Rank Data Task
About the Rank Data Task
The Rank Data task computes ranks for one or more numeric variables across the rows in a table and includes the ranks in an output table.
Example: Ranking Students by Height within Age
In this example, you want to rank the students in your class by age and height.
To create this example:
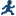
The Rank Data task creates an output data set. In SAS Studio, this data set opens on the Output
Data tab. This data set contains the additional rank_Height column, which shows where
that student ranks within her age group. For example, in the 11-year-old age group,
Joyce is ranked
number 2. In the 12-year-old age group, Louise is ranked number 5.
Assigning Data to Roles
To run the Rank Data
task, you must assign a column to the Columns to rank role.
|
Role
|
Description
|
|---|---|
|
Roles
|
|
|
Columns
to rank
|
Each column that is assigned to this role is ranked. You must assign at least one
variable to this role. By default, the rankings column is given the name rank_column-name,
where column-name is the name
of the original column.
|
|
Additional Roles
|
|
|
Rank by
|
When you assign one or more columns to this role, the input table is sorted by the selected column or columns and rankings are calculated within each
group.
|
|
Output Data Set
|
|
|
Create new
variables for the ranked variables
|
specifies that the output table contains the original columns as well as the ranked
columns. If you want to replace
the original column with the ranked columns, clear the Create new variables for the ranked variables check
box.
By default, the ranked
column is given the name rank_column-name,
where column-name is the name
of the original column.
|
|
Show output
data
|
specifies whether to display all or a subset of the output data in the results.
|
Setting Options
You must select at
least one output option.
|
Option Name
|
Description
|
|---|---|
|
Options
|
|
|
Ranking
method
|
specifies the method to use when ranking the data. Here are the valid values:
Ranks
partitions the original values into 100 groups, in which the smallest values receive
a percentile value of 0 and the largest values receive a percentile value of 99.
Quantiles
partitions the original values into one of these quantiles.
|
|
Ranking
method (continued)
|
Fractional ranks
computes the fractional ranks by using either a denominator of N or N+1. A denominator of N computes fractional ranks by dividing each rank
by the number of observations that have nonmissing values of the ranking variable. A denominator of N+1 computes fractional ranks by dividing
each rank by
the denominator n+1, where n is the number of observations that have nonmissing values of the ranking variable.
Percentages
divides each rank by the number of observations that have nonmissing values of the
variable and multiplies the result by 100 to get a percentage.
|
|
Ranking
method (continued)
|
Normal scores of ranks
computes normal scores from the ranks. The resulting variables appear normally distributed.
Here are the formulas:
Blom formula
Tukey formula
van der Waerden
In these formulas,
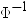 is the inverse cumulative normal (PROBIT) function, ri is the rank of the ith observation, and n is the number of nonmissing observations for the ranking variable. is the inverse cumulative normal (PROBIT) function, ri is the rank of the ith observation, and n is the number of nonmissing observations for the ranking variable.
Note: If you set the If
values are tied, use option, the Rank Data task computes
the normal score from the ranks based on non-tied values and applies
the ties specification to the resulting score.
Savage scores of ranks
computes Savage (or exponential) scores from the ranks.
Note: If you set the If
values are tied, use option, the Rank Data task computes
the Savage score from the ranks based on non-tied values and applies
the ties specification to the resulting score.
|
|
If values
are tied, use
|
specifies how to compute
normal scores or ranks for tied data values.
Default method
assigns the default method for your ranking method. If you select Percentages or Fractional
ranks as the ranking method, the high value is the default. For all other ranking methods, the mean is the default.
Mean of ranks
assigns the mean of the corresponding rank or normal scores.
High rank
assigns the largest of the corresponding ranks or normal scores.
Low rank
assigns the smallest of the corresponding ranks or normal scores.
Dense rank (ties are the same rank)
computes scores and ranks by treating tied values as a single-order statistic. For
the default method, ranks
are consecutive integers that begin with the number 1 and end with the number of unique, nonmissing values of the variable that is being ranked. Tied values are assigned the same rank.
|
|
Rank order
|
specifies whether to
list the values from smallest to largest or from largest to smallest.
|
Copyright © SAS Institute Inc. All rights reserved.