The CORRESP Procedure

Using the TABLES Statement
This section explains some of the choices for the correspondence analysis input data table and illustrates some table-construction
capabilities of PROC CORRESP. The SAS data set Neighbor, which follows, will be used throughout this section to illustrate various ways in which PROC CORRESP can read and process
data. This data set consists of one observation for each resident in a fictitious neighborhood along with some personal information.
title 'PROC CORRESP Table Construction';
data Neighbor;
input Name $ 1-10 Age $ 12-18 Sex $ 19-25
Height $ 26-30 Hair $ 32-37;
datalines;
Jones Old Male Short White
Smith Young Female Tall Brown
Kasavitz Old Male Short Brown
Ernst Old Female Tall White
Zannoria Old Female Short Brown
Spangel Young Male Tall Blond
Myers Young Male Tall Brown
Kasinski Old Male Short Blond
Colman Young Female Short Blond
Delafave Old Male Tall Brown
Singer Young Male Tall Brown
Igor Old Short
;
This first step creates a simple contingency table or crosstabulation. In the TABLES statement, each variable list consists of a single variable. The following statements produce the table in Figure 34.3.
proc corresp data=Neighbor dimens=1 observed short; title2 'Simple Crosstabulation'; ods select observed; tables Sex, Age; run;
These statements create a contingency table with two rows (Female and Male) and two columns (Old and Young) and show the neighbors categorized by age and sex. The DIMENS=1 option specifies the number of dimensions in the correspondence
analysis. Typically, you do not have to specify this option, because typically your tables will be larger than two by two.
The default is DIMENS=2, which is too large for a table with a two-level factor. The OBSERVED option displays the contingency
table. The SHORT option limits the displayed output. Because it contains missing values, the observation where Name='Igor' is omitted from the analysis. The table is shown in Figure 34.3.
Figure 34.3: Contingency Table for Sex, Age
The preceding example showed how to make a two-way contingency table based on the levels of two categorical variables, which,
if it were larger, would be a very typical form of data for a correspondence analysis. However, many other types of tables,
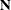 , can be used as input to a correspondence analysis, and all tables can be defined based on a binary matrix,
, can be used as input to a correspondence analysis, and all tables can be defined based on a binary matrix, 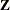 . The BINARY option enables you to directly compute and display this matrix. The TABLES statement consists of a single list
of all the categorical variables. The following statements produce Figure 34.4.
. The BINARY option enables you to directly compute and display this matrix. The TABLES statement consists of a single list
of all the categorical variables. The following statements produce Figure 34.4.
proc corresp data=neighbor observed short binary; title2 'Binary Coding'; ods select binary; tables Hair Height Sex Age; run;
Figure 34.4: Binary Table Using the BINARY Option
| PROC CORRESP Table Construction |
| Binary Coding |
| Binary Table | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Blond | Brown | White | Short | Tall | Female | Male | Old | Young | |
| 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 |
| 2 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
| 3 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 |
| 4 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 |
| 5 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| 6 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
| 7 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
| 8 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 |
| 9 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 10 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 |
| 11 | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
In this case,  is directly analyzed. The binary matrix has one row for each individual or case and one column for each category. A binary
table constructed from m categorical variables has m partitions. This binary table has four partitions, one for each of the four categorical variables. Each partition has a 1
in each row, and each row contains exactly four 1s because there are four categorical variables. More generally, the binary
design matrix has exactly m 1s in each row. The 1s indicate the categories to which the observation applies. For example, the categorical variable
is directly analyzed. The binary matrix has one row for each individual or case and one column for each category. A binary
table constructed from m categorical variables has m partitions. This binary table has four partitions, one for each of the four categorical variables. Each partition has a 1
in each row, and each row contains exactly four 1s because there are four categorical variables. More generally, the binary
design matrix has exactly m 1s in each row. The 1s indicate the categories to which the observation applies. For example, the categorical variable Sex, with two levels (Female and Male), is coded using two indicator variables. For the variable Sex, a male would be coded Female=0 and Male=1, and a female would be coded Female=1 and Male=0. This is the same kind of coding that procedures like GLM and TRANSREG use for CLASS variables.
Implicitly, the binary table has an automatic row variable that is equal to the observation number. Alternatively, when there
is a row ID variable, as there is in this case, you can use it as a row variable in the TABLES statement, and the resulting
ordinary observed frequency table is the binary table. This example uses two variable lists: Name for the row variable, and Hair Height Sex Age for the column variables. Because two lists were provided, the BINARY option was not specified. The following statements
produce Figure 34.5.
proc corresp data=neighbor observed short; title2 'Binary Coding'; ods select observed; tables Name, Hair Height Sex Age; run;
Figure 34.5: Binary Table Using a Row Variable
| PROC CORRESP Table Construction |
| Binary Coding |
| Contingency Table | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Blond | Brown | White | Short | Tall | Female | Male | Old | Young | Sum | |
| Colman | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 4 |
| Delafave | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 4 |
| Ernst | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 4 |
| Jones | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 0 | 4 |
| Kasavitz | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 4 |
| Kasinski | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 4 |
| Myers | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 4 |
| Singer | 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 4 |
| Smith | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 4 |
| Spangel | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 4 |
| Zannoria | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 4 |
| Sum | 3 | 6 | 2 | 5 | 6 | 4 | 7 | 6 | 5 | 44 |
With the MCA option, the Burt table (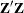 ) is analyzed. A Burt table is a partitioned symmetric matrix containing all pairs of crosstabulations among a set of categorical
variables. Each diagonal partition is a diagonal matrix containing marginal frequencies (a crosstabulation of a variable with
itself). Each off-diagonal partition is an ordinary contingency table. The following statements produce Figure 34.6.
) is analyzed. A Burt table is a partitioned symmetric matrix containing all pairs of crosstabulations among a set of categorical
variables. Each diagonal partition is a diagonal matrix containing marginal frequencies (a crosstabulation of a variable with
itself). Each off-diagonal partition is an ordinary contingency table. The following statements produce Figure 34.6.
proc corresp data=neighbor observed short mca; title2 'MCA Burt Table'; ods select burt; tables Hair Height Sex Age; run;
Note that there is a single variable list in the TABLES statement, because the row and column variable lists are the same.
Figure 34.6: MCA Burt Table
| PROC CORRESP Table Construction |
| MCA Burt Table |
| Burt Table | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Blond | Brown | White | Short | Tall | Female | Male | Old | Young | |
| Blond | 3 | 0 | 0 | 2 | 1 | 1 | 2 | 1 | 2 |
| Brown | 0 | 6 | 0 | 2 | 4 | 2 | 4 | 3 | 3 |
| White | 0 | 0 | 2 | 1 | 1 | 1 | 1 | 2 | 0 |
| Short | 2 | 2 | 1 | 5 | 0 | 2 | 3 | 4 | 1 |
| Tall | 1 | 4 | 1 | 0 | 6 | 2 | 4 | 2 | 4 |
| Female | 1 | 2 | 1 | 2 | 2 | 4 | 0 | 2 | 2 |
| Male | 2 | 4 | 1 | 3 | 4 | 0 | 7 | 4 | 3 |
| Old | 1 | 3 | 2 | 4 | 2 | 2 | 4 | 6 | 0 |
| Young | 2 | 3 | 0 | 1 | 4 | 2 | 3 | 0 | 5 |
This Burt table is composed of all pairs of crosstabulations among the variables Hair, Height, Sex, and Age. It is composed of sixteen individual subtables—the number of variables squared. Both the rows and the columns have the same
nine categories (in this case Blond, Brown, White, Short, Tall, Female, Male, Old, and Young). Below the diagonal (from left
to right, top to bottom) are the following crosstabulations: Height * Hair, Sex * Hair, Sex * Height, Age * Hair, Age * Height, and Age * Sex. Each crosstabulation below the diagonal has a transposed counterpart above the diagonal. The diagonal contains the crosstabulations:
Hair * Hair, Height * Height, Sex * Sex, and Age * Age. The diagonal elements of the diagonal partitions contain marginal frequencies of the off-diagonal partitions. The table
Hair * Height, for example, has three rows for Hair and two columns for Height. The values of the Hair * Height table, summed across rows, sum to the diagonal values of the Height * Height table, as displayed in the following results. The following statements produce Figure 34.7.
proc corresp data=neighbor observed short dimens=1; title2 'Part of the Burt Table'; ods output observed=o; tables Hair Height, Height; run; proc print data=o(drop=sum) label noobs; where label ne 'Sum'; label label = '00'x; run;
Figure 34.7: Part of the Burt Table
A simple crosstabulation of Hair 
Height is  . Tables such as (
. Tables such as ( ), made up of several crosstabulations, can also be analyzed in simple correspondence analysis. The following statements produce
Figure 34.8.
), made up of several crosstabulations, can also be analyzed in simple correspondence analysis. The following statements produce
Figure 34.8.
proc corresp data=neighbor observed short dimens=1; title2 'Multiple Crosstabulations'; ods select observed; tables Hair, Height Sex; run;
Figure 34.8: Hair (Height Sex) Crosstabulation
The following statements create a table with six rows (Blond*Short, Blond*Tall, Brown*Short, Brown*Tall, White*Short, and White*Tall) and four columns (Female, Male, Old, and Young). The levels of the row variables are crossed by the CROSS=ROW option, forming mutually exclusive categories. Hence each individual fits into exactly one row category, but two column categories. The following statements produce Figure 34.9.
proc corresp data=Neighbor cross=row observed short; title2 'Multiple Crosstabulations with Crossed Rows'; ods select observed; tables Hair Height, Sex Age; run;
Figure 34.9: Contingency Table for Hair * Height, Sex Age
You can enter supplementary variables with TABLES input by including a SUPPLEMENTARY statement. Variables named in the SUPPLEMENTARY
statement indicate TABLES variables with categories that are supplementary. In other words, the categories of the variable
Age are represented in the row and column space, but they are not used in determining the scores of the categories of the variables
Hair, Height, and Sex. The variable used in the SUPPLEMENTARY statement must be listed in the TABLES statement as well. For example, the following
statements create a Burt table with seven active rows and columns (Blond, Brown, White, Short, Tall, Female, Male) and two supplementary rows and columns (Old and Young). The following statements produce Figure 34.10.
proc corresp data=Neighbor observed short mca; title2 'MCA with Supplementary Variables'; ods select burt supcols; tables Hair Height Sex Age; supplementary Age; run;
Figure 34.10: Burt Table from PROC CORRESP with Supplementary Variables
The following statements create a binary table with 7 active columns (Blond, Brown, White, Short, Tall, Female, Male), 2 supplementary columns (Old and Young), and 11 rows for the 11 observations with nonmissing values. The following statements produce Figure 34.11.
proc corresp data=Neighbor observed short binary; title2 'Supplementary Binary Variables'; ods select binary supcols; tables Hair Height Sex Age; supplementary Age; run;
Figure 34.11: Binary Table from PROC CORRESP with Supplementary Variables
| PROC CORRESP Table Construction |
| Supplementary Binary Variables |
| Binary Table | |||||||
|---|---|---|---|---|---|---|---|
| Blond | Brown | White | Short | Tall | Female | Male | |
| 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
| 2 | 0 | 1 | 0 | 0 | 1 | 1 | 0 |
| 3 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 4 | 0 | 0 | 1 | 0 | 1 | 1 | 0 |
| 5 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| 6 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 7 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
| 8 | 1 | 0 | 0 | 1 | 0 | 0 | 1 |
| 9 | 1 | 0 | 0 | 1 | 0 | 1 | 0 |
| 10 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
| 11 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |