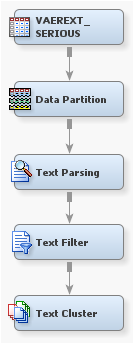
Cluster Data
The Text
Cluster node clusters documents into disjointed sets of documents and reports on the descriptive
terms for those clusters. Two algorithms are available. The Expectation
Maximization algorithm clusters documents with a flat representation,
and the Hierarchical clustering algorithm groups clusters into a tree
hierarchy. Both approaches rely on the singular value decomposition
(SVD) to transform the original weighted, term-document frequency
matrix into a dense but low dimensional representation. For more information
about the Text Cluster node, see the SAS
Text Miner help.