The SURVEYFREQ Procedure

Wald Chi-Square Test
PROC SURVEYFREQ provides two Wald chi-square tests for independence of the row and column variables in a two-way table: a Wald chi-square test based on the difference between observed and expected weighted cell frequencies, and a Wald log-linear chi-square test based on the log odds ratios. These statistics test for independence of the row and column variables in two-way tables, taking into account the complex survey design. For information about Wald statistics and their applications to categorical data analysis, see Bedrick (1983), Koch, Freeman, and Freeman (1975), and Wald (1943).
For these two tests, PROC SURVEYFREQ computes the generalized Wald chi-square statistic, the corresponding F statistic, and also an adjusted F statistic for tables larger than 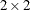 . Under the null hypothesis of independence, the Wald chi-square statistic approximately follows a chi-square distribution
with (R – 1)(C – 1) degrees of freedom for large samples. However, it has been shown that this test can perform poorly in terms of actual
significance level and power, especially for tables with a large number of cells or for samples with a relatively small number
of clusters. For more information, see Thomas and Rao (1984), Thomas and Rao (1985), and Lohr (2010). For information about the adjusted F statistic, see Fellegi (1980) and Hidiroglou, Fuller, and Hickman (1980). Thomas and Rao (1984) found that the adjusted F statistic provides a more stable test than the chi-square statistic, although its power can be low when the number of sample
clusters is not large. See also Korn and Graubard (1990) and Thomas, Singh, and Roberts (1996).
. Under the null hypothesis of independence, the Wald chi-square statistic approximately follows a chi-square distribution
with (R – 1)(C – 1) degrees of freedom for large samples. However, it has been shown that this test can perform poorly in terms of actual
significance level and power, especially for tables with a large number of cells or for samples with a relatively small number
of clusters. For more information, see Thomas and Rao (1984), Thomas and Rao (1985), and Lohr (2010). For information about the adjusted F statistic, see Fellegi (1980) and Hidiroglou, Fuller, and Hickman (1980). Thomas and Rao (1984) found that the adjusted F statistic provides a more stable test than the chi-square statistic, although its power can be low when the number of sample
clusters is not large. See also Korn and Graubard (1990) and Thomas, Singh, and Roberts (1996).
If you specify the WCHISQ option in the TABLES statement, PROC SURVEYFREQ computes a Wald test for independence in the two-way table based on the differences between the observed (weighted) cell frequencies and the expected frequencies.
Under the null hypothesis of independence of the row and column variables, the expected cell frequencies are computed as
![\[ E_{rc} = \widehat{N}_{r \cdot } ~ \widehat{N}_{\cdot c} ~ / ~ \widehat{N} \]](images/statug_surveyfreq0124.png)
where 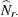 is the estimated total for row r,
is the estimated total for row r, 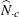 is the estimated total for column c, and
is the estimated total for column c, and 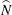 is the estimated overall total, as described in the section Expected Weighted Frequency. The null hypothesis that the population weighted frequencies equal the expected frequencies can be expressed as
is the estimated overall total, as described in the section Expected Weighted Frequency. The null hypothesis that the population weighted frequencies equal the expected frequencies can be expressed as
![\[ H_0\colon Y_{rc} = N_{rc} ~ - ~ E_{rc} ~ = ~ 0 \]](images/statug_surveyfreq0265.png)
for all 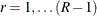 and
and 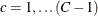 . This null hypothesis can be stated equivalently in terms of cell proportions, with the expected cell proportions computed
as the products of the marginal row and column proportions.
. This null hypothesis can be stated equivalently in terms of cell proportions, with the expected cell proportions computed
as the products of the marginal row and column proportions.
The generalized Wald chi-square statistic 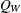 is computed as
is computed as
![\[ Q_\mi {W} = \widehat{\mb{Y}}’ ~ ( \mb{H} ~ \widehat{\mb{V}}(\widehat{\mb{N}}) ~ \mb{H}’ )^{-1} ~ \widehat{\mb{Y}} \]](images/statug_surveyfreq0269.png)
where 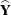 is an array of (R – 1)(C – 1) differences between the observed and expected weighted frequencies
is an array of (R – 1)(C – 1) differences between the observed and expected weighted frequencies 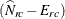 , and
, and 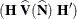 estimates the variance of .
estimates the variance of .
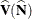 is the covariance matrix of the estimates
is the covariance matrix of the estimates 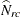 , and its computation is described in the section Covariances of Frequency Estimates.
, and its computation is described in the section Covariances of Frequency Estimates.
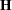 is an (R – 1)(C – 1) by RC matrix that contains the partial derivatives of the elements of with respect to the elements of
is an (R – 1)(C – 1) by RC matrix that contains the partial derivatives of the elements of with respect to the elements of 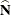 . The elements of are computed as follows, where a denotes a row different from row r, and b denotes a column different from column c:
. The elements of are computed as follows, where a denotes a row different from row r, and b denotes a column different from column c:
![\begin{eqnarray*} \partial {\widehat{Y}_{rc}} / \partial {\widehat{N}_{rc}} & = & 1 ~ - ~ \left( \widehat{N}_{r \cdot } ~ + ~ \widehat{N}_{\cdot c} ~ - ~ \widehat{N}_{\cdot c} ~ \widehat{N}_{r \cdot } ~ / ~ \widehat{N} \right) ~ / ~ \widehat{N} \\[0.1in] \partial {\widehat{Y}_{rc}} / \partial {\widehat{N}_{ac}} & = & - ~ \left( \widehat{N}_{r \cdot } ~ - ~ \widehat{N}_{r \cdot } ~ \widehat{N}_{\cdot c} ~ / ~ \widehat{N} \right) ~ / ~ \widehat{N} \\[0.1in] \partial {\widehat{Y}_{rc}} / \partial {\widehat{N}_{rb}} & = & - ~ \left( \widehat{N}_{\cdot c} ~ - ~ \widehat{N}_{r \cdot } ~ \widehat{N}_{\cdot c} ~ / ~ \widehat{N} \right) ~ / ~ \widehat{N} \\[0.1in] \partial {\widehat{Y}_{rc}} / \partial {\widehat{Y}_{ab}} & = & \widehat{N}_{r \cdot } ~ \widehat{N}_{\cdot c} ~ / ~ \widehat{N}^{~ 2} \end{eqnarray*}](images/statug_surveyfreq0273.png)
Under the null hypothesis of independence, the statistic approximately follows a chi-square distribution with (R – 1)(C – 1) degrees of freedom for large samples.
PROC SURVEYFREQ computes the Wald F statistic as
![\[ F_\mi {W} = Q_\mi {W} ~ / ~ (R-1)(C-1) \]](images/statug_surveyfreq0274.png)
Under the null hypothesis of independence, 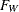 approximately follows an F distribution with (R – 1)(C – 1) numerator degrees of freedom. The denominator degrees of freedom are the degrees of freedom for the variance estimator
and depend on the sample design and the variance estimation method. For more information, see the section Degrees of Freedom. Alternatively, you can use the DF=
option in the TABLES statement to specify the denominator degrees of freedom.
approximately follows an F distribution with (R – 1)(C – 1) numerator degrees of freedom. The denominator degrees of freedom are the degrees of freedom for the variance estimator
and depend on the sample design and the variance estimation method. For more information, see the section Degrees of Freedom. Alternatively, you can use the DF=
option in the TABLES statement to specify the denominator degrees of freedom.
For tables larger than , PROC SURVEYFREQ also computes the adjusted Wald F statistic as
![\[ F_{\mathit{Adj\_ W}} = Q_\mi {W} ~ (s - k + 1 ) ~ / ~ (k s) \]](images/statug_surveyfreq0276.png)
where k = (R – 1)(C – 1), and s is the degrees of freedom. (For more information, see the section Degrees of Freedom.) Alternatively, you can use the DF=
option in the TABLES statement to specify the value of s. For tables, k = (R – 1 )(C – 1) = 1, and therefore the adjusted Wald F statistic equals the (unadjusted) Wald F statistic and has the same numerator and denominator degrees of freedom.
Under the null hypothesis, 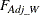 approximately follows an F distribution with k numerator degrees of freedom and (s – k + 1) denominator degrees of freedom.
approximately follows an F distribution with k numerator degrees of freedom and (s – k + 1) denominator degrees of freedom.