The SSM Procedure (Experimental)
-
Overview

- Getting Started
-
Syntax
-
DetailsState Space Model and NotationTypes of Data OrganizationOverview of Model Specification SyntaxLikelihood, Filtering, and SmoothingContrasting PROC SSM with Other SAS Procedures Predefined Trend ModelsPredefined Structural ModelsCovariance ParameterizationMissing ValuesComputational IssuesDisplayed OutputODS Table NamesODS Graph NamesOUT= Data Set
-
ExamplesBivariate Basic Structural Model Two-Way Random-Effects and Autoregressive Model for Panel DataBackcasting, Forecasting, and InterpolationSmoothing of Repeated Measures DataA User-Defined Trend ModelModel with Multiple ARIMA ComponentsDynamic Factor ModelingDiagnostic PlotsVariable Bandwidth Smoothing
- References
Getting Started: SSM Procedure
This example illustrates how you can use the SSM procedure to analyze a panel of time series. The following data set, Cigar, contains information about yearly per capita cigarette sales for 46 geographic regions in the United States over the period
1963–1992. The variables lsales, lprice, lndi, and lpimin denote the per capita cigarette sales, price per pack of cigarettes, per capita disposable income, and minimum price in adjoining
regions per pack of cigarettes, respectively (all in the natural log scale). The variable year contains the observation year, and the variable region contains an integer between 1 to 46 that serves as the unique identifier for the region. See Baltagi and Levin (1992) and
Baltagi (1995) for additional data description. The data are sorted by year.
data cigar;
input year region lsales lprice lndi lpimin;
label lsales = 'Log cigarette sales in packs per capita';
label lprice = 'Log price per pack of cigarettes';
label lndi = 'Log per capita disposable income';
label lpimin = 'Log minimum price in adjoining regions
per pack of cigarettes';
year = intnx( 'year', '1jan63'd, year-63 );
format year year.;
datalines;
63 1 4.54223 3.35341 7.3514 3.26194
63 2 4.82831 3.17388 7.5729 3.21487
63 3 4.63860 3.29584 7.3000 3.25037
63 4 4.95583 3.23080 7.9288 3.17388
63 5 5.05114 3.28840 7.9772 3.26576
... more lines ...
The goal of the analysis is to study the impact of the regressors on the smoking behavior and to understand the changes in
the smoking patterns in different regions over the years. Consider the following model for lsales:
|
|
This model represents lsales in a region ![]() and in a year
and in a year ![]() as a sum of region-specific trend components
as a sum of region-specific trend components ![]() , the regression effects due to
, the regression effects due to lprice, lndi, and lpimin, and the observation noise ![]() . Different variations of this model are obtained by considering different models for the trend component
. Different variations of this model are obtained by considering different models for the trend component ![]() . Proper modeling of the trend component is important because it captures differences between the regions because of unrecorded
factors such as demographic changes over time, results of anti-smoking campaigns, and so on. The following statements specify
and fit one such model:
. Proper modeling of the trend component is important because it captures differences between the regions because of unrecorded
factors such as demographic changes over time, results of anti-smoking campaigns, and so on. The following statements specify
and fit one such model:
proc ssm data=cigar plots=residual;
id year interval=year;
array RegionArray{46} region1-region46;
do i=1 to 46;
RegionArray[i] = (region=i);
end;
trend IrwTrend(ll) cross(matchparm)=(RegionArray) levelvar=0;
irregular wn;
model lsales = lprice lndi lpimin IrwTrend wn;
eval TrendPlusReg = IrwTrend + lprice + lndi + lpimin;
output out=forCigar pdv;
run;
The PROC SSM statement specifies the input data set, Cigar, which contains analysis variables such as the response variable, lsales, and the predictor variables, lprice, lndi, and lpimin. The PLOTS=RESIDUAL option in the PROC SSM statement produces residual diagnostic plots. The optional ID statement specifies
a numeric index variable (often a SAS date or datetime variable), which is year in this case. The INTERVAL=YEAR option in the ID statement indicates that the measurements are collected on a yearly basis.
The next few statements define a 46-dimensional array of dummy variables, RegionArray, such that RegionArray[i] is 1 if region is ![]() and is 0 otherwise. The next three statements, TREND, IRREGULAR, and MODEL, constitute the model specification part of the
program:
and is 0 otherwise. The next three statements, TREND, IRREGULAR, and MODEL, constitute the model specification part of the
program:
-
trend IrwTrend(ll) cross(matchparm)=(RegionArray) levelvar=0;defines a trend, namedIrwTrend, of local linear type (which is signified by the keyword ll used within the parenthesis after the name). A local linear trend—a trend with time-varying level and time-varying slope—depends on two parameters: the disturbance variance of the level equation and the disturbance variance of the slope equation (see the section Local Linear Trend for more information). The LEVELVAR=0 specification fixes the disturbance variance of the level equation to 0, which results in a trend model called an integrated random walk (IRW). An IRW model tends to produce a smoother trend than a general local linear trend. In the limiting case, if the disturbance variance of the slope equation is also 0, the IRW trend reduces to a straight line (with a fixed intercept and slope). In addition, because of the use of the 46-dimensional array,RegionArray, in the CROSS= option (cross(matchparm)=(RegionArray)), this trend specification amounts to fitting a separate IRW trend for each region. This is because, as a result of the CROSS= option,IrwTrendis treated as a linear combination of 46 (the number of variables inRegionArray) stochastically independent, integrated random walks,![\[ \text {IrwTrend}_{t} = \sum _{i=1}^{46} \text {RegionArray}[i] \; \pmb {\mu }_{i,t} \]](images/etsug_ssm0006.png)
where each
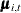 is an integrated random walk. Note that since
is an integrated random walk. Note that since RegionArray[i]is a binary variable,IrwTrendequals when regionis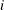 . Lastly, the use of MATCHPARM option specifies that the different IRW trends use the same disturbance variance parameter for their slope equation. This is done mainly for parsimony. Based on the model
diagnostics shown later, this appears to be a reasonable model simplification.
. Lastly, the use of MATCHPARM option specifies that the different IRW trends use the same disturbance variance parameter for their slope equation. This is done mainly for parsimony. Based on the model
diagnostics shown later, this appears to be a reasonable model simplification.
-
irregular wn;defines the observation noise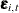 , named
, named wn, as a sequence of independent, identically distributed, zero-mean, Gaussian variables—a white noise sequence. -
model lsales = lprice lndi lpimin IrwTrend wn;defines the model forlsalesas a sum of regression effects that involvelprice,lndi, andlpimin, a trend term,IrwTrend, and the observation noisewn.
The last two statements, EVAL and OUTPUT, control certain aspects of the procedure output. The following EVAL statement defines
a linear combination, named TrendPlusReg, of selected terms in the MODEL statement.
eval TrendPlusReg = IrwTrend + lprice + lndi + lpimin;
This EVAL statement causes the SSM procedure to produce an estimate of TrendPlusReg (and its standard error), which can then be printed or output to a data set. TrendPlusReg contains all the terms in the model except for the observation noise and thus can be regarded as the explanatory part of the model. In the OUTPUT statement, you can specify an output data set that stores all the component estimates that
are produced by the procedure. The following OUTPUT statement specifies forCigar as the output data set:
output out=forCigar pdv;
The PDV option causes variables such as region1–region46, which are defined by the DATA step statements within the SSM procedure, also to be included in the output data set.
All the models that are specified in the SSM procedure possess a state space representation. See the section State Space Model and Notation for more information. The SSM procedure output begins with a table (not shown here) of the input data set that provides the name and other information. Next, the “Model Summary” table, shown in Figure 27.1, provides basic model information, such as the following:
-
the dimension of the underlying state equation, 92 (because each of the 46 IRW trends
contributes two elements to the state)
-
the diffuse dimension of the model, 95 (which is equal to the three regressors plus the 92 diffuse initial states of
)
-
the number of model parameters, 2 (which is the common disturbance variance of the slope equation in
IrwTrendand the variance of the noise termwn)
This information is very useful in determining the computational complexity of the model (the larger state size, 92, explains the relatively long computing time—as much as two minutes on some desktops—for this example).
Figure 27.1: Summary of the Underlying State Space Model
| Model Summary | |
|---|---|
| Model Property | Value |
| Number of Model Equations | 1 |
| State Dimension | 92 |
| Dimension of the Diffuse Initial Condition | 95 |
| Number of Parameters | 2 |
The index variable information is shown in Figure 27.2. Among other things, it categorizes the data to be of the type Regular with Replication, which implies that the data are regularly spaced with respect to the ID variable and at least some observations have the
same ID value. This is clearly true in this example: the data are yearly without any gaps, and there are 46 observations in
each year—one per region.
Figure 27.2: Index Variable Information
| ID Variable Information | ||||
|---|---|---|---|---|
| Name | Start | End | Max Delta | Type |
| year | 1963 | 1992 | 1 | Regular with Replication |
Figure 27.3 provides simple summary information about the response variable. It shows that lsales has no missing values and no induced missing values because the predictors in the model, lprice, lndi, and lpimin, do not have any missing values either.
Figure 27.3: Response Variable Summary
| Response Variable Information | |||||||
|---|---|---|---|---|---|---|---|
| Name | Number of Observations | Minimum | Maximum | Mean | Std Deviation | ||
| Total | Missing | Induced Missing | |||||
| lsales | 1380 | 0 | 0 | 3.98 | 5.7 | 4.79 | 0.225 |
The regression coefficients of lprice, lndi, and lpimin are shown in Figure 27.4. As expected, the coefficient of lprice is negative and the coefficients of lndi and lpimin are positive, all being statistically significant. This is consistent with the expectation that the cigarette sales are adversely
affected by the price and are positively correlated with the disposable income. The estimated effect of lpimin, called bootlegging effect by Baltagi and Levin (1992), is statistically significant but much smaller than the effects of
lprice and lndi.
Figure 27.4: Estimated Regression Coefficients
| Regression Parameter Estimates | |||||
|---|---|---|---|---|---|
| Response Variable | Regression Variable |
Estimate | Standard Error | t Value | Pr > |t| |
| lsales | lprice | -0.3480 | 0.0232 | -15.01 | <.0001 |
| lsales | lndi | 0.1425 | 0.0344 | 4.15 | <.0001 |
| lsales | lpimin | 0.0619 | 0.0269 | 2.30 | 0.0214 |
Figure 27.5: Estimated Model Parameters
| Model Parameter Estimates | ||||
|---|---|---|---|---|
| Component | Type | Parameter | Estimate | Standard Error |
| IrwTrend | LL Trend | Slope Variance | 0.000169 | 0.0000219 |
| wn | Irregular | Variance | 0.000592 | 0.0000342 |
Figure 27.5 shows the estimates of the disturbance variance of the slope equation in IrwTrend and the variance of the noise term wn. The estimate of the disturbance variance of the slope equation in IrwTrend, 0.00017, is statistically significant (being several times larger than its standard error, 0.000022). This implies that
the estimated trends ![]() are not simple lines with fixed intercept and slope.
are not simple lines with fixed intercept and slope.
Figure 27.6 shows a panel of residual normality diagnostic plots. These plots show that the residuals are symmetrically distributed but contain slightly larger than expected number of extreme residuals. Figure 27.7 shows the plot of residuals versus time. There the residuals do not exhibit any obvious pattern; however, the plot does show that more extreme residuals appear before 1970 and after 1989. On the whole, however, these plots do not exhibit serious violations of model assumptions.
Figure 27.6: Residual Normality Check
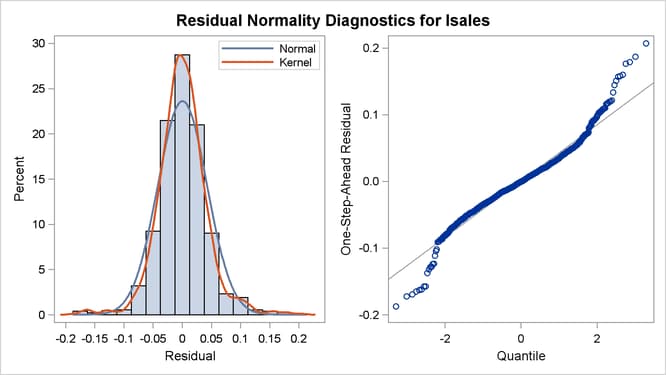
Figure 27.7: Standardized Residuals Plotted against Time
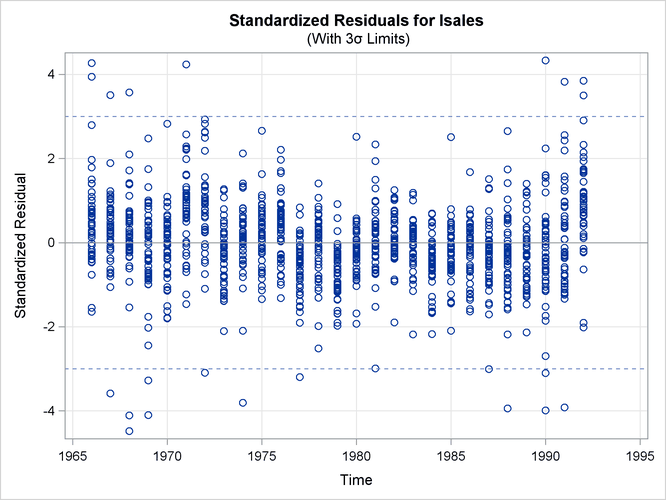
Figure 27.8 shows the details of the likelihood computations such as the number of nonmissing response values used and the likelihood of the fitted model. See the section Likelihood Computation and Model Fitting Phase for more information. Figure 27.8 shows the likelihood-based information criteria in smaller-is-better format, which are useful for model comparison.
Figure 27.8: Likelihood Computation Details
| Likelihood Computation Summary | |
|---|---|
| Statistic | Value |
| Nonmissing Response Values Used | 1380 |
| Estimated Parameters | 2 |
| Initialized Diffuse State Elements | 95 |
| Normalized Residual Sum of Squares | 1285 |
| Full Log Likelihood | 2246.05 |
Figure 27.9: Information Criteria
| Likelihood Based Information Criteria | |
|---|---|
| Statistic | Value |
| AIC (smaller is better) | -4488.1 |
| BIC (smaller is better) | -4477.8 |
| AICC (smaller is better) | -4488.1 |
| HQIC (smaller is better) | -4484.2 |
| CAIC (smaller is better) | -4475.8 |
In addition to the regression estimates, it is useful to analyze the estimates of different model components such as the
trend component IrwTrend and the linear combination TrendPlusReg. These estimates can be printed by using the PRINT= option provided in the TREND and EVAL statements, or they can be output
to a data set (as it is done in this illustration). This latter option is particularly useful for graphical exploration of
these components by standard graphical procedures such as SGPLOT and SGPANEL procedures. The following statements produce
a panel of plots that shows how well the proposed model fits the observed cigarette sales in the first three regions, which
correspond to Alabama, Arizona, and Arkansas. The output data set, forCigar, contains all the needed information: Smoothed_TrendPlusReg contains the smoothed (full-sample) estimate of TrendPlusReg, and Smoothed_Lower_TrendPlusReg and Smoothed_Upper_TrendPlusReg contain its 95% lower and upper confidence limits. In addition, for easy readability, a user-defined format (RegionFormat), which is created by using the FORMAT procedure (not shown), is used to associate the region names to region values.
proc sgpanel data=forCigar noautolegend; where region <= 3; format region RegionFormat.; title 'Region-Specific Sales Patterns with 95% Confidence Band'; panelby region / columns=3; band x=year lower=Smoothed_Lower_TrendPlusReg upper=Smoothed_Upper_TrendPlusReg; scatter x=year y=lsales; series x=year y= Smoothed_TrendPlusReg; run;
Figure 27.10: Cigarette Sales Patterns for the First Three Regions
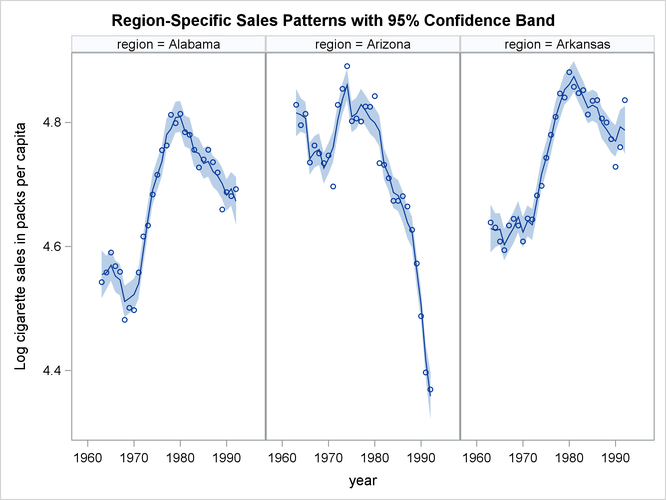
Figure 27.10 seems to indicate that the model fits the data reasonably well. It also shows that Arizona differs markedly from Alabama
and Arkansas in its cigarette sales pattern over the years. The following statements produce a similar panel of plots that
show the estimate of trend without the regression effects:
proc sgpanel data=forCigar noautolegend; where region <= 3; format region RegionFormat.; title 'Region-Specific Trend Estimates'; panelby region / columns=3; series x=year y= smoothed_IrwTrend; run;
Figure 27.11: Estimate of IrwTrend for the First Three Regions
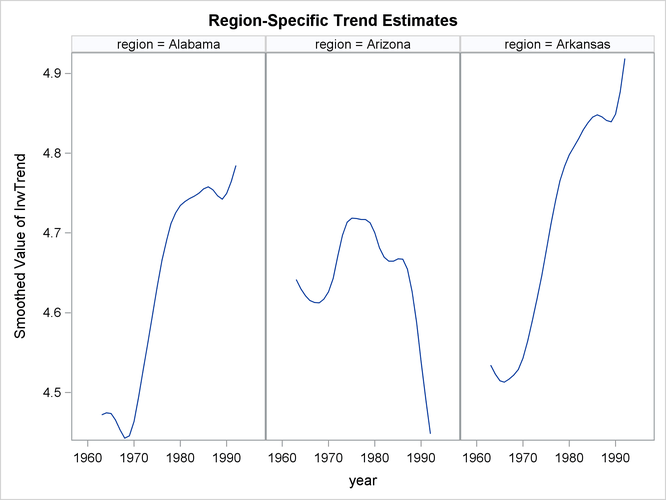
The trend patterns, shown in Figure 27.11, seem to suggest that after accounting for the regression effects, per capita cigarette sales were on the rise in Alabama
and Arkansas while they were declining in Arizona.