テキスト解析ノードの使用
この例では、テキスト解析ノードを使用して、テキストを含んでいるデータセット内で語とそのインスタンスを特定する方法を示します。この例では、SAS Enterprise Minerが実行されていること、およびダイアグラムワークスペースがプロジェクトで開かれていることを前提としています。プロジェクトとダイアグラムの作成に関する詳細は、プロジェクトの設定を参照してください。
-
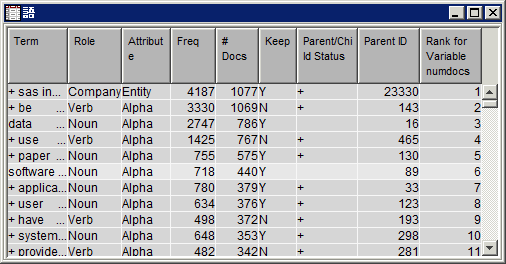
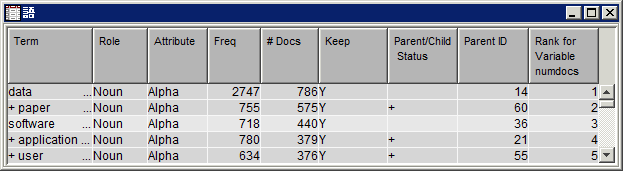
語テーブルに戻り、語“software”がテキスト解析分析内に保持されていることを確認します。これは、Keep列の値が
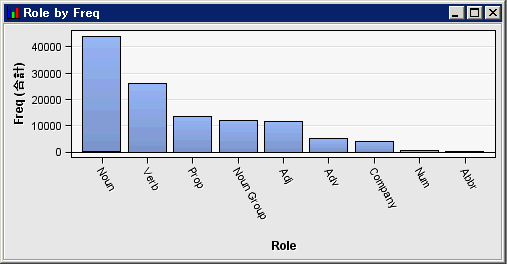
Yであることにより示されます。テキスト解析ノードをデフォルト設定で実行する場合、一部の語は保持されない場合があることに注意してください。テキスト解析ノードを使用すると、ドキュメントコレクション内の語に関する統計データを収集できるだけでなく、特定の品詞、エンティティの種類、属性に一致する語を破棄することにより、解析済みの語の出力セットを変更できます。語テーブル内の語リストを下スクロールし、Noun以外の役割を持つ語の多くが保持されていることを確認します。ここで、テキスト解析結果を、役割がNounである語に制限するとします。 -
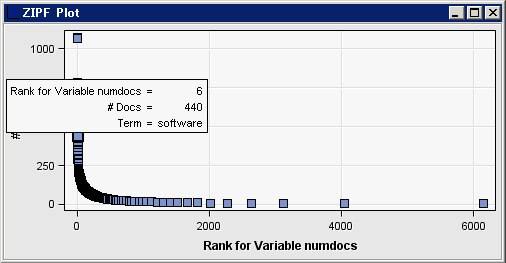
テキスト解析ノードを右クリックし、実行を選択します。表示される確認ダイアログボックスではいをクリックします。同ノードの実行完了後に表示される実行ステータスダイアログボックス内で結果を選択します。語“software”は、他の役割を含めた場合よりも、名詞または名詞グループという役割のみを含めた場合の方が、語の間でのランクがより高くなることが分かります。語テーブルを下スクロールすると、
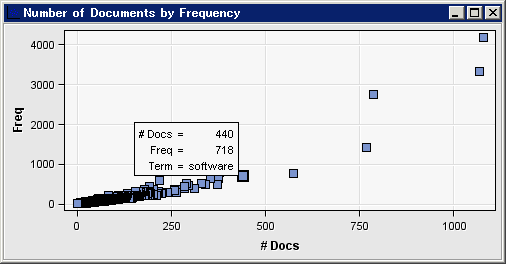
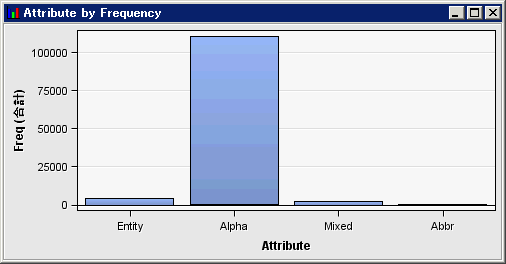
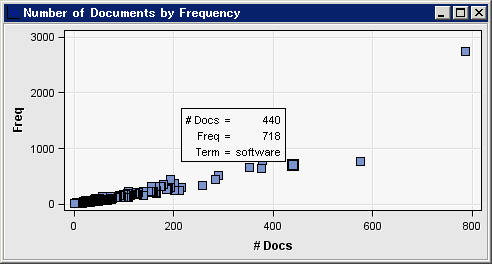
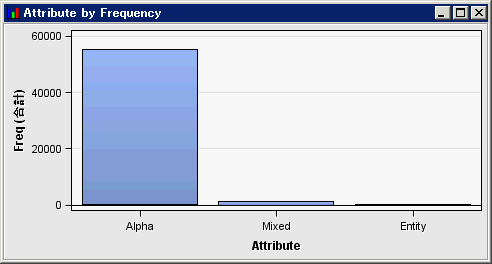
名詞または名詞グループ役割を持つ語が含まれていることを確認できます。予想されるように、ドキュメント数と頻度プロット内にプロットされる語はより少なくなります。同様に、属性と頻度チャートに示されているように、Alphaという属性を含む出力結果内の語の合計数も減少しています。※英語以外の場合は「複数の単語から成る語」に複数の単語から成る語を含むデータセットを指定することはできません。