The CANDISC Procedure

The iris data that were published by Fisher (1936) have been widely used for examples in discriminant analysis and cluster analysis. The sepal length, sepal width, petal length,
and petal width are measured in millimeters in 50 iris specimens from each of three species: Iris setosa, I. versicolor, and I. virginica. The iris data set is available from the Sashelp library.
This example is a canonical discriminant analysis that creates an output data set that contains scores on the canonical variables and plots the canonical variables.
The following statements produce Output 31.1.1 through Output 31.1.6:
title 'Fisher (1936) Iris Data'; proc candisc data=sashelp.iris out=outcan distance anova; class Species; var SepalLength SepalWidth PetalLength PetalWidth; run;
PROC CANDISC first displays information about the observations and the classes in the data set in Output 31.1.1.
The DISTANCE option in the PROC CANDISC statement displays squared Mahalanobis distances between class means. Results from the DISTANCE option are shown in Output 31.1.2.
Output 31.1.3 displays univariate and multivariate statistics. The ANOVA option uses univariate statistics to test the hypothesis that
the class means are equal. The resulting R-square values range from 0.4008 for SepalWidth to 0.9414 for PetalLength, and each variable is significant at the 0.0001 level. The multivariate test for differences between the classes (which is
displayed by default) is also significant at the 0.0001 level; you would expect this from the highly significant univariate
test results.
Output 31.1.3: Iris Data: Univariate and Multivariate Statistics
| Fisher (1936) Iris Data |
| Univariate Test Statistics | ||||||||
|---|---|---|---|---|---|---|---|---|
| F Statistics, Num DF=2, Den DF=147 | ||||||||
| Variable | Label | Total Standard Deviation |
Pooled Standard Deviation |
Between Standard Deviation |
R-Square | R-Square / (1-RSq) |
F Value | Pr > F |
| SepalLength | Sepal Length (mm) | 8.2807 | 5.1479 | 7.9506 | 0.6187 | 1.6226 | 119.26 | <.0001 |
| SepalWidth | Sepal Width (mm) | 4.3587 | 3.3969 | 3.3682 | 0.4008 | 0.6688 | 49.16 | <.0001 |
| PetalLength | Petal Length (mm) | 17.6530 | 4.3033 | 20.9070 | 0.9414 | 16.0566 | 1180.16 | <.0001 |
| PetalWidth | Petal Width (mm) | 7.6224 | 2.0465 | 8.9673 | 0.9289 | 13.0613 | 960.01 | <.0001 |
| Multivariate Statistics and F Approximations | |||||
|---|---|---|---|---|---|
| S=2 M=0.5 N=71 | |||||
| Statistic | Value | F Value | Num DF | Den DF | Pr > F |
| Wilks' Lambda | 0.02343863 | 199.15 | 8 | 288 | <.0001 |
| Pillai's Trace | 1.19189883 | 53.47 | 8 | 290 | <.0001 |
| Hotelling-Lawley Trace | 32.47732024 | 582.20 | 8 | 203.4 | <.0001 |
| Roy's Greatest Root | 32.19192920 | 1166.96 | 4 | 145 | <.0001 |
| NOTE: F Statistic for Roy's Greatest Root is an upper bound. | |||||
| NOTE: F Statistic for Wilks' Lambda is exact. | |||||
Output 31.1.4 displays canonical correlations and eigenvalues. The R square between Can1 and the CLASS variable, 0.969872, is much larger than the corresponding R square for Can2, 0.222027.
Output 31.1.4: Iris Data: Canonical Correlations and Eigenvalues
| Fisher (1936) Iris Data |
| Canonical Correlation |
Adjusted Canonical Correlation |
Approximate Standard Error |
Squared Canonical Correlation |
Eigenvalues of Inv(E)*H = CanRsq/(1-CanRsq) |
Test of H0: The canonical correlations in the current row and all that follow are zero | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Eigenvalue | Difference | Proportion | Cumulative | Likelihood Ratio |
Approximate F Value |
Num DF | Den DF | Pr > F | |||||
| 1 | 0.984821 | 0.984508 | 0.002468 | 0.969872 | 32.1919 | 31.9065 | 0.9912 | 0.9912 | 0.02343863 | 199.15 | 8 | 288 | <.0001 |
| 2 | 0.471197 | 0.461445 | 0.063734 | 0.222027 | 0.2854 | 0.0088 | 1.0000 | 0.77797337 | 13.79 | 3 | 145 | <.0001 | |
Output 31.1.5 displays correlations between canonical and original variables.
Output 31.1.6 displays canonical coefficients. The raw canonical coefficients for the first canonical variable, Can1, show that the classes differ most widely on the linear combination of the centered variables: ![]() .
.
Output 31.1.6: Iris Data: Canonical Coefficients
| Fisher (1936) Iris Data |
| Total-Sample Standardized Canonical Coefficients | |||
|---|---|---|---|
| Variable | Label | Can1 | Can2 |
| SepalLength | Sepal Length (mm) | -0.686779533 | 0.019958173 |
| SepalWidth | Sepal Width (mm) | -0.668825075 | 0.943441829 |
| PetalLength | Petal Length (mm) | 3.885795047 | -1.645118866 |
| PetalWidth | Petal Width (mm) | 2.142238715 | 2.164135931 |
| Pooled Within-Class Standardized Canonical Coefficients | |||
|---|---|---|---|
| Variable | Label | Can1 | Can2 |
| SepalLength | Sepal Length (mm) | -.4269548486 | 0.0124075316 |
| SepalWidth | Sepal Width (mm) | -.5212416758 | 0.7352613085 |
| PetalLength | Petal Length (mm) | 0.9472572487 | -.4010378190 |
| PetalWidth | Petal Width (mm) | 0.5751607719 | 0.5810398645 |
Output 31.1.7 displays class level means on canonical variables.
The TEMPLATE and SGRENDER procedures are used to create a plot of the first two canonical variables. The following statements produce Output 31.1.8:
proc template;
define statgraph scatter;
begingraph / attrpriority=none;
entrytitle 'Fisher (1936) Iris Data';
layout overlayequated / equatetype=fit
xaxisopts=(label='Canonical Variable 1')
yaxisopts=(label='Canonical Variable 2');
scatterplot x=Can1 y=Can2 / group=species name='iris'
markerattrs=(size=3px);
layout gridded / autoalign=(topright topleft);
discretelegend 'iris' / border=false opaque=false;
endlayout;
endlayout;
endgraph;
end;
run;
proc sgrender data=outcan template=scatter;
run;
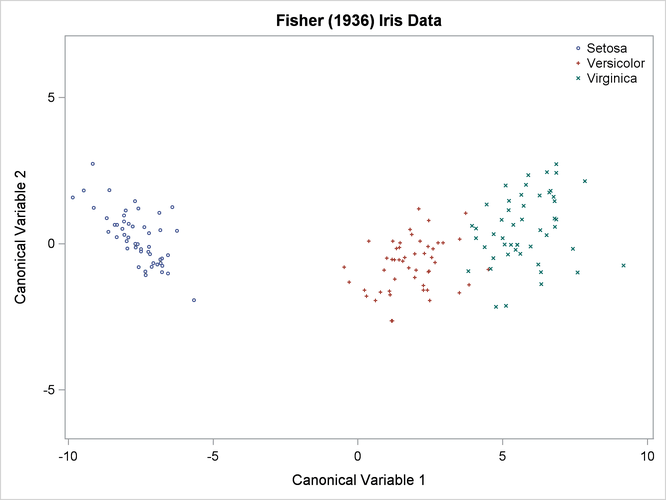
The plot of canonical variables in Output 31.1.8 shows that of the two canonical variables, Can1 has more discriminatory power.