テキストフィルタノードの使用
この例では、SAS Enterprise Minerが実行されていること、およびダイアグラムワークスペースがプロジェクトで開かれていることを前提としています。プロジェクトやダイアグラムの作成に関する詳細は、Getting Started with SAS Enterprise Minerを参照してください。
テキストフィルタノードを使用すると、テキストマイニング分析における語の総数を削減できます。たとえば、一般的な語や滅多に使われない語が分析にとって有益でない場合、それらの語をフィルタリングして取り除くことができます。この例では、テキストフィルタノードを使用して語をフィルタリングする方法を示します。この例では、ユーザーがテキスト解析ノードの使用を実行済みであり、そこで作成されたプロセスフローダイアグラムを構築することを前提としています。
-
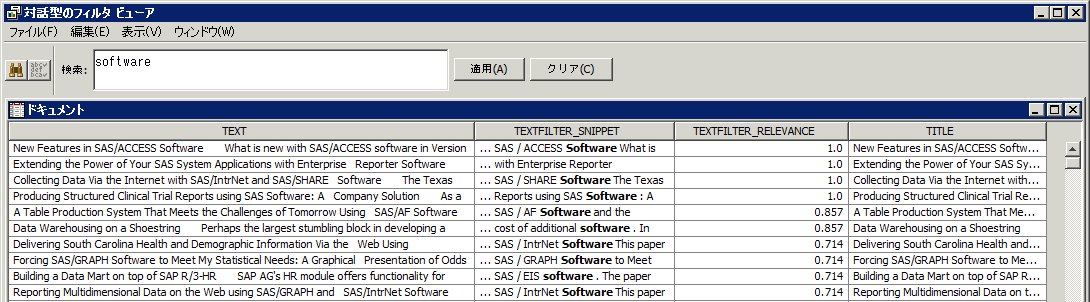
[ドキュメント]テーブルには、検索対称の語を含んでいるテキストの抜粋が表示されます。[ドキュメント]テーブル内の情報を使用すると、ドキュメントの全文およびドキュメントのタイトルに加えて、抜粋結果を調べることにより、使用されている語のコンテキストを理解できるようになります。対話型のフィルタビューアに関する詳細は、SAS Text Minerのヘルプに含まれている対話型のフィルタビューアのトピックを参照してください。対話型のフィルタビューアで語を検索する場合、興味深い問題が発生します。先述したように、“software”の検索では大文字小文字が区別されません。ただし、見つけたい語のインスタンスが存在したが、ドキュメントコレクション内でその語のスペルが間違っていたとしたらどうなるでしょうか?語をフィルタリングする場合、辞書データセットを使用してスペルチェックを行うこともできます。
-
(オプション)テキストフィルタノードを選択し、スペルチェックを行うプロパティを
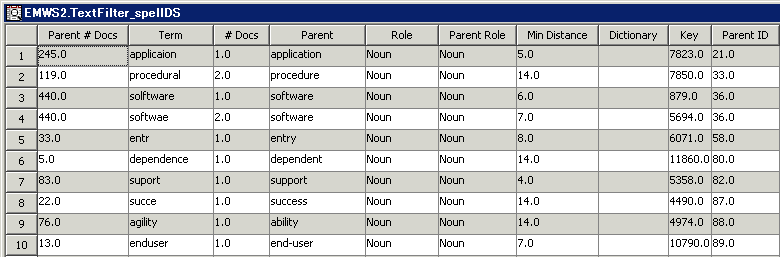
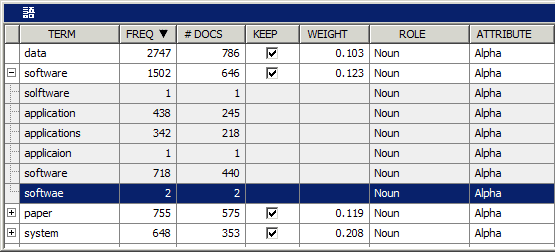
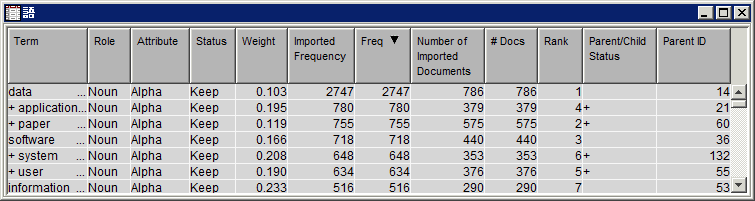
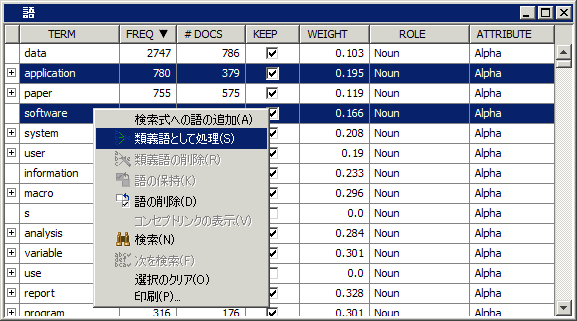
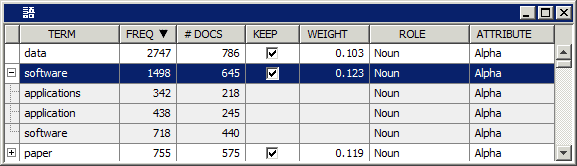
はいに設定します。テキストフィルタノードに戻ると、語がスペルチェックされ、スペルミスが検出されるようになります。スペルチェックで使用するデータセットを指定するには、辞書プロパティの隣にある省略記号ボタンをクリックし、データセットを選択します。辞書データセットの作成に関する詳細は、SAS Text Minerのヘルプに含まれている[辞書データセットの作成]というトピックを参照してください。テキストフィルタノードを右クリックし、実行を選択します。確認ダイアログボックスではいを選択します。同ノードの実行が完了したら、実行状態ダイアログボックス内でOKを選択します。スペルチェックの結果プロパティの隣にある省略記号ボタンをクリックすると、表示されたウィンドウで、スペルチェック時に生成されたスペルの修正を含んでいるデータセットを確認できます。たとえば、語"softwae"は、語"software"のスペルミスでとして識別されます。この関係は、[対話型のフィルタビューア]の[語]テーブルで確認できます。フィルタビューアプロパティの隣にある省略記号ボタンをクリックします。[語]テーブル内にある語"software"を展開し、その類義語を確認します。この類義語には、スペルチェック時にミススペルとして識別された語である"softwae"が含まれています。この類義語には、"applicaion"(この例のステップ7~10で作成されたもの)が含まれているほか、 "applicaion"(スペルチェック時に"application"のスペルミスとして識別された語)が含まれています。

![[対応する語を作成]ダイアログボックス](images/tf_cet_12_3.png)
![[データオプション]ダイアログボックス](images/tf_dod_12_1.png)
![[ドキュメント数と頻度]プロット](images/tf_nodbf_2_12_3.png)