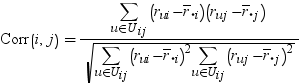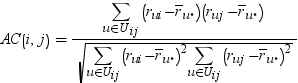RECOMMEND Procedure

METHOD Statement
The METHOD statement adds a method for computing recommendations for a recommender system. You can use the METHOD statement to specify details for a method definition, rather than using the default settings for that method.
Syntax
Required Argument
method-name
specifies the name of the method to add to a recommender system. The method name can be one of the following values:
| AVERAGE | AVE | AVG | a default method that is used to produce recommendations for users that have insufficient information in the recommender system. For example, a method might require that at least two ratings are on record for a user. If that is not the case, a request for a recommendation is provided with the AVG method. |
| SLOPEONE | SLOPE1 | a simple regression-based method. |
| NEAREST | KNN | a k-nearest-neighbor method that is based on measures of association between items or users. This method is also called a collaborative filter. |
| SVD | a recommender method that is based on a singular-value decomposition of a user-item-ratings matrix. |
| ENSEMBLE | a collection of other methods that you specify. |
| ARM | a method that performs associative rule mining (ARM). |
| CLUSTER | a cluster-based method that uses item or user profiles. Items or users are clustered. Then the similarity information between items or users for each cluster is computed to make recommendations. |
Optional Arguments
DATAFILTER="expression"
specifies an optional WHERE clause for each method. All of the data is filtered by this WHERE clause.
DETAILS
requests that additional details are provided for the numerically intensive SVD and ensemble methods.
LABEL='string'
specifies a label by which the method can be identified. A label is important if you have multiple instances of a method definition (with different parameter values) in the recommender system.
FCONV=r
specifies a relative function convergence criterion for the numerical optimization in SVD and ensemble methods.
GCONV=r
specifies a relative gradient convergence criterion for the numerical optimization in SVD and ensemble methods.
MAXITER=n
specifies the maximum number of iterations for the numerical optimization in SVD and ensemble methods.
| Default | 1 (a one-step update) |
MAXFEVAL=n
specifies the maximum number of function evaluations for the numerical optimization in SVD and ensemble methods.
SEED=n
specifies the seed for random number generation in SVD and ensemble methods.
SYSTEM=recommender-system
specifies the name of the recommender system in the SAS LASR Analytic Server that the procedure works with. Specify a two-level name, similar to a LIBNAME.MEMBER construct.
| Alias | RECOM= |
| Default | RECOM.SYSTEM |
Options for the SLOPEONE Method
HOLD=n
specifies the number of ratings to hold for users that are selected by the WITHHOLD= option. The specified number of ratings are selected at random to be held in a validation data set, which is a subset of the original data set.
| Default | 1 |
| Interaction | The HOLD= option is ignored if the WITHHOLD= option is not also specified. |
WITHHOLD=r
specifies a relative percentage of users whose ratings are included in a validation data set, which is a subset of the original data set. For example, WITHHOLD=0.1 indicates that 10% of users should be selected at random. A portion of the selected users’ ratings are held in the validation data set. The number of ratings to select is specified by the HOLD= option.
| Range | 0–1, exclusive |
Options for the KNN Method
HOLD=n
specifies the number of ratings to hold for users that are selected by the WITHHOLD= option. The specified number of ratings are selected at random to be held in a validation data set, which is a subset of the original data set.
| Default | 1 |
| Interaction | The HOLD= option is ignored if the WITHHOLD= option is not also specified. |
NEAREST=k
specifies the parameter k for a k-nearest-neighbor method. Only the k nearest neighbors are considered in deriving a recommendation for a particular user.
| Alias | K= |
NONNEGATIVE
requests that only positive associations are used when computing a neighborhood in a k-nearest-neighbor method.
| Alias | POSITIVE |
PREFILTER=NONE
PREFILTER=TOP(n)
PREFILTER=THRESHOLD(r)
specifies the type of prefiltering to apply when computing a neighborhood. If you specify PREFILTER=TOP(n), then a list of only the n nearest neighbors and their similarities are kept. If you specify PREFILTER=THRESHOLD(r), then the list of nearest neighbors includes items or users with similarities that exceed the threshold value r. If you specify PREFILTER=NONE, then neighborhoods are formed based on all similarities.
| Default | TOP(10) |
SIMILARITY=COSINE | COS | CV
SIMILARITY=CORR | PEARSON | PC
SIMILARITY=ADJCOS | AC
specifies the similarity measure that is used in k-nearest-neighbor collaborative filtering. If you specify SIMILARITY=COSINE (or COS or CV), then the cosine measure is the similarity measure. If you specify SIMILARITY=CORR (or PEARSON or PC), then the Pearson’s correlation coefficient, or product-moment correlation, is the similarity measure. If you specify SIMILARITY=ADJCOS (orAC), then the adjusted cosine measure is the similarity measure. For more information, see How Similarity Measures Are Calculated.
WITHHOLD=r
specifies a relative percentage of users whose ratings are included in a validation data set, which is a subset of the original data set. For example, WITHHOLD=0.1 indicates that 10% of users should be selected at random. A portion of the selected users’ ratings are held in the validation data set. The number of ratings to select is specified by the HOLD= option.
| Range | 0–1, exclusive |
Options for the SVD Method
BINARY=n
specifies a rule to generate a binary rating. If a numeric rating exceeds n, then the binary rating is set to 1. Otherwise, the binary rating is set to 0.
BINALPHA=m
specifies a weighting factor for the squared errors in the loss function of the matrix factorization.
HOLD=n
specifies the number of ratings to hold for users that are selected by the WITHHOLD= option. The specified number of ratings are selected at random to be held in a validation data set, which is a subset of the original data set.
| Default | 1 |
| Interaction | The HOLD= option is ignored if the WITHHOLD= option is not also specified. |
LOSS=SE
LOSS=SEREG
LOSS=SEWREG
LOSS=KL | ENTROPY
specifies the loss function for the matrix factorization. The LOSS=SE option indicates that the squared-error function is the loss function. The LOSS=SEREG and LOSS=SEWREG options are modifications of the squared-error loss function that include regularization terms in matrix norms or weighted matrix norms, respectively. Weighted regularization terms are weighted by λ, and you set the value of this parameter with the LAMBDA= option. The LOSS=KL (or ENTROPY) option indicates that the Kullback-Leibler divergence, or relative entropy, is the loss function.
LAMBDA=λ
specifies the regularization factor for the loss functions.
| Applies to | LOSS=SEREG or LOSS=SEWREG |
TECHNIQUE=LBFGS
TECHNIQUE=ALS
specifies the optimization method for the singular-value decomposition. The TECHNIQUE=LBFGS option indicates a limited-memory Broyden-Fletcher-Goldfarb-Shanno (BFGS) optimization method. This method is often used for solving neural network problems. The TECHNIQUE=ALS option indicates an alternating least squares optimization method.
WITHHOLD=r
specifies a relative percentage of users whose ratings are included in a validation data set, which is a subset of the original data set. For example, WITHHOLD=0.1 indicates that 10% of users should be selected at random. A portion of the selected users’ ratings are held in the validation data set. The number of ratings to select is specified by the HOLD= option.
| Range | 0–1, exclusive |
Options for Ensemble Method
CONSTRAINT
restricts the weights in the ensemble to lie between 0 and 1.
HOLD=n
specifies the number of ratings to hold for users that are selected by the WITHHOLD= option. The specified number of ratings are selected at random to be held in a validation data set, which is a subset of the original data set.
| Default | 1 |
| Interaction | The HOLD= option is ignored if the WITHHOLD= option is not also specified. |
METHODS=("method1", "method2" <,"method3" ...>)
specifies the methods that participate in the ensemble. Enclose each method in quotation marks, and separate multiple values with a comma.
| Default | All methods except the AVERAGE method. |
| Restriction | The AVERAGE method is not part of any ensemble. |
WITHHOLD=r
specifies a relative percentage of users whose ratings are included in a validation data set, which is a subset of the original data set. For example, WITHHOLD=0.1 indicates that 10% of users should be selected at random. A portion of the selected users’ ratings are held in the validation data set. The number of ratings to select is specified by the HOLD= option.
| Range | 0–1, exclusive |
Options for the Cluster Method
BUBMAXPTS=n
specifies the maximum number of points in each bubble. This number must exceed the value of the BUBMINPTS= option.
BUBMINPTS=n
specifies the minimum number of points in each bubble.
| Default | 1 |
CLUSTINFO
generates the temporary table that contains the cluster results for each user or item.
CLUSTVARS=(variable-list)
lists the variables to use with the CLUSTER method.
CLUSTERTECH=KMEANS
CLUSTERTECH=DBSCAN
specifies the clustering technique.
| Default | KMEANS |
CONV=c
specifies the convergence criterion c for the k-means analysis. When the relative change in WCSS between successive iterations is less than c, the analysis is presumed to have converged.
| Default | 0.00001 |
DIST=EUC | SQUAREDEUC | MANHATTAN | MAXIMUM | COSINE | JACCARD | HAMMING
specifies the distance measure that is used in the clustering method. The k-means method uses DIST=EUC.
| Applies to | CLUSTERTECH=DBSCAN |
DMAX=v
specifies the maximum diameter of bubbles with the given distance measure.
| Default | 0 |
EPS=r
specifies the distance value for neighborhood querying. For more information, see CLUSTER Statement.
| Applies to | CLUSTERTECH=DBSCAN |
INITMETHOD=FORGY | RAND | AVG
specifies the method for obtaining the initial estimate of cluster assignment. For more information, see CLUSTER Statement.
| Alias | INIT= |
MINPTS=n
specifies the minimum number of points that are required in one cluster.
| Applies to | CLUSTERTECH=DBSCAN |
NOCASE
specifies that the comparisons between terms and the values of character variables are case insensitive. By default, comparisons are case-sensitive.
NOIDF
specifies that only the term frequency is used to construct the vectors and that inverse document frequency is not used.
NONORM
specifies that the TF-IDF vectors are not normalized.
NREP=k
specifies the number of representative points for each bubble.
| Default | 1 |
NUMCLUSTERS=k
specifies the number of clusters for the k-means analysis.
| Alias | NUMCLUS= |
| Default | 2 |
SAVETERMS
saves the TF-IDF vectors in the temporary table when the CLUSTINFO option is enabled.
TERMS=("term1" <, "term2"...>)
specifies terms that are used to compute term frequency. Each string represents one term. For more information, see CLUSTER Statement.
TERMDATA=table-name
specifies an in-memory table in the server that contains the term list. For more information, see CLUSTER Statement.
TOKENS=("token1" <, "token2" ...>)
specifies the tokens that separate terms when scanning character variables. For more information, see CLUSTER Statement.
TOKENDATA=table-name
specifies an in-memory table in the server that contains the tokens list.
TYPE=ITEM | USER
specifies which type of profile is used for the CLUSTER method. The CLUSTER method that uses a user profile table cannot be used in the ensemble model with other methods.
| Requirement | The user or item table must be added into the recommender system. |
Details
How Similarity Measures Are Calculated
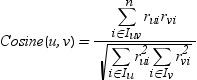
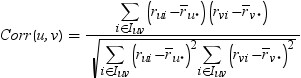
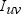 denotes the set of items that have been rated by
user u and user v.
The value
denotes the set of items that have been rated by
user u and user v.
The value 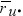 is the average rating by user u across
all items that she rated.
is the average rating by user u across
all items that she rated.
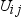 . The Pearson correlation measure between items i and j are
calculated as follows:
. The Pearson correlation measure between items i and j are
calculated as follows: