The QLIM Procedure
- Overview
-
Getting Started

-
Syntax
-
Details
Ordinal Discrete Choice Modeling Limited Dependent Variable Models Stochastic Frontier Production and Cost Models Heteroscedasticity and Box-Cox Transformation Bivariate Limited Dependent Variable Modeling Selection Models Multivariate Limited Dependent Models Tests on Parameters Output to SAS Data Set OUTEST= Data Set Naming ODS Table Names
-
Examples
- References
| Naming |
Naming of Parameters
When there is only one equation in the estimation, parameters are named in the same way as in other SAS procedures such as REG, PROBIT, and so on. The constant in the regression equation is called Intercept. The coefficients on independent variables are named by the independent variables. The standard deviation of the errors is called _Sigma. If there are Box-Cox transformations, the coefficients are named _Lambda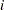 , where increments from 1, or as specified by the user. The limits for the discrete dependent variable are named _Limit. If the LIMIT=varying option is specified, then _Limit starts from 1. If the LIMIT=varying option is not specified, then _Limit
, where increments from 1, or as specified by the user. The limits for the discrete dependent variable are named _Limit. If the LIMIT=varying option is specified, then _Limit starts from 1. If the LIMIT=varying option is not specified, then _Limit is set to 0 and the limit parameters start from
is set to 0 and the limit parameters start from 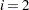 . If the HETERO statement is included, the coefficients of the independent variables in the hetero equation are called _H.
. If the HETERO statement is included, the coefficients of the independent variables in the hetero equation are called _H. , where is the name of the independent variable. If the parameter name includes interaction terms, it needs to be enclosed in quotation marks followed by
, where is the name of the independent variable. If the parameter name includes interaction terms, it needs to be enclosed in quotation marks followed by 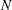 . The following example restricts the parameter that includes the interaction term to be greater than zero:
. The following example restricts the parameter that includes the interaction term to be greater than zero:
proc qlim data=a;
model y = x1|x2;
endogenous y ~ discrete;
restrict "x1*x2"N>0;
run;
When there are multiple equations in the estimation, the parameters in the main equation are named in the format of 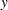 ., where is the name of the dependent variable and is the name of the independent variable. The standard deviation of the errors is called _Sigma.. The correlation of the errors is called _Rho for bivariate model. For the model with three variables it is _Rho.
., where is the name of the dependent variable and is the name of the independent variable. The standard deviation of the errors is called _Sigma.. The correlation of the errors is called _Rho for bivariate model. For the model with three variables it is _Rho.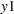 .
.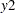 , _Rho..
, _Rho..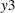 , _Rho... The construction of correlation names for multivariate models is analogous. Box-Cox parameters are called _Lambda. and limit variables are called _Limit.. Parameters in the HETERO statement are named as _H... In the OUTEST= data set, all variables are changed from ’.’ to ’_’.
, _Rho... The construction of correlation names for multivariate models is analogous. Box-Cox parameters are called _Lambda. and limit variables are called _Limit.. Parameters in the HETERO statement are named as _H... In the OUTEST= data set, all variables are changed from ’.’ to ’_’.
Naming of Output Variables
The following table shows the option in the OUTPUT statement, with the corresponding variable names and their explanation.
Option |
Name |
Explanation |
|---|---|---|
PREDICTED |
P_y |
Predicted value of |
RESIDUAL |
RESID_y |
Residual of |
XBETA |
XBETA_y |
Structure part ( |
ERRSTD |
ERRSTD_y |
Standard deviation of error term |
PROB |
PROB_y |
Probability that |
PROBALL |
PROB |
Probability that |
MILLS |
MILLS_y |
Inverse Mills ratio for |
EXPECTED |
EXPCT_y |
Unconditional expected value of |
CONDITIONAL |
CEXPCT_y |
Conditional expected value of |
MARGINAL |
MEFF_x |
Marginal effect of |
MEFF_y_x |
Marginal effect of |
|
MEFF_P |
Marginal effect of |
|
MEFF_P |
Marginal effect of |
|
TE1 |
TE1 |
Technical efficiency estimate for each producer proposed by Battese and Coelli (1988) |
TE2 |
TE2 |
Technical efficiency estimate for each producer proposed by Jondrow et al. (1982) |
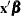 ) of
) of 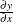 ) with single equation
) with single equation 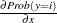 ) with single equation and discrete
) with single equation and discrete If you prefer to name the output variables differently, you can use the RENAME option in the data set. For example, the following statements rename the residual of as Resid:
proc qlim data=one;
model y = x1-x10 / censored;
output out=outds(rename=(resid_y=resid)) residual;
run;