Sample 59699: Assessing the Accuracy of Cluster Allocations Obtained from Finite Mixture Models
 |  |  |  |
Overview
Model-based clustering is one of the many uses for finite mixture models and SAS/STAT software’s FMM procedure. The finite mixture model approach to clustering assumes that the observations to be clustered are drawn from a mixture of a specified number of populations in varying proportions (McLachlan and Basford; 1988). After the finite mixture model is fit to estimate the model parameters and the posterior probabilities of population membership, each observation is assigned membership to the population for which it has the highest estimated posterior probability of belonging. As with any method of cluster analysis, the practitioner faces the problem of assessing the accuracy of the population membership allocations that are obtained, because in practice, population membership is not observed. To address this assessment problem, Basford and McLachlan (1985) propose a method of estimating the correct allocation rates for individual populations and for the overall mixture that is based on averaging appropriate functions of the maximum posterior probabilities. Because the proposed estimators for the allocation rates are known to be biased, bootstrap methods are used to estimate the bias, enabling the production of bias-adjusted estimates of the correct allocation rates. This example shows how to produce the bias-adjusted allocation rate estimates by using the FMM procedure and a little SAS programming.
The SAS output in this example is generated using SAS/STAT 12.1.
Analysis
The underlying premise of the finite mixture model approach to clustering is that the population from which the response variable of interest is sampled can be partitioned into  mutually exclusive subpopulations. It is assumed that there is a distinct probability distribution with a known parametric form associated with each subpopulation. These subpopulation probability distributions govern the distribution of values of the response variable, given that an observation originates from a particular subpopulation. Thus, the marginal distribution of the response variable is a mixture of distinct distributions. The prior probability that an observation is drawn from a particular subpopulation is equal to the proportion of the overall population that is a member of that particular subpopulation. Finite mixture models represent the marginal distribution of the response variable as a linearly weighted sum of component probability distributions:
mutually exclusive subpopulations. It is assumed that there is a distinct probability distribution with a known parametric form associated with each subpopulation. These subpopulation probability distributions govern the distribution of values of the response variable, given that an observation originates from a particular subpopulation. Thus, the marginal distribution of the response variable is a mixture of distinct distributions. The prior probability that an observation is drawn from a particular subpopulation is equal to the proportion of the overall population that is a member of that particular subpopulation. Finite mixture models represent the marginal distribution of the response variable as a linearly weighted sum of component probability distributions:

|
The component (subpopulation) distributions,  , can be discrete or continuous distributions;
, can be discrete or continuous distributions;  is a vector of parameters for the
is a vector of parameters for the  th component probability distribution. The mixing probabilities,
th component probability distribution. The mixing probabilities, 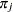 , measure the prior probabilities of component (subpopulation) membership.
, measure the prior probabilities of component (subpopulation) membership.
Given a realization of the response variable and the parameters of the component distributions, the posterior probability that the  th observation is a member of the th subpopulation is
th observation is a member of the th subpopulation is

|
Each realization is assigned membership to the subpopulation to which it has the highest posterior probability of belonging. Because 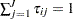 , the maximum estimated posterior probabilities have a range of
, the maximum estimated posterior probabilities have a range of  . If the maximum estimated posterior probabilities are near 1 for most of the observations in a sample, this is compelling evidence that the finite mixture model can cluster the sample with a high degree of certainty. As the maximum estimated posterior probabilities approach
. If the maximum estimated posterior probabilities are near 1 for most of the observations in a sample, this is compelling evidence that the finite mixture model can cluster the sample with a high degree of certainty. As the maximum estimated posterior probabilities approach  , this indicates that the components of the fitted mixture model are too close together for the sample to be clustered with any certainty. A visual inspection of a graph of the maximum posterior probabilities can be informative, but such assessments are necessarily subjective. It would be useful to have a summary statistic that provides an objective measure of how well the data have been clustered.
, this indicates that the components of the fitted mixture model are too close together for the sample to be clustered with any certainty. A visual inspection of a graph of the maximum posterior probabilities can be informative, but such assessments are necessarily subjective. It would be useful to have a summary statistic that provides an objective measure of how well the data have been clustered.
The correct allocation rates measure the proportion of observations that have been allocated to the correct subpopulation according to the maximum posterior probability criterion. If you could observe component (subpopulation) membership, computing the correct allocation rates would be straightforward. To do so you would create three sets of indicator variables. Denote the first set as 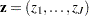 , where each
, where each  is associated with a particular subpopulation. For each observation in the sample, set
is associated with a particular subpopulation. For each observation in the sample, set  if the observation originates from the th subpopulation, and set
if the observation originates from the th subpopulation, and set  otherwise. Denote the second set as
otherwise. Denote the second set as  , where each variable similarly corresponds to a particular subpopulation. For each observation in the sample, set
, where each variable similarly corresponds to a particular subpopulation. For each observation in the sample, set  if
if  and set
and set 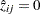 otherwise, where
otherwise, where  is the estimated posterior probability of subpopulation membership. Denote the third set as
is the estimated posterior probability of subpopulation membership. Denote the third set as  , where
, where  if
if  and
and  otherwise. The correct allocation rate for the th subpopulation is computed as
otherwise. The correct allocation rate for the th subpopulation is computed as

|
where

|
The true overall correct allocation rate for the mixture is

|
Because the correct allocation rates  and
and  depend on the unobserved indicator variables
depend on the unobserved indicator variables  , in practice they must be estimated. Ganesalingam and McLachlan (1980) propose estimating the overall correct allocation rate by
, in practice they must be estimated. Ganesalingam and McLachlan (1980) propose estimating the overall correct allocation rate by

|
Basford and McLachlan (1985) propose estimating the individual correct allocation rates by
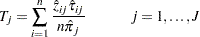
|
If the parameters  of the finite mixture model are estimated consistently, then the biases,
of the finite mixture model are estimated consistently, then the biases,  and
and  , converge in probability to 0 as
, converge in probability to 0 as  . However, results from both McLachlan and Basford (1988) and Basford and McLachlan (1985) indicate that
. However, results from both McLachlan and Basford (1988) and Basford and McLachlan (1985) indicate that  and
and  tend to overestimate the correct allocation rates in finite samples, and so some method of bias correction is recommended. Basford and McLachlan (1985) propose using the parametric bootstrap method to estimate the bias in order to produce bias-adjusted estimates of the correct allocation rates. The parametric bootstrap method works because, although you cannot observe the subpopulation of origin in the original sample, you can observe the subpopulation of origin in the bootstrap samples. This makes it possible to compute the overall correct allocation rate and the subpopulation correct allocation rates for each bootstrap sample. You can then estimate the bias by taking the average of the differences
tend to overestimate the correct allocation rates in finite samples, and so some method of bias correction is recommended. Basford and McLachlan (1985) propose using the parametric bootstrap method to estimate the bias in order to produce bias-adjusted estimates of the correct allocation rates. The parametric bootstrap method works because, although you cannot observe the subpopulation of origin in the original sample, you can observe the subpopulation of origin in the bootstrap samples. This makes it possible to compute the overall correct allocation rate and the subpopulation correct allocation rates for each bootstrap sample. You can then estimate the bias by taking the average of the differences  and
and  over the bootstrap samples.
over the bootstrap samples.
Conceptually, there are five steps in the process of computing the bias-adjusted estimates of the correct allocation rates by using the parametric bootstrap method:
-
Generate
 parametric bootstrap samples. To do this, generate replicates of the original data set. For each observation in the data sets, generate a pseudorandom variable that takes the values
parametric bootstrap samples. To do this, generate replicates of the original data set. For each observation in the data sets, generate a pseudorandom variable that takes the values  with probabilities
with probabilities  . Replace the response variable observations with a pseudorandom variable that has a mixture distribution equivalent to that of the finite mixture model that was fitted by using the original data.
. Replace the response variable observations with a pseudorandom variable that has a mixture distribution equivalent to that of the finite mixture model that was fitted by using the original data. -
Fit a finite mixture model to each of the
bootstrap samples by using the model specification that was applied to the original sample, and compute the posterior probabilities of component membership. -
Compute
, , , and for each of the bootstrap samples. -
Estimate the bias of
and the standard error of the bias estimate as 
Then estimate the bias of each
and the standard error of the bias estimate as 
-
Compute the bias-adjusted estimate of the overall correct allocation rate as

Then compute the bias-adjusted estimates of the subpopulation correct allocation rates as

You can also compute the root mean square errors for and to use as measures of precision:

|
and

|
The ratio of the bias of an estimator to its root mean square errors can be used to indicate how serious a problem bias is for a given estimator. If the ratio 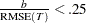 , then bias is probably not a serious problem.
, then bias is probably not a serious problem.
Example
The data used in this example are from a study by Symons, Grimson, and Yuan (1983) that investigates the incidence of sudden infant death syndrome (SIDS) and the problem of identifying the counties at high risk of SIDS in North Carolina. The data available are the number of deaths due to sudden infant death syndrome (SIDS) and the number of live births in the 100 counties of North Carolina for the years 1974–1978. The study models the number of incidences of SIDS as a mixture of two Poisson distributions, one representing a "normal" subpopulation and the other representing a "high-risk" subpopulation.
The following SAS statements create a SAS data set named NCSIDS. In addition to the original variables SIDS and Births, the variables Logrisk and Rate are created. Logrisk is the natural logarithm of the number of births, and Rate is the incidence rate.
data ncsids; input County $ 1-12 Births SIDS; Rate=SIDS/Births; Logrisk=log(Births); datalines; Alamance 4672 13 Alexander 1333 0 Alleghany 487 0 Anson 1570 15 Ashe 1091 1 Avery 781 0 Beaufort 2692 7 ... more lines ... Wayne 6638 18 Wilkes 3146 4 Wilson 3702 11 Yadkin 1269 1 Yancey 770 0 ;
The following SAS statements use the FMM procedure to fit the two-component finite mixture model. The K= option in the MODEL statement specifies that two component distributions be fit. The DIST= option specifies that the two distributions be Poisson, and the OFFSET= option specifies that the variable Logrisk be used as an offset. The CLASS option in the OUTPUT statement adds the estimated component membership to the OUTPUT data set in a variable that is named Class by default. The MAXPOST options adds the maximum posterior probability to the output data set in a variable that is named Maxpost by default. The ODS OUTPUT statement saves the "Parameter Estimates," "Number of Observations," and "Mixing Probabilities" tables to SAS data sets.
proc fmm data=ncsids;
model SIDS = / dist=poisson k=2 offset=Logrisk;
output out=model class maxpost prior;
ods output ParameterEstimates=Parameters
NObs=NObs(where=(label="Number of Observations Used") keep=label N)
MixingProbs=MixingProbs(keep=prob);
run;
Output 1 displays selected portions of the FMM procedure’s output. In the Inverse Linked Estimates column of the "Parameter Estimates" table, you can see that the mean for the component 1 Poisson distribution is 0.001693 and the mean for the component 2 Poisson distribution is 0.003805. Thus, component 1 represents the "normal-risk" subpopulation and component 2 represents the "high-risk" subpopulation. You can also see from the "Mixing Probabilities" table that the prior probability for component 1 is 0.7969; the prior probability for component 2 can be inferred from the fact that the sum of the prior probabilities equals 1.
Output 1 Two Component Finite Mixture Model of SIDS Data The FMM Procedure
| Parameter Estimates for 'Poisson' Model | ||||||
|---|---|---|---|---|---|---|
| Component | Parameter | Estimate | Standard Error | z Value | Pr > |z| | Inverse Linked Estimate |
| 1 | Intercept | -6.3813 | 0.08812 | -72.42 | <.0001 | 0.001693 |
| 2 | Intercept | -5.5715 | 0.2288 | -24.35 | <.0001 | 0.003805 |
| Parameter Estimates for Mixing Probabilities | |||||
|---|---|---|---|---|---|
| Parameter | Linked Scale | Probability | |||
| Estimate | Standard Error | z Value | Pr > |z| | ||
| Probability | 1.3669 | 0.8024 | 1.70 | 0.0885 | 0.7969 |
| Fit Statistics | |
|---|---|
| -2 Log Likelihood | 474.3 |
| AIC (smaller is better) | 480.3 |
| AICC (smaller is better) | 480.5 |
| BIC (smaller is better) | 488.1 |
| Pearson Statistic | 113.3 |
| Effective Parameters | 3 |
| Effective Components | 2 |
| Parameter Estimates for 'Poisson' Model | ||||||
|---|---|---|---|---|---|---|
| Component | Parameter | Estimate | Standard Error | z Value | Pr > |z| | Inverse Linked Estimate |
| 1 | Intercept | -6.3813 | 0.08812 | -72.42 | <.0001 | 0.001693 |
| 2 | Intercept | -5.5715 | 0.2288 | -24.35 | <.0001 | 0.003805 |
| Parameter Estimates for Mixing Probabilities | |||||
|---|---|---|---|---|---|
| Parameter | Linked Scale | Probability | |||
| Estimate | Standard Error | z Value | Pr > |z| | ||
| Probability | 1.3669 | 0.8024 | 1.70 | 0.0885 | 0.7969 |
Figure 1 is a plot of the ordered incidence rates, with color-coded markers to indicate whether a county is classified by the finite mixture model as normal risk or high risk. The plot reveals that, with a couple of exceptions, the counties with the highest rates tend to be classified as high risk by the finite mixture model.
Figure 1 Ordered Incidence Rates

You can generate plots of the maximum posterior probabilities to visually assess how accurately the finite mixture model can cluster the data. For example, the following SAS statements generate a plot of the ordered maximum posterior probabilities and a plot of the maximum posterior probabilities versus the incidence rates:
proc rank data=model out=model descending; var maxpost; ranks postorder; run;
title "Ordered Maximum Posterior Probabilities";
proc sgplot data=model;
scatter y=maxpost x=postorder / markerattrs=(symbol=CircleFilled size=4px)
group=class;
run;
title;
title "Maximum Posterior Probabilities by Incidence Rates";
proc sgplot data=model;
scatter y=maxpost x=rate / markerattrs=(symbol=CircleFilled size=4px)
group=class;
run;
title;
The plot on the left in Figure 2 shows that about half the counties have relatively large (> 0.9) maximum posterior probabilities, indicating that they can be classified with a high degree of certainty. The maximum posterior probabilities then decline at an accelerating rate, indicating a deteriorating degree of certainty about the correct allocation. The counties that are classified as high risk appear to account for a disproportionate share of those with relatively low (< 0.7) maximum posterior probabilities. The plot on the right shows that counties with incidence rates between approximately 0.0026 and 0.005 tend to have the highest degree of uncertainty about the correct allocation.
Figure 2 Maximum Posterior Probabilities|
Ordered Maximum Posterior Probabilities |
Maximum Posterior Probabilities by Incidence Rates |
|
|
|


You can compute the estimated correct allocation rates T, T1, and T2 as follows by using the data that are saved in the output data sets Model, Nobs, and MixingProbs. The results are saved in the data set ModelPost.
proc sort data=model out=model;
by Class;
run;
proc means data=model sum;
by Class;
var Maxpost;
output out=ModelPost(drop=_TYPE_ _FREQ_)
sum(Maxpost)=Maxpost;
run;
proc transpose data=ModelPost prefix=MaxPost
out=ModelPost(drop=_LABEL_ _NAME_);
var Maxpost;
id Class;
run;
data ModelPost;
merge ModelPost NObs(drop=label) MixingProbs;
T=(MaxPost1 + MaxPost2)/N;
T1=MaxPost1/(N*Prob);
T2=MaxPost2/(N*(1-Prob));
label T=Estimated Overall Correct Allocation Rate
T1=Estimated Component 1 Correct Allocation Rate
T2=Estimated Component 2 Correct Allocation Rate;
run;
proc print data=ModelPost noobs label; var T T1 T2; run;
Output 2 shows the estimated correct allocation rates. The estimate of the overall rate is .88, the rate for the normal-risk subpopulation is .96, and the rate for the high-risk subpopulation is .59.
Even though these estimated allocation rates might be biased, they indicate that the finite mixture model can correctly classify observations from the normal-risk population with a high degree of accuracy, but they also indicate that the degree of accuracy is considerably lower for observations from the high-risk population. This implies that the model is much more likely to incorrectly classify a high-risk county as normal risk than to incorrectly classify a normal-risk county as high risk.
Output 2 Allocation Rates
| Estimated Overall Correct Allocation Rate |
Estimated Component 1 Correct Allocation Rate |
Estimated Component 2 Correct Allocation Rate |
|---|---|---|
| 0.88775 | 0.96290 | 0.59292 |
Computing Bias-Adjusted Correct Allocation Rates by Using the Parametric Bootstrap Method
The section Analysis describes a five-step procedure that uses the parametric bootstrap method to produce bias-adjusted correct allocation rates. The five subsections that follow describe each step in greater detail.
Step 1: Generate the Bootstrap Samples
Step 1 is to generate the bootstrap samples. One of the easiest ways to do this is to use the SURVEYSELECT procedure. If you use the METHOD=SRS option, SAMPRATE=1 option, and REPS=200 option, PROC SURVEYSELECT generates 200 exact replicates of the original data set. The procedure automatically generates a variable named Replicate that indexes the samples. Using the SEED option ensures reproducibility. The OUTPUT option saves the 200 bootstrap samples in a data set named Bootstrap.
proc surveyselect data=model(keep=county sids logrisk)
out=bootstrap
seed=872398
method=srs
samprate=1
rep=200;
run;
Next, you retrieve the estimated Poisson parameters and the first component mixing probability from the output data sets Parameters and MixingProbs and store those values in macro variables for later use.
data parameters;
set parameters;
if component=1 then call symput('theta1',estimate);
if component=2 then call symput('theta2',estimate);
run;
data MixingProbs;
set MixingProbs;
call symput('pi1',prob);
run;
Then, you generate the pseudorandom variable Group, which takes on the value 1 or 2 with the probability  or
or  , respectively. Also, you replace the response variable SIDS with the pseudorandom numbers that have a distribution equivalent to the estimated finite mixture model. Then, to prepare the data set Bootstrap for BY-group processing, you sort it by Replicate.
, respectively. Also, you replace the response variable SIDS with the pseudorandom numbers that have a distribution equivalent to the estimated finite mixture model. Then, to prepare the data set Bootstrap for BY-group processing, you sort it by Replicate.
data bootstrap;
set bootstrap;
call streaminit(987346598);
Group=rand('TABLE',&pi1);
mu1=exp(&theta1+logrisk);
mu2=exp(&theta2+logrisk);
SIDS=ifn(group=1,rand('POISSON',mu1),rand('POISSON',mu2));
run;
proc sort data=bootstrap out=bootstrap; by Replicate; run;
Step 2: Fit a Finite Mixture Model to Each Bootstrap Sample
Step 2 is to use PROC FMM with the original finite mixture model specification and BY-group processing to fit a finite mixture model to each of the 200 bootstrap samples. In an OUTPUT statement, you specify the OUT=, CLASS, MAXPOST, and PRIOR options. The ODS OUTPUT statement saves the parameter estimates for each bootstrap sample in the data set BootParameters and saves the model convergence status in the data set Converge. These two data sets and the output data set ML will be merged so that you can perform some recommended filtering of the output data set ML.
ods select none;
proc fmm data=bootstrap;
by Replicate;
model SIDS = / dist=poisson k=2 offset=Logrisk;
output out=ml class maxpost prior;
ods output ParameterEstimates=BootParameters(keep=replicate component estimate)
ConvergenceStatus=Converge(keep=replicate status);
run;
Before you perform any analysis, it is recommended that you perform two filtering operations on the output data set ML. The first filtering operation concerns the convergence status of the models that have been fit to each bootstrap sample. Before you accept the estimates, you should check the convergence status of each model and discard any estimates that were generated by a model that failed to converge. The data set Converge contains a variable named Status that has a value of 0 if the model converged and a nonzero value if the model fails to converge.
The second filtering operation requires a slightly more elaborate explanation. Output 1 shows that PROC FMM names the two component distributions component 1 and component 2. Because the parameter estimate for component 1 is smaller than the estimate for component 2, component 1 is referred to as the normal-risk component and component 2 is referred to as the high-risk component. Thus, when the variable Class has a value of 1, it is interpreted to mean that a particular observation has been assigned to the normal-risk subpopulation; when Class has a value of 2, it is interpreted to mean that a particular observation has been assigned to the high-risk subpopulation. However, this naming of the components by PROC FMM is completely arbitrary. If you fit the same model to a different sample, there is no guarantee that component 1 will be associated with the smaller parameter estimate and thus represent the normal-risk component. This means that when the variable Class has a value of 1, it cannot necessarily be interpreted to mean that the observation has been assigned to the normal-risk subpopulation. To ensure that the classifications have the same interpretations across the bootstrap samples, you must ensure that the magnitudes of the parameter estimates are in the same order. When they are not in the same order, you must switch the values of the variable Class and the values of the prior probabilities that are stored in the output data set ML.
To switch these values, you first transpose the data set BootParameters and sort it by Replicate. Then you sort the data set Converge by Replicate and merge BootParameters and Converge with ML.
proc transpose data=BootParameters
out=BootParameters(drop=_NAME_)
prefix=Estimate;
by Replicate;
id Component;
run;
proc sort data=BootParameters out=BootParameters;
by Replicate;
run;
proc sort data=Converge;
by Replicate;
run;
data ml; merge ml BootParameters Converge; by Replicate; run;
Next, you can perform a DATA step and use a WHERE clause to exclude all observations where Status is nonzero. Then, you create a set of variables that are duplicates of the variables that contain the parameter estimates, the prior probabilities, and the variable Class. Finally, you perform a conditional (IF-THEN-DO) operation based on the relative magnitudes of the parameter estimates and switch the values in the original variables as needed. The parameter estimates are stored in the variables Estimate1 and Estimate2, and the prior probabilities are stored in the variables Prior_1 and Prior_2.
data ml(drop=Prior1 Prior2 Lambda1 Lambda2 Class2 Status);
set ml(where=(Status=0));
Prior1=Prior_1;
Prior2=Prior_2;
Post1=Post_1;
Post2=Post_2;
Lambda1=Estimate1;
Lambda2=Estimate2;
Class2=Class;
if Estimate1>Estimate2 then do;
Prior_1=Prior2;
Prior_2=Prior1;
if Class2=1 then Class=2;
if Class2=2 then Class=1;
end;
run;
Step 3: Compute the True Correct Allocation Rates and the Estimated Correct Allocation Rates for Each Bootstrap Sample
Step 3 is to compute the true correct allocation rates ,  , and
, and  and the estimated correct allocation rates ,
and the estimated correct allocation rates , 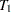 , and
, and  for the 200 bootstrap samples.
for the 200 bootstrap samples.
The following SAS statements compute the true correct allocation rates , , and for the bootstrap samples and save the results in a data set named Allocation:
data ml; set ml; z1=ifn(Group=1,1,0); zhat1=ifn(Class=1,1,0); d1=ifn(z1=zhat1,1,0); z2=ifn(Group=2,1,0); zhat2=ifn(Class=2,1,0); d2=ifn(z2=zhat2,1,0); A1=z1*d1; A2=z2*d2; run;
proc sort data=ml out=ml;
by Replicate Class;
run;
proc means data=ml(keep= replicate A1 A2 z1 z2) sum;
by Replicate;
var A1 A2 z1 z2;
output out=allocation(drop=_TYPE_ _FREQ_)
sum(A1)=A1
sum(A2)=A2
sum(z1)=n1
sum(z2)=n2;
run;
data allocation; set allocation; A1=A1/n1; A2=A2/n2; n=n1+n2; A=(n1*A1 + n2*A2)/n; run;
The next group of SAS statements computes the estimated correct allocation rates , , and for the bootstrap samples and saves the results to the same data set, Allocation:
proc means data=ml sum;
by Replicate Class;
var maxpost;
output out=PostSums(drop=_TYPE_ _FREQ_)
sum(maxpost)=Maxpost;
run;
proc transpose data=PostSums prefix=SumMaxPost
out=PostSums(drop=_LABEL_ _NAME_);
var Maxpost;
by Replicate;
id Class;
run;
proc sort data=allocation out=allocation;
by Replicate;
run;
proc sort data=PostSums out=PostSums;
by Replicate;
run;
data prior; set ml(keep=Replicate Prior_1 Prior_2); by Replicate; if First.Replicate; run;
proc sort data=prior out=prior; by Replicate; run;
data allocation; merge allocation PostSums prior; by Replicate; run; data allocation; set allocation; T=(SumMaxPost1 + SumMaxPost2)/n; T1=SumMaxPost1/(n*Prior_1); T2=SumMaxPost2/(n*Prior_2); run;
Step 4: Estimate the Biases of the Correct Allocation Rate Estimators
Step 4 is to compute the biases  ,
,  , and
, and  , the standard errors of the bias estimates
, the standard errors of the bias estimates  ,
,  , and
, and  , and the root mean square errors
, and the root mean square errors  ,
,  , and
, and  . The following SAS statements accomplish this task and save the results in the data set Bias:
. The following SAS statements accomplish this task and save the results in the data set Bias:
data allocation; set allocation; B=T-A; Bsqr=B**2; B1=T1-A1; B1sqr=B1**2; B2=T2-A2; B2sqr=B2**2; run;
proc means data=allocation mean;
var B B1 B2 Bsqr B1sqr B2sqr;
output out=bias
mean(B)=B
var(B)=varB
mean(B1)=B1
var(B1)=varB1
mean(B2)=B2
var(B2)=varB2
mean(Bsqr)=Bsqr
mean(B1sqr)=B1sqr
mean(B2sqr)=B2sqr
N=K;
run;
data bias; set bias; se_B=sqrt(varB/K); se_B1=sqrt(varB1/K); se_B2=sqrt(varB2/K); RMSE_T1=sqrt(B1sqr); RMSE_T2=sqrt(B2sqr); RMSE_T=sqrt(Bsqr); run;
Step 5: Compute the Bias-Adjusted Estimates of the Correct Allocation Rates
Step 5 is to compute the bias-adjusted estimates of the correct allocation rates  ,
,  , and
, and  . You do this by merging the data set Bias with the data set ModelPost, which contains the estimated correct allocation rates from the original sample, and subtracting the bias estimates , , and from the corresponding correct allocation rate estimates , , and . The results are saved in the data set BiasAdjusted.
. You do this by merging the data set Bias with the data set ModelPost, which contains the estimated correct allocation rates from the original sample, and subtracting the bias estimates , , and from the corresponding correct allocation rate estimates , , and . The results are saved in the data set BiasAdjusted.
data BiasAdjusted; merge bias(drop = _TYPE_ _FREQ_) ModelPost; BiasAdjT=T-B; BiasAdjT1=T1-B1; BiasAdjT2=T2-B2; run;
The data set BiasAdjusted holds the results, but it is not in the best form for printing. All the data are currently stored in a wide form that consists of a single vector of values. To prepare the results for printing, it is recommended that you reshape the data set to a long form; that is, you stack the data so there are separate rows for the overall population and the two subpopulations. You can do this by breaking BiasAdjusted into three data sets and then appending those three data sets together.
data T;
set BiasAdjusted(keep=T B SE_B BiasAdjT RMSE_T);
length Label $ 12;
label='Overall';
rename T=Estimate
B=Bias
SE_B=SE
BiasAdjT=Adjusted
RMSE_T=RMSE;
run;
data T1;
set BiasAdjusted(keep=T1 B1 SE_B1 BiasAdjT1 RMSE_T1);
length Label $ 12;
Label='Normal Risk';
rename T1=Estimate
B1=Bias
SE_B1=SE
BiasAdjT1=Adjusted
RMSE_T1=RMSE;
run;
data T2;
set BiasAdjusted(keep=T2 B2 SE_B2 BiasAdjT2 RMSE_T2);
length Label $ 12;
Label='High Risk';
rename T2=Estimate
B2=Bias
SE_B2=SE
BiasAdjT2=Adjusted
RMSE_T2=RMSE;
run;
proc append base=results data=T; run; proc append base=results data=T1; run; proc append base=results data=T2; run;
Next, you compute the ratios  ,
,  , and
, and  and create appropriate labels to prepare the data set Results for printing:
and create appropriate labels to prepare the data set Results for printing:
data results;
set results;
ratio=bias/rmse;
label Label=Population
Estimate=Estimated Correct Allocation Rate
Bias=Estimate of Bias
SE=Standard Error of Bias Estimate
Adjusted=Bias-Adjusted Correct Allocation Rate
RMSE=RMSE of Correct Allocation Rate
ratio=ratio of Bias to RMSE;
run;
Finally, you print the data set Results:
ods select all; proc print data=results noobs label; var Label Estimate RMSE Bias SE ratio Adjusted; title 'Estimated Correct Allocation Rates'; title2 'Parametric Bootstrap Method'; run;
Output 3 shows the results. As you can see, for this example the bias estimates are all positive but fairly small. The ratios of bias to RMSE are all below the .25 threshold, indicating that bias is not a significant issue for this model and sample.
Output 3 Parametric Bootstrap Results
| Estimated Correct Allocation Rates |
| Parametric Bootstrap Method |
| Population | Estimated Correct Allocation Rate |
RMSE of Correct Allocation Rate |
Estimate of Bias | Standard Error of Bias Estimate |
ratio of Bias to RMSE |
Bias-Adjusted Correct Allocation Rate |
|---|---|---|---|---|---|---|
| Overall | 0.88775 | 0.04590 | .004583433 | .003237460 | 0.099858 | 0.88316 |
| Normal Risk | 0.96290 | 0.01902 | .001455327 | .001344381 | 0.076513 | 0.96145 |
| High Risk | 0.59292 | 0.12715 | .003564499 | .009010140 | 0.028033 | 0.58935 |
References
-
Basford, K. E. and McLachlan, G. J. (1985), “Estimation of Allocation Rates in a Cluster Analysis Context,” Journal of the American Statistical Association, 80(390), 286–293.
-
Ganesalingam, S. and McLachlan, G. J. (1980), “Error rate estimation on the basis of posterior probabilities,” Pattern Recognition, 12, 405–413.
-
McLachlan, G. J. and Basford, K. E. (1988), Mixture Models, New York: Marcel Dekker.
-
Symons, M. J., Grimson, R. C., and Yuan, Y. C. (1983), “Clustering of Rare Events,” Biometrics, 39, 193–205.
These sample files and code examples are provided by SAS Institute Inc. "as is" without warranty of any kind, either express or implied, including but not limited to the implied warranties of merchantability and fitness for a particular purpose. Recipients acknowledge and agree that SAS Institute shall not be liable for any damages whatsoever arising out of their use of this material. In addition, SAS Institute will provide no support for the materials contained herein.
data ncsids;
input County $ 1-12 Births SIDS;
Rate=SIDS/Births;
Logrisk=log(Births);
datalines;
Alamance 4672 13
Alexander 1333 0
Alleghany 487 0
Anson 1570 15
Ashe 1091 1
Avery 781 0
Beaufort 2692 7
Bertie 1324 6
Bladen 1782 8
Brunswick 2181 5
Buncombe 7515 9
Burke 3573 5
Cabarrus 4099 3
Caldwell 3609 6
Camden 286 0
Carteret 2414 5
Caswell 1035 2
Catawba 5754 5
Chatham 1646 2
Cherokee 1027 2
Chowan 751 1
Clay 284 0
Cleveland 4866 10
Columbus 3350 15
Craven 5868 13
Cumberland 20366 38
Currituck 508 1
Dare 521 0
Davidson 5509 8
Davie 1207 1
Duplin 2483 4
Durham 7970 16
Edgecombe 3657 10
Forsyth 11858 10
Franklin 1399 2
Gaston 9014 11
Gates 420 0
Graham 415 0
Granville 1671 4
Greene 870 4
Guilford 16184 23
Halifax 3608 18
Harnett 3776 6
Haywood 2110 2
Henderson 2574 5
Hertford 1452 7
Hoke 1494 7
Hyde 338 0
Iredell 4139 4
Jackson 1143 2
Johnston 3999 6
Jones 578 1
Lee 2252 5
Lenoir 3589 10
Lincoln 2216 8
McDowell 1946 5
Macon 797 0
Madison 765 2
Martin 1549 2
Mecklenburg 21588 44
Mitchell 671 0
Montgomery 1258 3
Moore 2648 5
Nash 4021 8
New Hanover 5526 12
Northampton 1421 9
Onslow 11158 29
Orange 3164 4
Pamlico 542 1
Pasquotank 1638 3
Pender 1228 4
Perquimans 484 1
Person 1556 4
Pitt 5094 14
Polk 533 1
Randolph 4456 7
Richmond 2756 4
Robeson 7889 31
Rockingham 4449 16
Rowan 4606 3
Rutherford 2992 12
Sampson 3025 4
Scotland 2255 8
Stanly 2356 5
Stokes 1612 1
Surry 3188 5
Swain 675 3
Transylvania 1173 3
Tyrell 248 0
Union 3915 4
Vance 2180 4
Wake 14484 16
Warren 968 4
Washington 990 5
Watauga 1323 1
Wayne 6638 18
Wilkes 3146 4
Wilson 3702 11
Yadkin 1269 1
Yancey 770 0
;
proc fmm data=ncsids;
model SIDS = / dist=poisson k=2 offset=Logrisk;
output out=model class maxpost prior;
ods output ParameterEstimates=Parameters
NObs=NObs(where=(label="Number of Observations Used") keep=label N)
MixingProbs=MixingProbs(keep=prob);
run;
proc rank data=model out=model descending;
var rate;
ranks order;
run;
proc format;
value group 1 = 'Normal'
2 = 'High';
run;
proc sgplot data=model;
title "Ordered Incidence Rates";
format class group.;
scatter x=order y=rate /
markerattrs=(symbol=CircleFilled size=4px)
group=class;
yaxis values=(.001 .002 .003 .004 .005 .006 .007 .008 .009 .01);
run;
proc rank data=model out=model descending;
var maxpost;
ranks postorder;
run;
title "Ordered Maximum Posterior Probabilities";
proc sgplot data=model;
scatter y=maxpost x=postorder / markerattrs=(symbol=CircleFilled size=4px)
group=class;
run;
title;
title "Maximum Posterior Probabilities by Incidence Rates";
proc sgplot data=model;
scatter y=maxpost x=rate / markerattrs=(symbol=CircleFilled size=4px)
group=class;
run;
title;
proc sort data=model out=model;
by Class;
run;
proc means data=model sum;
by Class;
var Maxpost;
output out=ModelPost(drop=_TYPE_ _FREQ_)
sum(Maxpost)=Maxpost;
run;
proc transpose data=ModelPost prefix=MaxPost
out=ModelPost(drop=_LABEL_ _NAME_);
var Maxpost;
id Class;
run;
data ModelPost;
merge ModelPost NObs(drop=label) MixingProbs;
T=(MaxPost1 + MaxPost2)/N;
T1=MaxPost1/(N*Prob);
T2=MaxPost2/(N*(1-Prob));
label T=Estimated Overall Correct Allocation Rate
T1=Estimated Component 1 Correct Allocation Rate
T2=Estimated Component 2 Correct Allocation Rate;
run;
proc print data=ModelPost noobs label;
var T T1 T2;
run;
proc surveyselect data=model(keep=county sids logrisk)
out=bootstrap
seed=872398
method=srs
samprate=1
rep=200;
run;
data parameters;
set parameters;
if component=1 then call symput('theta1',estimate);
if component=2 then call symput('theta2',estimate);
run;
data MixingProbs;
set MixingProbs;
call symput('pi1',prob);
run;
data bootstrap;
set bootstrap;
call streaminit(987346598);
Group=rand('TABLE',&pi1);
mu1=exp(&theta1+logrisk);
mu2=exp(&theta2+logrisk);
SIDS=ifn(group=1,rand('POISSON',mu1),rand('POISSON',mu2));
run;
proc sort data=bootstrap out=bootstrap;
by Replicate;
run;
ods select none;
proc fmm data=bootstrap;
by Replicate;
model SIDS = / dist=poisson k=2 offset=Logrisk;
output out=ml class maxpost prior;
ods output ParameterEstimates=BootParameters(keep=replicate component estimate)
ConvergenceStatus=Converge(keep=replicate status);
run;
proc transpose data=BootParameters
out=BootParameters(drop=_NAME_)
prefix=Estimate;
by Replicate;
id Component;
run;
proc sort data=BootParameters out=BootParameters;
by Replicate;
run;
proc sort data=Converge;
by Replicate;
run;
data ml;
merge ml BootParameters Converge;
by Replicate;
run;
data ml(drop=Prior1 Prior2 Lambda1 Lambda2 Class2 Status);
set ml(where=(Status=0));
Prior1=Prior_1;
Prior2=Prior_2;
Post1=Post_1;
Post2=Post_2;
Lambda1=Estimate1;
Lambda2=Estimate2;
Class2=Class;
if Estimate1>Estimate2 then do;
Prior_1=Prior2;
Prior_2=Prior1;
if Class2=1 then Class=2;
if Class2=2 then Class=1;
end;
run;
data ml;
set ml;
z1=ifn(Group=1,1,0);
zhat1=ifn(Class=1,1,0);
d1=ifn(z1=zhat1,1,0);
z2=ifn(Group=2,1,0);
zhat2=ifn(Class=2,1,0);
d2=ifn(z2=zhat2,1,0);
A1=z1*d1;
A2=z2*d2;
run;
proc sort data=ml out=ml;
by Replicate Class;
run;
proc means data=ml(keep= replicate A1 A2 z1 z2) sum;
by Replicate;
var A1 A2 z1 z2;
output out=allocation(drop=_TYPE_ _FREQ_)
sum(A1)=A1
sum(A2)=A2
sum(z1)=n1
sum(z2)=n2;
run;
data allocation;
set allocation;
A1=A1/n1;
A2=A2/n2;
n=n1+n2;
A=(n1*A1 + n2*A2)/n;
run;
proc means data=ml sum;
by Replicate Class;
var maxpost;
output out=PostSums(drop=_TYPE_ _FREQ_)
sum(maxpost)=Maxpost;
run;
proc transpose data=PostSums prefix=SumMaxPost
out=PostSums(drop=_LABEL_ _NAME_);
var Maxpost;
by Replicate;
id Class;
run;
proc sort data=allocation out=allocation;
by Replicate;
run;
proc sort data=PostSums out=PostSums;
by Replicate;
run;
data prior;
set ml(keep=Replicate Prior_1 Prior_2);
by Replicate;
if First.Replicate;
run;
proc sort data=prior out=prior;
by Replicate;
run;
data allocation;
merge allocation PostSums prior;
by Replicate;
run;
data allocation;
set allocation;
T=(SumMaxPost1 + SumMaxPost2)/n;
T1=SumMaxPost1/(n*Prior_1);
T2=SumMaxPost2/(n*Prior_2);
run;
data allocation;
set allocation;
B=T-A;
Bsqr=B**2;
B1=T1-A1;
B1sqr=B1**2;
B2=T2-A2;
B2sqr=B2**2;
run;
proc means data=allocation mean;
var B B1 B2 Bsqr B1sqr B2sqr;
output out=bias
mean(B)=B
var(B)=varB
mean(B1)=B1
var(B1)=varB1
mean(B2)=B2
var(B2)=varB2
mean(Bsqr)=Bsqr
mean(B1sqr)=B1sqr
mean(B2sqr)=B2sqr
N=K;
run;
data bias;
set bias;
se_B=sqrt(varB/K);
se_B1=sqrt(varB1/K);
se_B2=sqrt(varB2/K);
RMSE_T1=sqrt(B1sqr);
RMSE_T2=sqrt(B2sqr);
RMSE_T=sqrt(Bsqr);
run;
data BiasAdjusted;
merge bias(drop = _TYPE_ _FREQ_) ModelPost;
BiasAdjT=T-B;
BiasAdjT1=T1-B1;
BiasAdjT2=T2-B2;
run;
data T;
set BiasAdjusted(keep=T B SE_B BiasAdjT RMSE_T);
length Label $ 12;
label='Overall';
rename T=Estimate
B=Bias
SE_B=SE
BiasAdjT=Adjusted
RMSE_T=RMSE;
run;
data T1;
set BiasAdjusted(keep=T1 B1 SE_B1 BiasAdjT1 RMSE_T1);
length Label $ 12;
Label='Normal Risk';
rename T1=Estimate
B1=Bias
SE_B1=SE
BiasAdjT1=Adjusted
RMSE_T1=RMSE;
run;
data T2;
set BiasAdjusted(keep=T2 B2 SE_B2 BiasAdjT2 RMSE_T2);
length Label $ 12;
Label='High Risk';
rename T2=Estimate
B2=Bias
SE_B2=SE
BiasAdjT2=Adjusted
RMSE_T2=RMSE;
run;
proc datasets;
delete results;
run;
proc append base=results data=T;
run;
proc append base=results data=T1;
run;
proc append base=results data=T2;
run;
data results;
set results;
ratio=bias/rmse;
label Label=Population
Estimate=Estimated Correct Allocation Rate
Bias=Estimate of Bias
SE=Standard Error of Bias Estimate
Adjusted=Bias-Adjusted Correct Allocation Rate
RMSE=RMSE of Correct Allocation Rate
ratio=ratio of Bias to RMSE;
run;
ods select all;
proc print data=results noobs label;
var Label Estimate RMSE Bias SE ratio Adjusted;
title 'Estimated Correct Allocation Rates';
title2 'Parametric Bootstrap Method';
run;
title;
title2;
These sample files and code examples are provided by SAS Institute Inc. "as is" without warranty of any kind, either express or implied, including but not limited to the implied warranties of merchantability and fitness for a particular purpose. Recipients acknowledge and agree that SAS Institute shall not be liable for any damages whatsoever arising out of their use of this material. In addition, SAS Institute will provide no support for the materials contained herein.
| Type: | Sample |
| Topic: | SAS Reference ==> Procedures ==> FMM Analytics ==> Cluster Analysis |
| Date Modified: | 2017-01-18 09:41:27 |
| Date Created: | 2017-01-16 16:26:34 |
Operating System and Release Information
| Product Family | Product | Host | SAS Release | |
| Starting | Ending | |||
| SAS System | SAS/STAT | z/OS | ||
| z/OS 64-bit | ||||
| OpenVMS VAX | ||||
| Microsoft® Windows® for 64-Bit Itanium-based Systems | ||||
| Microsoft Windows Server 2003 Datacenter 64-bit Edition | ||||
| Microsoft Windows Server 2003 Enterprise 64-bit Edition | ||||
| Microsoft Windows XP 64-bit Edition | ||||
| Microsoft® Windows® for x64 | ||||
| OS/2 | ||||
| Microsoft Windows 8 Enterprise 32-bit | ||||
| Microsoft Windows 8 Enterprise x64 | ||||
| Microsoft Windows 8 Pro 32-bit | ||||
| Microsoft Windows 8 Pro x64 | ||||
| Microsoft Windows 8.1 Enterprise 32-bit | ||||
| Microsoft Windows 8.1 Enterprise x64 | ||||
| Microsoft Windows 8.1 Pro 32-bit | ||||
| Microsoft Windows 8.1 Pro x64 | ||||
| Microsoft Windows 10 | ||||
| Microsoft Windows 95/98 | ||||
| Microsoft Windows 2000 Advanced Server | ||||
| Microsoft Windows 2000 Datacenter Server | ||||
| Microsoft Windows 2000 Server | ||||
| Microsoft Windows 2000 Professional | ||||
| Microsoft Windows NT Workstation | ||||
| Microsoft Windows Server 2003 Datacenter Edition | ||||
| Microsoft Windows Server 2003 Enterprise Edition | ||||
| Microsoft Windows Server 2003 Standard Edition | ||||
| Microsoft Windows Server 2003 for x64 | ||||
| Microsoft Windows Server 2008 | ||||
| Microsoft Windows Server 2008 R2 | ||||
| Microsoft Windows Server 2008 for x64 | ||||
| Microsoft Windows Server 2012 Datacenter | ||||
| Microsoft Windows Server 2012 R2 Datacenter | ||||
| Microsoft Windows Server 2012 R2 Std | ||||
| Microsoft Windows Server 2012 Std | ||||
| Microsoft Windows XP Professional | ||||
| Windows 7 Enterprise 32 bit | ||||
| Windows 7 Enterprise x64 | ||||
| Windows 7 Home Premium 32 bit | ||||
| Windows 7 Home Premium x64 | ||||
| Windows 7 Professional 32 bit | ||||
| Windows 7 Professional x64 | ||||
| Windows 7 Ultimate 32 bit | ||||
| Windows 7 Ultimate x64 | ||||
| Windows Millennium Edition (Me) | ||||
| Windows Vista | ||||
| Windows Vista for x64 | ||||
| 64-bit Enabled AIX | ||||
| 64-bit Enabled HP-UX | ||||
| 64-bit Enabled Solaris | ||||
| ABI+ for Intel Architecture | ||||
| AIX | ||||
| HP-UX | ||||
| HP-UX IPF | ||||
| IRIX | ||||
| Linux | ||||
| Linux for x64 | ||||
| Linux on Itanium | ||||
| OpenVMS Alpha | ||||
| OpenVMS on HP Integrity | ||||
| Solaris | ||||
| Solaris for x64 | ||||
| Tru64 UNIX | ||||