The CANDISC Procedure

Computational Details
General Formulas
Canonical discriminant analysis is equivalent to canonical correlation analysis between the quantitative variables and a set
of dummy variables coded from the CLASS variable. In the following notation, the dummy variables are denoted by 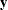 and the quantitative variables are denoted by
and the quantitative variables are denoted by  . The total sample covariance matrix for the and variables is
. The total sample covariance matrix for the and variables is
![\[ \mb{S} = \left[\begin{matrix} \mb{S}_{xx} & \mb{S}_{xy} \cr \mb{S}_{yx} & \mb{S}_{yy} \end{matrix}\right] \]](images/statug_candisc0008.png)
When c is the number of groups, 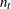 is the number of observations in group t, and
is the number of observations in group t, and 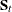 is the sample covariance matrix for the variables in group t, the within-class pooled covariance matrix for the variables is
is the sample covariance matrix for the variables in group t, the within-class pooled covariance matrix for the variables is
![\[ \mb{S}_ p = \frac{1}{\sum n_ t-c} {\sum (n_ t-1)\mb{S}_ t} \]](images/statug_candisc0011.png)
The canonical correlations, 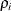 , are the square roots of the eigenvalues,
, are the square roots of the eigenvalues, 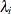 , of the following matrix. The corresponding eigenvectors are
, of the following matrix. The corresponding eigenvectors are 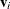 .
.
![\[ {\mb{S}_ p}^{-1/2}\mb{S}_{xy}{\mb{S}_{yy}}^{-1}\mb{S}_{yx}{\mb{S}_ p}^{-1/2} \]](images/statug_candisc0015.png)
Let 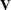 be the matrix that contains the eigenvectors that correspond to nonzero eigenvalues as columns. The raw canonical coefficients are calculated as follows:
be the matrix that contains the eigenvectors that correspond to nonzero eigenvalues as columns. The raw canonical coefficients are calculated as follows:
![\[ \mb{R} = {\mb{S}_ p}^{-1/2}\mb{V} \]](images/statug_candisc0017.png)
The pooled within-class standardized canonical coefficients are
![\[ \mb{P} = \mr{diag}(\mb{S}_ p)^{1/2}\mb{R} \]](images/statug_candisc0018.png)
The total sample standardized canonical coefficients are
![\[ \mb{T} = \mr{diag}(\mb{S}_{xx})^{1/2}\mb{R} \]](images/statug_candisc0019.png)
Let 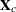 be the matrix that contains the centered variables as columns. The canonical scores can be calculated by any of the following:
be the matrix that contains the centered variables as columns. The canonical scores can be calculated by any of the following:
![\[ \mb{X}_ c \, \mb{R} \]](images/statug_candisc0021.png)
![\[ \mb{X}_ c \, \mr{diag}(\mb{S}_ p)^{-1/2}\mb{P} \]](images/statug_candisc0022.png)
![\[ \mb{X}_ c \, \mr{diag}(\mb{S}_{xx})^{-1/2}\mb{T} \]](images/statug_candisc0023.png)
For the multivariate tests based on 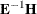 ,
,
![\[ \mb{E} = (n-1)(\mb{S}_{yy} - \mb{S}_{yx}\mb{S}_{xx}^{-1}\mb{S}_{xy}) \]](images/statug_candisc0025.png)
![\[ \mb{H} = (n-1)\mb{S}_{yx}\mb{S}_{xx}^{-1}\mb{S}_{xy} \]](images/statug_candisc0026.png)
where n is the total number of observations.