Overview of Visualizations
Visualization Types
|
Automatically selects
the chart type based on the data that is assigned to the visualization.
When you are first exploring a new data set, automatic charts give
you a quick view of the data.
For more information,
see Working with Automatic Charts.
|
||
|
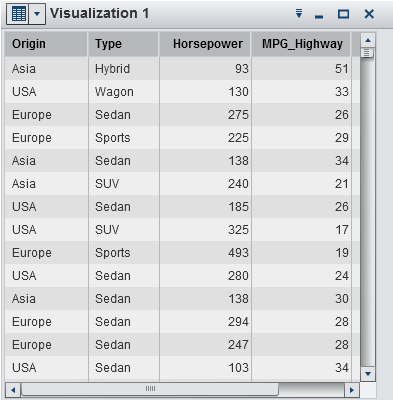
Displays the data as
a table. Tables enable you to examine the raw data for each observation
in the data source. You can rearrange the data columns and apply sorting.
For more information,
see Working with Tables.
|
||
|
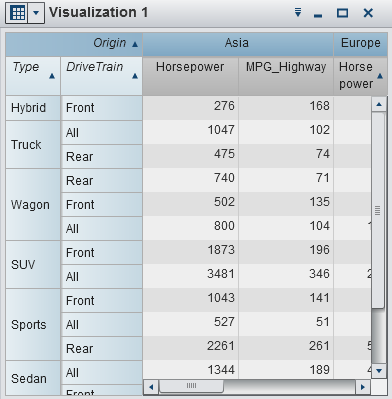
Displays the data as
a crosstab. Crosstabs enable you to examine the data for intersections
of hierarchy nodes or category values. You can rearrange the rows
and columns and apply sorting. Unlike tables, crosstabs display aggregated
data.
For more information,
see Working with Crosstabs.
|
||
|
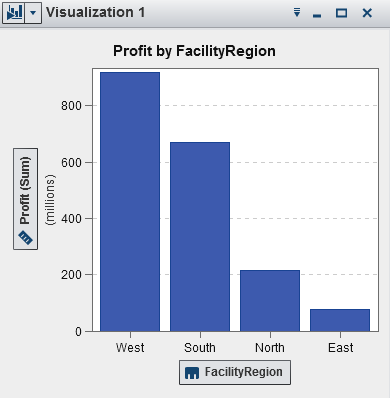
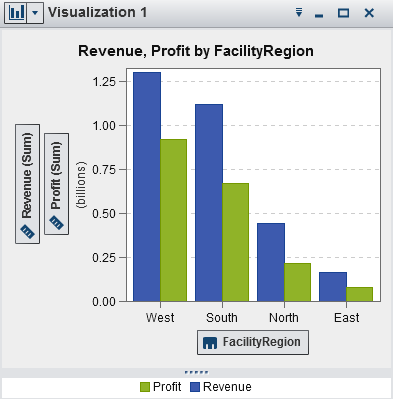
Displays the data as
a bar chart. Bar charts are useful for comparing data that is aggregated
by the distinct values of a category.
A bar chart consists
of vertical bars or horizontal bars. You can apply grouping and create
lattices.
For more information,
see Working with Bar Charts.
|
||
|
For more information,
see Working with Line Charts.
|
||
|
Displays the data as
a scatter plot. Scatter plots are useful to examine the relationship
between numeric data items.
In a scatter plot, you
can apply statistical analysis with correlation and regression. Scatter
plots support grouping.
When you apply more
than two measures to a scatter plot, a scatter plot matrix compares
each pairing of measures.
For more information,
see Working with Scatter Plots.
|
||
|
Displays the data as
a bubble plot. A bubble plot displays the relationships among at least
three measures. Two measures are represented by the plot axes, and
the third measure is represented by the size of the plot markers.
You can apply grouping
and create lattices. By assigning a datetime data item to the plot,
you can animate the bubbles to display changes in the data over time.
For more information,
see Working with Bubble Plots.
|
||
|
Displays the data as
a histogram. A histogram displays the distribution of values for a
single measure.
You can select the bar
orientation, and you can select whether the values are displayed as
a percentage or as a count.
For more information,
see Working with Histograms.
|
||
|
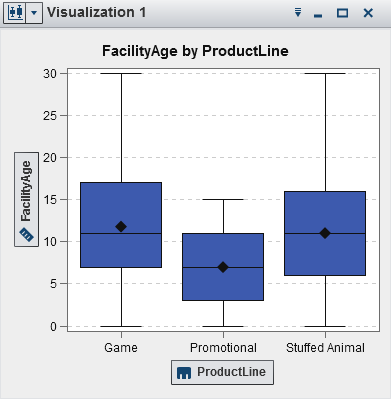
Displays the data as
a box plot. A box plot displays the distribution of values for a single
measure using a box and whiskers. The size and location of the box
indicate the range of values that are between the 25th and 75th percentile.
Additional statistical information is represented by other visual
features.
You can create lattices,
and you can select whether the average (mean) value and outliers are
displayed for each box.
For more information,
see Working with Box Plots.
|
||
|
Displays the data as
a heat map. A heat map displays the distribution of values for two
data items using a table with colored cells. If you do not assign
a measure to the Color data role, then a
cell’s color represents the frequency of each intersection
of values. If you assign a measure to the Color data
role, then a cell’s color represents the measure value of each
intersection of values.
For more information,
see Working with Heat Maps.
|
||
|
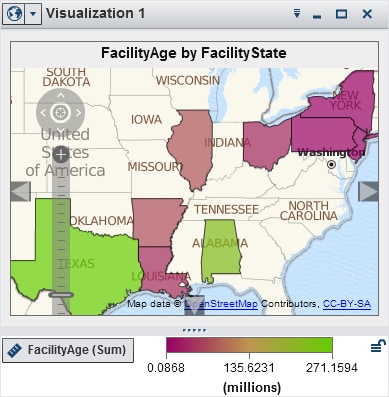
Displays the data as
a geo map. A geo map displays your data as an overlay on a geographic
map. You can display your data either as bubbles or as colored regions.
For more information,
see Working with Geo Maps.
|
||
|
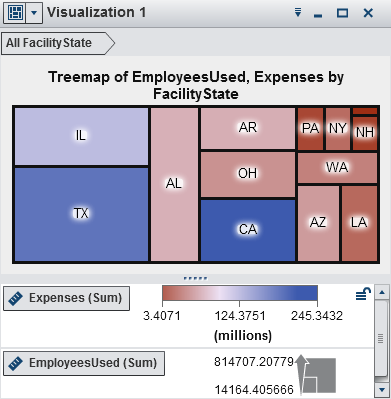
Displays the data as
a treemap. A treemap displays your data as a set of rectangles (called
tiles). Each tile represents a category value or a hierarchy node.
The size of each tile represents either the frequency of the category
or the value of a measure. The color of each tile can represent the
rectangles can indicate the value of an additional measure.
For more information,
see Working with Treemaps.
|
||
|
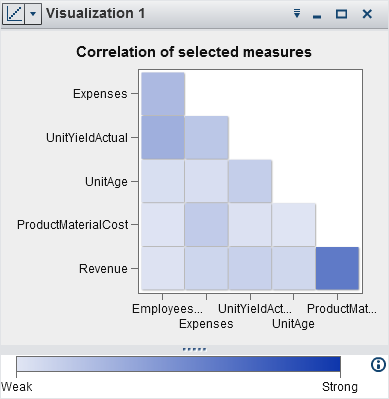
Displays the data as
a correlation matrix. A correlation matrix displays the degree of
correlation between measures as a series of colored rectangles. The
color of each rectangle indicates the strength of the correlation.
For more information,
see Working with Correlation Matrices.
|
||
|
Displays the data as
a decision tree. A decision tree displays a series of nodes as a tree,
where the top node is the target data item, and each branch of the
tree represents a split in the values of a predictor data item.
The splits enable you
to see which values of the predictor data item correspond to different
distributions of values in the target data item.
For more information,
see Working with Decision Trees.
|

Copyright © SAS Institute Inc. All rights reserved.