SCAN関数
文字列からn番目の単語を返します。
| カテゴリ: | 文字 |
| 制限事項: | この関数は、I18Nレベル0準拠しており、SBCSデータ向けに設計されています。この関数をDBCSまたはMBCSデータの処理に使用しないでください。 |
| ヒント: | この関数に相当するDBCS関数は、KSCANです。 |
構文
必須引数
string
文字定数、変数または式を指定します。
count
整数値を使用するゼロ以外の数値の定数、変数または式です。SCANで選択する文字列中の単語数を整数値で指定します。たとえば、1の値は1番目の単語、2の値は2番目の単語を示します。次のルールが適用されます。
-
countが正の場合、SCANは文字列の単語を左から右へ数えます。
-
countが負の場合、SCANは文字列の単語を右から左へ数えます。
オプション引数
character-list
文字のリストを初期化する文字式を指定します(省略可能)。このリストは、単語を区切る区切り文字として使用する文字を決定します。次のルールが適用されます。
-
デフォルトでは、character-listのすべての文字が区切り文字として使用されます。
-
modifier引数でK修飾子を指定すると、character-listにないすべての文字が区切り文字として使用されます。
| ヒント | その他の修飾子を使用してcharacter-listにさらに文字を追加できます。 |
modifier
文字定数、変数または式を指定します。これらの空白以外の各文字でSCAN関数のアクションを変更します。空白は無視されます。次の文字を修飾子として使用します。
| aまたはA | 文字のリストにアルファベット文字を追加します。 |
| bまたはB | count引数の符合に関係なく、逆方向(左から右ではなく右から左)にスキャンします。 |
| cまたはC | 文字のリストに制御文字を追加します。 |
| dまたはD | 文字のリストに数字を追加します。 |
| fまたはF | 文字のリストにアンダースコアと英文字(VALIDVARNAME=V7を使用したSAS変数名内の有効な最初の文字)を追加します。 |
| gまたはG | グラフィック文字を文字リストに追加します。グラフィカル文字は、紙面に印刷するとイメージになる文字です。 |
| hまたはH | 文字のリストに水平タブを追加します。 |
| iまたはI | 大文字か小文字かは無視します。 |
| kまたはK | 文字のリストに含まれていないすべての文字を区切り文字として扱うようにします。つまり、Kを指定すると、文字リストに含まれている文字が、区切り文字として省略されることなく、戻り値内に保持されます。Kを指定しない場合、文字リスト内のすべての文字が区切り文字として扱われます。 |
| lまたはL | 小文字を文字リストに追加します。 |
| mまたはM | 複数の連続する区切り文字、および引数string の先頭または末尾にある区切り文字が、長さゼロのワードを意味することを指定します。M修飾子を指定しない場合、複数の連続する区切り文字は1つの区切り文字として扱われ、string引数の先頭または末尾の区切り文字は無視されます。 |
| nまたはN | 文字のリストに数字、アンダースコアおよび英文字(VALIDVARNAME=V7を使用したSAS変数名内に表示可能な文字)を追加します。 |
| oまたはO | charlist引数およびmodifier引数を1回だけ処理します。SCAN関数の呼び出し時毎には処理されません。DATAステップ(WHERE句以外)またはSQLプロシジャでO修飾子を使用すると、character-list引数およびmodifier引数に変更がないループでSCANが呼び出されるとき、より迅速に実行できます。O修飾子はSASコードのSCAN関数の各インスタンスに個別に適用され、SCAN関数のすべてのインスタンスで同じ区切り文字および修飾子が使用されるようにはなりません。 |
| pまたはP | 文字のリストに句読点を追加します。 |
| qまたはQ | 引用符で囲まれた部分文字列内の区切り文字を無視します。string引数の値に、対になっていない引用符が含まれている場合、左から右へのスキャンと、右から左へのスキャンとでは異なる単語が生成されます。 |
| rまたはR | SCANが返す単語から先頭および末尾の空白を削除します。Q修飾子とR修飾子を指定すると、SCAN関数は単語から先頭および末尾の空白をまず削除します。次に、SCANは単語が引用符で始まる場合には単語から引用符の層も1つ削除します。 |
| sまたはS | 文字のリストに空白文字(空白、水平タブ、垂直タブ、キャリッジリターン、ラインフィード、フォームフィード)を追加します。 |
| tまたはT | string引数およびcharlist引数から末尾の空白を取り除きます。両方の文字引数ではなく1つの文字引数からのみ末尾の空白を削除する場合、T修飾子を指定してSCAN関数を使用するかわりにTRIM関数を使用します。 |
| uまたはU | 大文字を文字リストに追加します。 |
| wまたはW | 文字のリストに印刷可能(書き込み可能)な文字を追加します。 |
| xまたはX | 文字のリストに16進文字を追加します。 |
| ヒント | modifier引数が文字定数の場合は、引数を引用符で囲みます。一組の引用符で複数の修飾子を指定します。引数modifierには、文字変数や文字式も指定できます。 |
詳細
“区切り文字”および“単語”の定義
区切り文字とは、単語を区切るために使用される複数の文字のどれかです。区切り文字はcharlist引数とmodifier引数で指定できます。
Q修飾子を指定すると、引用符で囲まれた部分文字列内部の区切り文字は無視されます。
SCAN関数では、“単語”は、次のすべての特性がある部分文字列です。
-
左側が区切り文字または文字列の先頭で境界設定されている
-
右側が区切り文字または文字列の末尾で境界設定されている
-
区切り文字を含まない
文字列の先頭または末尾に区切り文字がある場合、または文字列に2つ以上の連続する区切り文字が含まれている場合、単語の長さがゼロになることがあります。ただし、SCAN関数では、M修飾子を指定しなければ、長さがゼロの単語は無視されます。
注: ”単語”の定義はSCAN関数とCOUNTW関数に共通します。
ASCII環境とEBCDIC環境でデフォルトの区切り文字を使用する
2つの引数のみを指定してSCAN関数を使用する場合、デフォルトの区切り文字は、コンピュータで使用している文字(ASCIIまたはEBCDIC)によって異なります。
-
コンピュータでASCII文字が使われている場合、デフォルトの区切り文字は次のとおりです。空白 !$ % & ( ) * + , - ./ ; < ^ |^文字のないASCII環境の場合、SCAN関数はかわりに~文字を使用します。
-
お使いのコンピュータがEBCDIC文字を使用している場合、デフォルトの区切り文字は次のようになります。空白 !$ % & ( ) * + , - ./ ; < ¬ | ¢
区切り文字とする文字を指定せずにmodifier引数を使用すると、使用される区切り文字はmodifier引数で定義される区切り文字のみになります。この場合、ASCII環境とEBCDIC環境のデフォルトの区切り文字のリストは使用されません。つまり修飾子は、charlist引数で明示的に指定された区切り文字のリストに追加します。修飾子は、デフォルトの修飾子のリストには追加しません。
結果の長さ
DATAステップの多くの変数は固定長です。SCAN関数によって返される単語がその単語の長さよりも長い固定長の変数に割り当てられる場合、その変数の値に空白が埋め込まれます。マクロ変数は可変長であるため、空白は埋め込まれません。
SCAN関数によって返される単語の最大長は、呼び出し元の環境によって異なります。
-
DATAステップで、まだ長さが割り当てられていない変数にSCAN関数から値が返される場合、その変数には最初の引数の長さが設定されます。SCAN関数で、最初の引数の長さとは異なる値を変数に割り当てる必要がある場合は、SCAN関数を使用するステートメントの前に、LENGTHステートメントをその変数に使用してください。演算子または他の関数を含む式でSCAN関数を使用する場合、SCAN関数によって返される単語には最大で32,767文字を割り当てることができます。ただし、WHERE句の場合は除きます。WHERE句の場合、最大長は200文字になります。
-
SQLプロシジャまたはプロシジャのWHERE句では、SCAN関数によって返される単語の最大長は200文字になります。
-
マクロプロセッサでは、SCAN関数によって返される単語の最大長は65,534文字になります。
SCAN関数によって返される単語の最小長は、M修飾子が指定されているかどうかによって異なります。M修飾子を指定したSCAN関数の使用を参照してください。M修飾子を指定しないSCAN関数の使用も参照してください。
M修飾子を指定しないSCAN関数の使用
M修飾子を指定しない場合、文字列内の単語数は連続する非区切り文字の最大部分文字列数になります。ただし、Q修飾子を指定すると、引用符内の区切り文字は無視されます。
M修飾子を指定しないと、SCAN関数は次のように動作します。
-
文字列の先頭または末尾の区切り文字を無視する
-
2つ以上の連続する区切り文字を単一の区切り文字として扱う
文字列に区切り文字以外の文字が含まれていない場合や、文字列の単語数よりも絶対値の大きいcountを指定する場合、SCAN関数は次のいずれかの項目を返します。
-
1つの空白(DATAステップからSCAN関数を呼び出す場合)
-
長さがゼロの文字列(マクロプロセッサからSCAN関数を呼び出す場合)
例
例1: 文字列内の最初と最後の単語を検索する
文字列内の最初と最後の単語をスキャンする例を次に示します。
-
カウントを負に指定すると、SCAN関数は右から左へスキャンします。
-
M修飾子が使用されていないため、先頭と末尾の区切り文字は無視されます。
-
最終オブザベーションでは、文字列のすべての文字が区切り文字となります。
data firstlast; input String $60.; First_Word=scan(string, 1); Last_Word=scan(string, -1); datalines4; Jack and Jill & Bob & Carol & Ted & Alice & Leonardo ! $ % & ( ) * + , - . / ; ;;;; proc print data=firstlast; run;

例2: M修飾子を使用せずに文字列内のすべての単語を検索する
この例では、戻される単語が空白になるまで文字列を左から右へスキャンします。M修飾子が使用されていないため、SCAN関数は長さがゼロの単語を返しません。デフォルトの区切り文字に空白が含まれているため、SCAN関数はカウントが文字列の単語数を超えている場合にのみ空白の単語を返します。そのため、SCANが空白の単語を返す場合、ループが停止する可能性があります。
data all;
length word $20;
drop string;
string=' The quick brown fox jumps over the lazy dog. ';
do until(word=' ');
count+1;
word=scan(string, count);
output;
end;
run;
proc print data=all noobs;
run;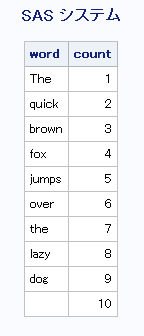
例3: M修飾子とO修飾子を使用して文字列内のすべての単語を検索する
区切り文字としてカンマを指定したM修飾子を使用した結果の例を次に示します。M修飾子を使用すると、先頭、末尾および複数の連続する区切り文字がある場合、SCAN関数は長さがゼロの単語を返します。したがって、空白単語のテストではループが終了しないようにします。かわりに、同じ修飾子と区切り文字のCOUNTW関数を使用して、文字列の単語を数えることができます。
区切り文字と修飾子はSCANおよびCOUNTW関数の各呼び出しで同じであるため、効率を上げるためにO修飾子を使用します。
data comma;
keep count word;
length word $30;
string=',leading, trailing,and multiple,,delimiters,,';
delim=',';
modif='mo';
nwords=countw(string, delim, modif);
do count=1 to nwords;
word=scan(string, count, delim, modif);
output;
end;
run;
proc print data=comma noobs;
run; 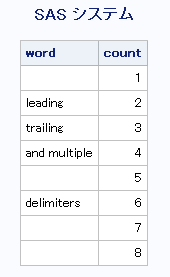
例4: カンマ区切り値、引用符で囲まれた部分文字列、O修飾子、R修飾子の使用
この例では、O修飾子とカンマ区切り文字およびR修飾子を指定したSCAN関数と、O修飾子、カンマ区切り文字のみを指定したSCAN関数を使用します。
SCANまたはCOUNTW関数の各呼び出しでは区切り文字と修飾子は変わらないため、効率を上げるためにO修飾子を使用します。O修飾子はSCAN関数の2つの各インスタンスに個別に適用されます。
-
SCAN関数の最初のインスタンスは、SCANの各呼び出しで同じ区切り文字と修飾子を使用します。
-
SCAN関数の2番目のインスタンスは、SCANの各呼び出しで同じ区切り文字と修飾子を使用します。..
-
SCAN関数の最初のインスタンスは2番目のインスタンスと同じ修飾子を使用しませんが、O修飾子を使用しても問題ありません。
data test;
keep count word word_r;
length word word_r $30;
string='He said, "She said, ""No!""", not "Yes!"';
delim=',';
modif='oq';
nwords=countw(string, delim, modif);
do count=1 to nwords;
word=scan(string, count, delim, modif);
word_r=scan(string, count, delim, modif||'r');
output;
end;
run;
proc print data=test noobs;
run;
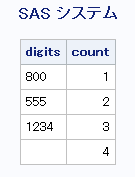
例5: D修飾子とK修飾子を使用して数字の部分文字列を検索する
この例では、数字の部分文字列を検索します。character-list引数はnullです。つまり、文字のリストの初期状態は空です。D修飾子は文字のリストに数字を追加します。K修飾子はリストに含まれていない文字をすべて区切り文字として扱います。したがって、数字以外の文字はすべて区切り文字になります。
data digits;
keep count digits;
length digits $20;
string='Call (800) 555–1234 now!';
do until(digits=' ');
count+1;
digits=scan(string, count, , 'dko');
output;
end;
run;
proc print data=digits noobs;
run;