データの分割タスク
例:SASHELP.CLASSFITデータセットの分割

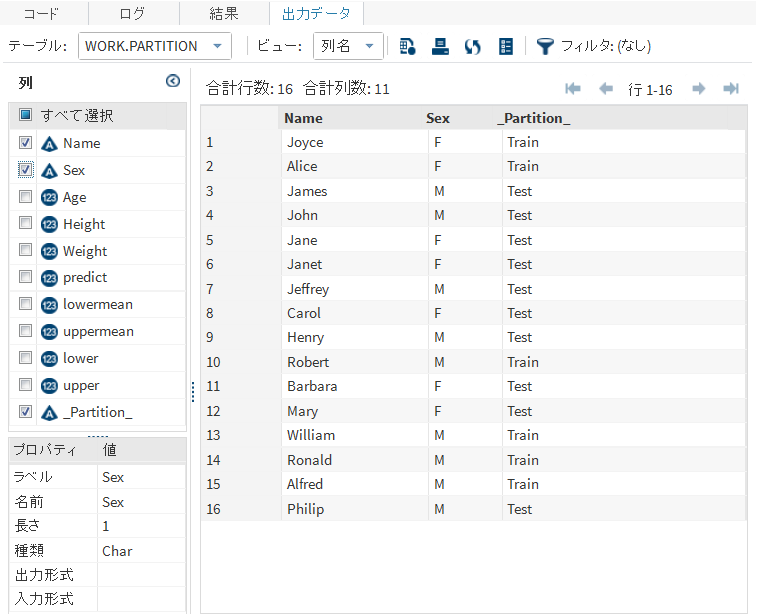
分割データセットの作成
データの分割タスクを実行するには、各分割データのケースの比率オプションに値を割り当てる必要があります。
|
役割
|
説明
|
|---|---|
|
役割
|
|
|
層化基準
|
水準の組み合わせごとに別々の分割を指定します。この役割に最大2つの変数を指定することができます。
|
|
分割データ
|
|
|
分割数
|
分割の数を指定します。1つ、2つ、3つ、または4つの分割を作成することとができます。
|
|
分割nのケースの比率
|
各分割のケースの比率を指定します。すべての分割比率の合計は1以下でなければなりません。
|
|
出力データセット
|
|
|
分割データセット
|
すべての分割を1つのデータセットに入れるか、各分割を別々のデータセットに入れるかを指定します。各出力データセットに一意の名前を指定することができます。
|
|
サンプル抽出されなかったオブザベーションを含める
|
出力データセットにサンプル抽出されなかったオブザベーションを含めるかどうかを指定します。
注: このオプションは、すべての分割を1つのデータセットに保存する場合にのみ適用されます。
|
|
分割値の変数名
|
分割値を含む変数の名前を指定します。
注: このオプションは、すべての分割を1つのデータセットに保存する場合にのみ適用されます。
|
|
分割nデータのID値
|
分割内の各値に使用するIDを指定します。
注: このオプションは、すべての分割を1つのデータセットに保存する場合にのみ適用されます。
|
|
出力データを表示する
|
|
|
出力データを表示する
|
出力データを結果タブに表示される結果に含めるかどうかを指定します。出力データの全部または一部を含めることができます。タスクは、常に出力データタブに表示される出力データセットを作成します。このデータセットは、指定した場所にも保存されます。
|