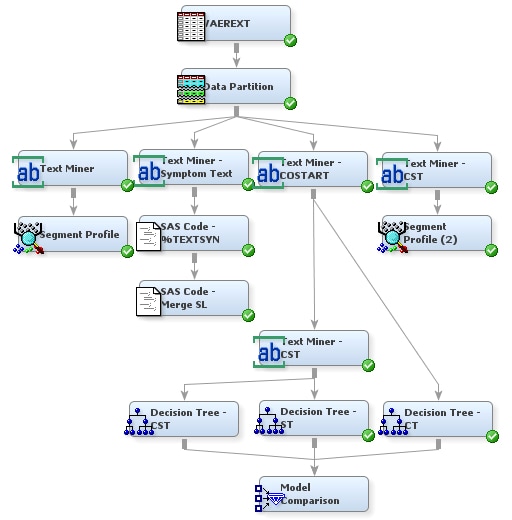
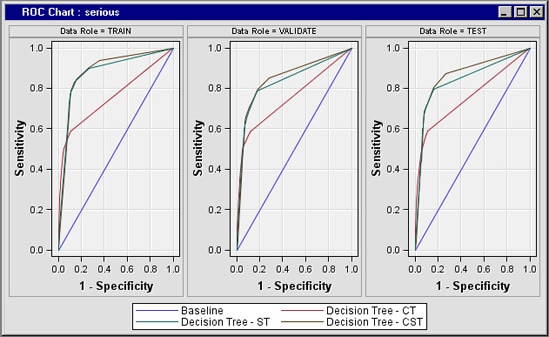
The greater
the area under the curve, the better the model. The red line in the
following image shows the results of the model using COSTART terms,
the green line shows the results of the SYMPTOM_TEXT terms, and the
brown line shows the results of the combined COSTART and SYMPTOM_TEXT
terms. The worst model uses only the COSTART terms, while the best
model uses a combination of COSTART and SYMPTOM_TEXT. Apparently,
text mining can add information not contained in the COSTART terms.
The text mining model provides better results than the keyword-based
model. Combining the models offers the best results.