DataFlux Data Management Studio 2.6: User Guide
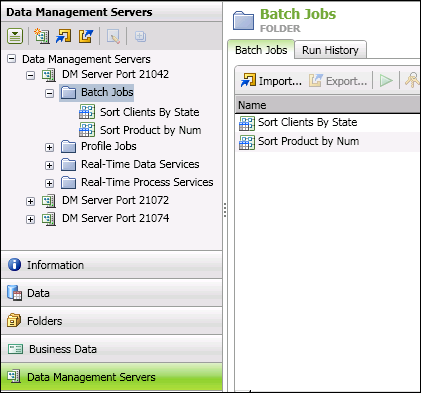
DataFlux Data Management Servers provide a scalable server environment for your jobs, profiles, and real-time services. After you upload your jobs and real-time services to the server, authorized users across your enterprise execute them using the server’s HTTP/SOAP interface.
One approach for production systems would be to run test jobs and small jobs on the DataFlux Data Management Studio computer, and to upload larger jobs to the DataFlux Data Management Server. Under this approach, both DataFlux Data Management Studio and DataFlux Data Management Server must have all of the software, licenses, DSN connections, repositories, and other resources that are required to execute the jobs.
This topic describes the basic steps for deploying data jobs and process jobs to the DataFlux Data Management Server. For complete information about this server, see the DataFlux Data Management Server Administrator's Guide.
In DataFlux Data Management Studio, you will need a connection to a DataFlux Data Management Server. See Connecting to Data Management Servers.
The following restrictions apply to the name of a job that will be deployed to a DataFlux Data Management Server. A job name can contain any alpha-numeric characters, white spaces, and any characters from the following list:
,.'[]{}()+=_-^%$@!~/\
DataFlux Data Management Server will not upload or list a job name with characters other than those cited above.
On the DataFlux Data Management Server, you will need all of the software, licenses, DSN connections, repositories, and other resources that are required to execute the jobs. Here are some typical resources that you might need on the server.
DataFlux Data Management Platform Repositories. If a job references other jobs, profiles, rules, tasks, custom metrics, sources, or fields in a DataFlux Data Management Studio repository, that repository or a copy of it must be available from the DataFlux Data Management Server. See Accessing a DBMS Repository From the Server.
Specialized Repositories. If a job references objects that are stored in a special repository, such as a DataFlux Master Data Foundations repository, that repository or a copy of it must be available from the DataFlux Data Management Server.
DSN Connections. If a job references a DSN connection, that DSN or a copy of it must be available on the DataFlux Data Management Server. See Maintaining Data Connections for the Server.
Quality Knowledge Bases (QKBs). If a job depends on a QKB, the QKB must be available from the DataFlux Data Management Server.
Macro Variables and Configuration Directives. If a job depends on macro variables, physical paths, or other directives that are specified in Data Flux configuration files, these files must be available on DataFlux Data Management Server. You might find it convenient to add all of the appropriate items to the configuration files for DataFlux Data Management Studio, and then copy these files to the DataFlux Data Management Server and edit them as needed. See Data Management Studio Files for Macro Variables and Configuration Directives and Data Management Server Files for Macro Variables and Configuration Directives.
Licenses. If a job includes one or more nodes that require special licenses, then you must make these licenses available on the DataFlux Data Management Server.
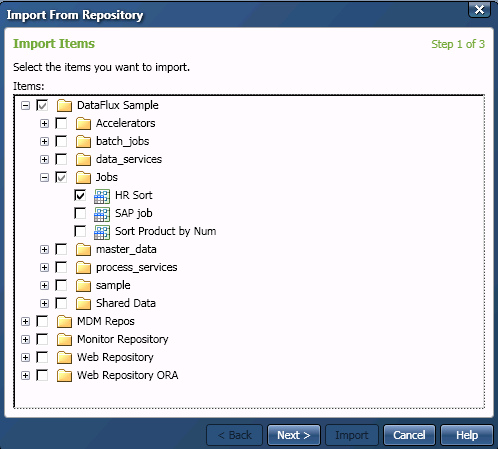
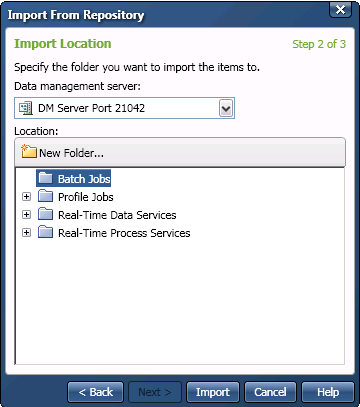
![]() Note: If you wish to import folder structure from DataFlux Data Management Studio to DataFlux Data Management Server, you must select the checkbox on the import location page of the Import From Repository wizard. Everything but the root of the structure path can be imported. This checkbox is not selected by default. If you do not select this checkbox, then you can import only individual objects. If you attempt to import a folder structure that contains a number of objects, the folders will not be imported. The objects will be imported into the target folder that you select in the wizard.
Note: If you wish to import folder structure from DataFlux Data Management Studio to DataFlux Data Management Server, you must select the checkbox on the import location page of the Import From Repository wizard. Everything but the root of the structure path can be imported. This checkbox is not selected by default. If you do not select this checkbox, then you can import only individual objects. If you attempt to import a folder structure that contains a number of objects, the folders will not be imported. The objects will be imported into the target folder that you select in the wizard.
![]() Note: It is recommended that you create the same folder structure on the DataFlux Data Management Server that was created in DataFlux Data Management Studio. For example, if your DataFlux Data Management Studio jobs are in a sub-folder of the custom folder batch_jobs, then create the same folder structure under the Batch Jobs folder on the server. In DataFlux Data Management Studio, it is recommended that you build and test your batch jobs in the custom folder called batch_jobs (or in a sub-folder of it), because mirroring these folders will help preserve any references where one DataFlux Data Management Studio job references another.
Note: It is recommended that you create the same folder structure on the DataFlux Data Management Server that was created in DataFlux Data Management Studio. For example, if your DataFlux Data Management Studio jobs are in a sub-folder of the custom folder batch_jobs, then create the same folder structure under the Batch Jobs folder on the server. In DataFlux Data Management Studio, it is recommended that you build and test your batch jobs in the custom folder called batch_jobs (or in a sub-folder of it), because mirroring these folders will help preserve any references where one DataFlux Data Management Studio job references another.
A DataFlux Data Management Server cannot run a remote job or service whose location is specified with a mapped drive letter, such as Z:\path\remote_job.ddf.The DataFlux Data Management Server runs as a service under a SYSTEM account and no mapped drives are available to such an account. Use a UNC path to specify the location of a remote job or service, such as: \\ServerHostName.MyDomain.com\path\remote_job.ddf.
If you have met the prerequisites above, perform the following steps to deploy a job to a DataFlux Data Management Server.
You can create data jobs and process jobs that provide real-time services. These service jobs are uploaded to a DataFlux Data Management Server, where they can be accessed and executed by a Web client or another application. For more information, see Deploying a Data Job as a Real-Time Service and Deploying a Process Job as a Real-Time Service.
You can create a Web Services Description Language (WSDL) document for an existing real-time service and test it. Then, you must copy the WSDL document to a selected location before you can execute the service. Other users can then copy the document for their use. Note that both data services and process services are supported. DataFlux Data Management Studio supports WSDL v1.1.
The WSDL document defines all input and output data tables, fields, and variables of the corresponding real-time data or process service. Then a SOAP client application can be generated to execute that specific service, exposing the fixed set of inputs and outputs that is described in the WSDL.
WSDL documents are created on the server. Once created, they persist across server restarts and are deleted from the server only when corresponding real-time services are deleted. When a created WSDL document is needed, a DataFlux Data Management Studio user can copy it from the server to a local file. A local WSDL document file can then be loaded by SOAP client-generating tools such as Microsoft Visual Studio to create a SOAP client application for calling that specific real-time service.
Alternatively, some SOAP clients-generating tools (or a web browser) can be pointed directly to a DataFlux Data Management Server for the needed WSDL document. The format of such address link is as follows:
http[s]://host:port/[data or proc]svc/[path on server/][service name]?wsdl
For example, the following string will connect to DMServer running on host dev0082 and port 21036 and retrieve a WSDL document for a data service named 3typesEDP.ddf and a process service named subdir2/anotherEDP.djf:
http://dev0082:21036/datasvc/3typesEDP.ddf?wsdl
http://dev0082:21036/procsvc/subdir2/anotherEDP.djf?wsdl
WSDL documents can be created only for real-time services run on a DataFlux Data Management Server version 2.3 or newer. You must also be running version 2.3 or newer of DataFlux Data Management Studio. For information about deploying an appropriate job, see Deploying Jobs as Web Services.
Perform the following steps to create and copy a WSDL document:
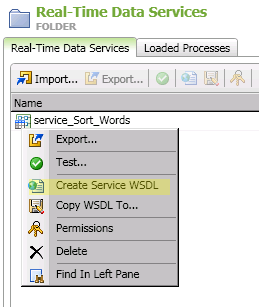
A status dialog will tell you whether the service was successfully created.
![]() Note: If the Copy WSDL To option is not available, click the refresh button at the top of the service window. Then right-click on the service with the associated WSDL document. The Copy WSDL To option should be available. Follow the steps above.
Note: If the Copy WSDL To option is not available, click the refresh button at the top of the service window. Then right-click on the service with the associated WSDL document. The Copy WSDL To option should be available. Follow the steps above.
|
Documentation Feedback: yourturn@sas.com
|
Doc ID: dfDMStd_T_DMServer.html |