Heckman Selection Model Task
About the Heckman Selection Model Task
The Heckman's two-step
selection method provides a means of correcting for non-randomly selected
samples. It is a two-stage estimation method. The first stage performs
a probit analysis on a selection equation. The second stage analyzes
an outcome equation based on the first-stage binary probit model.
Example: Heckman Selection Model Task
To create this example:
-
Create the Work.Mroz data set. For more information, see MROZ Data Set.
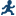
Assigning Data to Roles
Copyright © SAS Institute Inc. All rights reserved.