINT did not know the row was a constraint.
To cut data read time and memory requirements, reduce the number of bytes in the longest node name, the longest arc name, the longest nonarc variable name, the longest LP variable name, and the longest constraint name to 8 bytes or less. The longer a name, the more bytes must be stored and compared with other names.
If an arc has no constraint coefficients, do not give it a name in the NAME list variable in the ARCDATA= data set. Names for such arcs serve no purpose.
PROC INTPOINT can have a default name for each arc. If an arc is directed from node tailname toward node headname, the default name for that arc is tailname_headname. If you do not want PROC INTPOINT to use these default arc names, specify NAMECTRL= 1. Otherwise, PROC INTPOINT must use memory for storing node names and these node names must be searched often.
If you want to use the default tailname_headname name, that is, NAMECTRL=
2 or NAMECTRL=
3, do not use underscores in node names. If the CONDATA
has a dense
format and has a variable in the VAR
list A_B_C_D, or if the value A_B_C_D is encountered as a value of the COLUMN
list variable when reading the CONDATA=
data set that has the sparse
format, PROC INTPOINT first looks for a node named A. If it finds it, it looks for a node called B_C_D. It then looks for a node with the name A_B and possibly a node with name C_D. A search is then conducted for a node named A_B_C and possibly a node named D is done. Underscores could have caused PROC INTPOINT to look unnecessarily for nonexistent nodes.
Searching for node names can be expensive, and the amount of memory to store node names is often large. It might be better
to assign the arc name A_B_C_D directly to an arc by having that value as a NAME
list variable value for that arc in the ARCDATA=
data set and specify NAMECTRL=
1.
Arcs and nonarc variables, or LP variables, can have associated with them values or quantities that have no bearing on the optimization. This information is given in the ARCDATA= data set in the ID list variables. For example, in a distribution problem, information such as truck number and driver’s name can be associated with each arc. This is useful when the optimal solution saved in the CONOUT= data set is analyzed. However, PROC INTPOINT needs to reserve memory to process this information when data are being read. For large problems when memory is scarce, it might be better to remove ancillary data from the ARCDATA . After PROC INTPOINT runs, use SAS software to merge this information into the CONOUT= data set that contains the optimal solution.