RECOMMEND Procedure

Example 2: Recommendations from Implicit Information
Details
In many situations,
it is difficult to obtain explicit ratings that can be directly used
to infer user preferences. Instead, we are provided with feedback
such as purchase history, browsing history, search patterns, or time
spent on a website. This documentation presents two ways to infer
user preferences from abundant implicit feedback to build a recommender
system.
Let U denote
the number of users, and let I denote
the number of items. Let 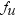 denote the frequency of user u purchasing
any item, and let
denote the frequency of user u purchasing
any item, and let 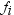 denote the frequency of any user purchasing item i.
Let
denote the frequency of any user purchasing item i.
Let 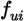 denote the frequency of item i being
purchased by user u. Similar
to the term frequency-inverse document frequency weight
denote the frequency of item i being
purchased by user u. Similar
to the term frequency-inverse document frequency weight 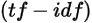 in text mining, there are two methods that we can
use to convert frequency to ratings
in text mining, there are two methods that we can
use to convert frequency to ratings 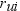 :
:
denote the frequency of user u purchasing
any item, and let denote the frequency of any user purchasing item i.
Let denote the frequency of item i being
purchased by user u. Similar
to the term frequency-inverse document frequency weight in text mining, there are two methods that we can
use to convert frequency to ratings :
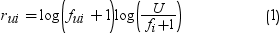
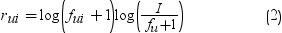
Equation 1 places larger
weight on items that are purchased less frequently. Equation 2 places
larger weight on users who purchase items less frequently.
Program: Transform a Transaction Table into a Rating Table
The following code
provides an example of the syntax. The referenced table, salesfact,
is not available for use. The table can be as simple as one column
for a user ID and another column for the item ID.
proc imstat; table MYlasr.salesfact; 1 tableinfo / save = tabinf; store tabinf(1,3) = nObs; run; distinct / save = dtab; store dtab(1,2) = numItem; store dtab(2,2) = numUser; run; table MYlasr.salesfact; 2 compute joinkey "joinkey = &userID || &itemID;"; run; table MYlasr.salesfact(tempnames=(t1)); summary t1 / groupby=(&userID &itemID) temptable tn=t1 3 te="t1=1;" save=tabl; summary t1 / groupby=(&userID) temptable tn=t1 te="t1=1;" save=tab2; summary t1 / groupby=(&itemID) temptable tn=t1 te="t1=1;" save=tab3; run; store tab1(2,2) = freq_user_item; 4 store tab2(2,2) = freq_user; store tab3(2,2) = freq_item; run; table MYlasr.&freq_user_item; schema &freq_user(&userID=&userID / prefix=UserTotal,_n_) 5 &freq_item(&itemID=&itemID / prefix=ItemTotal,_n_) / mode=table; run; table MYlasr.&_templast_; 6 compute joinkey "joinkey = &userID || &itemID;"; run; table MYlasr.salesfact; schema &_templast_(joinkey=joinkey / prefix=r,_n_ UserTotal__N_ ItemTotal__N_); run; table MYlasr.&_templast_; compute Rating_iuf "Rating_iuf = log10(r__N_+1)*log10(&nObs/(r_ItemTotal__n_+1));"; run; compute Rating_iif "Rating_iif = log10(r__N+1)*log10(&nObs/(r_UserTotal__n_+1));"; run; compute Rating_simple "Rating_simple = Round((r__N_/r_UserTotal__n_)*10+1,1);"; run; table MYlasr.&_templast_; 7 save path="/hps/rating_tfidf" copies=1 replace fullpath; run;
Program Description
-
The STORE statements assign the number of observations, the number of distinct users, and the number of distinct items to macro variables.
-
The COMPUTE statement adds a permanent column by concatenating the user ID and the item ID values.
-
The SUMMARY statements with the GROUPBY= option produce descriptive statistics in the temporary column (t1). The results of the SUMMARY statements are saved to temporary tables.
-
The STORE statements assign the names of the three temporary tables to three macro variables, Freq_User_Item, Freq_User, and Freq_Item.
-
The SCHEMA statement joins the star tables Freq_User_Item, Freq_User, and Freq_Item and creates a new temporary table.
-
Generate the ratings table. By using equations 1 and 2, as described in Details, convert the frequency counts into ratings.
-
The SAVE statement saves the rating table directly into HDFS as a SASHDAT table for future use.
Program: Create a Recommender System with the Rating Table
The following code
provides an example of the syntax. The referenced tables are
not available for use.
proc recommend port=&lasrport recom = rs.DEPTSTORE; add rs.DEPTSTORE /item = item_sk user = household_sk 1 rating = &rating; addtable MYlasr.MBA_rating_tfidf / recom = rs.DEPTSTORE 2 type = rating vars=(item_sk household_sk &rating); addtable MYlasr.household / recom = rs.DEPTSTORE type = user; addtable MYlasr.item / recom = rs.DEPTSTORE type = item; run; method cluster / clusttech=kmeans numclus=50 dist=euc type=user 3 maxiter=10 label="clust" details terms=("Convenience", "Occasional", "Unk") tokens=(" ") noidf seed=1234 clustinfo clustvars=(LIFESTYLE_SEGMENT FAMILY PET); run; predict / users=("11815911") method=cluster label="clust" 4 Num = 5; run; method svd / factors = 20 label = "svd_1" fconv = 1e-3 gconv = 1e-3 5 maxiter = 100 seed = 12314 MAXFEVAL = 5000 function=L2 lamda = 0.2 technique = als; run; predict / method = svd label = "svd_1" Num = 5 6 users = ("11815911"); run; quit;
Program Description
-
The ADD statement adds the Rs.DEPTSTORE system to the server.
-
The ADDTABLE statements add the tables to be analyzed to the system.
-
The METHOD statement using the CLUSTER method applies a model that first clusters users into several groups according to user profiles. Then, the method uses the nearest neighbor method to predict unknown ratings.
-
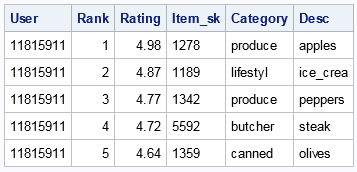
The PREDICT statement generates the top 5 ranked products for user 11815911 using the cluster method.
-
The next METHOD statement using the SVD method applies a model that is based on a singular-value decomposition of a user-item-ratings matrix.
-
The next PREDICT statement generates the top 5 ranked products for user 11815911 using the SVD method.
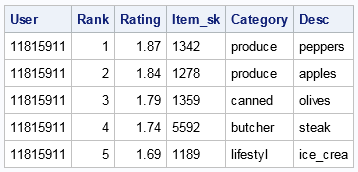
PREDICT Statement Output
Output from the PREDICT Statement (Cluster Method)
Output from the PREDICT Statement (SVD Method)
Copyright © SAS Institute Inc. All Rights Reserved.