Database Connection Tips
Common Fields
The following fields
are used for connecting to most databases:
-
User ID
-
Password
-
Server
-
Port
-
Database
The Server field
corresponds to the host name for the server. Some databases use connection
information that is similar to ODBC. These databases often request
a data source name instead of the combination of server and port.
See the following sections for connection details for databases that
have unique fields.
Note: After you have successfully
imported a table, the connection information is saved, except for
the password. This enables you to import additional tables quickly
or to re-import the table as needed.
Most fields are case
sensitive. For example, specifying a value of
products in
the Database field might not be the same
as specifying PRODUCTS.
Case sensitivity depends on the database vendor. Furthermore, some
databases use schemas. Some databases automatically use the user ID
as the schema if a schema is not explicitly specified. Be aware that
the User ID and Schema fields
can be case sensitive. Check with your database administrator if you
are unsure.
Additional Options for Importing Hadoop Tables
SAS Visual Analytics
offers self-service options for importing data from Cloudera Hadoop,
Hortonworks Data Platform, and InfoSphere BigInsights. Each of these
platforms requires separate setup by your administrator.
A common connection
type for all of these platforms is to connect to Hive or HiveServer2
and then import tables. The SAS system options field
can be used to specify environment variables such as the following:
set=SAS_HADOOP_JAR_PATH="/path/to/files"
The
options keyword
is submitted with any options that you specify in the field.
If the Hadoop cluster
is configured with the SAS Embedded Process, then you can perform
parallel loading from HDFS to SAS LASR Analytic Server. In this case,
the Configuration field must specify the
path to a Hadoop configuration file. You must also specify at least
the HDFS_METADIR= and HDFS_DATADIR= options in the Hadoop
options field. More options might be necessary for your
site. For information about setting up parallel loading from Hadoop,
see SAS Visual Analytics: Administration Guide.
Additional Options for Importing PostgreSQL Tables
The Schema field
is not case sensitive when you browse for tables, but it is case sensitive
when the import is performed. As a result, if you specify a schema
in the wrong case, you can successfully browse for a table, and then
select it in the Choose a Table window. However,
the import fails. In this case, contact your database administrator
for assistance with the schema name.
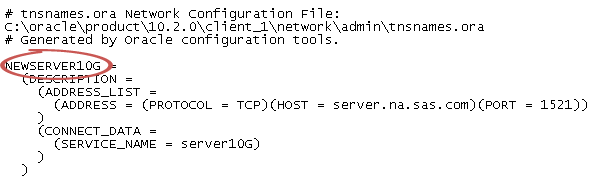
Additional Options for Importing Oracle Tables
The value for the Path field
is related to the net service name in the tnsnames.ora file. The tnsnames.ora
file is generated during the Oracle client installation on the machine
for the SAS Application Server. The file is typically stored in an
Oracle installation directory such as
/opt/oracle/app/oracle/product/10.2.0/db_1/network/admin/tnsnames.ora.
The net service name for the connection information is contained in
this file. See the following figure:
Additional Options for Importing Teradata Tables
The Teradata
Management Server
field is used to determine whether the SAS LASR Analytic Server
is co-located on the data appliance. If the SAS LASR Analytic Server
and the Teradata database are on the same data appliance, then make
sure that the Teradata Management Server
field includes the host name that the SAS LASR Analytic Server
uses.
SAS Visual Analytics
and the Teradata database can be configured to transfer data in parallel
when they are not co-located on the same data appliance. For information
about setting up parallel loading, see SAS Visual Analytics: Administration Guide.
Copyright © SAS Institute Inc. All rights reserved.