| Multivariate Analysis: Canonical Discriminant Analysis |
The Output Variables Tab
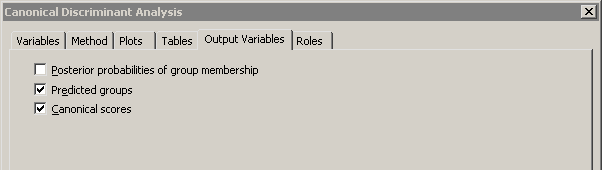
You can use the Output Variables tab (Figure 29.13) to add analysis variables to the data table. If you request a plot that uses one of the output variables, then that variable is automatically created even if you did not explicitly select the variable on the Output Variables tab.
The following list describes each output variable added to the data
table and indicates how the
output variable is named. ![]() represents the name of
the classification variable.
represents the name of
the classification variable.
- Posterior probabilities of group membership
-
adds variables named CDAProb_
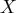 , where is the name of an X
variable.
, where is the name of an X
variable.
- Predicted groups
-
adds a variable named CDAPred_
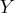 that contains the name of the
group to which each observation is assigned.
that contains the name of the
group to which each observation is assigned.
- Canonical scores
-
adds variables named CDA_1 through CDA_
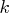 , where is
the number of canonical components.
, where is
the number of canonical components.
If a classification fit plot is requested on the Plots tab, then
a variable named CDALogProb_![]() is created, as described in
the section "The Plots Tab".
is created, as described in
the section "The Plots Tab".
|
Figure 29.13: The Output Tab
Copyright © 2008 by SAS Institute Inc., Cary, NC, USA. All rights reserved.