SPEDIS関数
2つの単語の一致尤度を調べて、2単語間のスペルの違いをコストで表します。
| カテゴリ: | 文字 |
| 制限事項: | この関数は、I18Nレベル0準拠しており、SBCSデータ向けに設計されています。この関数をDBCSまたはMBCSデータの処理に使用しないでください。 |
詳細
基本
SPEDISはクエリとキーワードの間の距離を返します。通常、デフォルトコストでは負数でない100未満の値で、200を超えることはありません。
SPEDISは2単語間のスペルの違いを計算し、一連の演算によってキーワードをクエリ用の単語に変換するために必要な正規化コストとして表します。SPEDIS(QUERY, KEYWORD)は、SPEDIS(KEYWORD, QUERY)とは異なります。
キーワードをクエリに変換するための各演算のコストは、次の表のリストのとおりです。
|
演算
|
コスト
|
説明
|
|---|---|---|
|
match
|
0
|
変化なし
|
|
singlet
|
25
|
重複文字のいずれかを削除
|
|
doublet
|
50
|
文字を二重化
|
|
swap
|
50
|
連続する2文字の順序を逆転
|
|
truncate
|
50
|
末尾から文字を削除
|
|
append
|
35
|
末尾に文字を追加
|
|
delete
|
50
|
中央から文字を削除
|
|
insert
|
100
|
中央に文字を挿入
|
|
replace
|
100
|
中央の文字を置換
|
|
firstdel
|
100
|
最初の文字を削除
|
|
firstins
|
200
|
先頭に文字を挿入
|
|
firstrep
|
200
|
最初の文字を置換
|
距離はコストの合計をクエリの長さで除算して求めます。この比率が1より大きい場合、結果は切り捨てによって最も近い整数に丸められます。
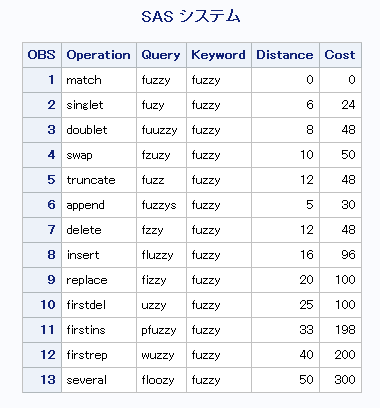
例
SPEDIS関数の使用例を次に示します。
data words; input Operation $ Query $ Keyword $; Distance=spedis(query, keyword); Cost=distance * length(query); datalines; match fuzzy fuzzy singlet fuzy fuzzy doublet fuuzzy fuzzy swap fzuzy fuzzy truncate fuzz fuzzy append fuzzys fuzzy delete fzzy fuzzy insert fluzzy fuzzy replace fizzy fuzzy firstdel uzzy fuzzy firstins pfuzzy fuzzy firstrep wuzzy fuzzy several floozy fuzzy ; proc print data=words; run;