The ACECLUS Procedure

The following example demonstrates how you can use the ACECLUS procedure to obtain approximate estimates of the pooled within-cluster covariance matrix and to compute canonical variables for subsequent analysis. You use PROC ACECLUS to preprocess data before you cluster it by using the FASTCLUS or CLUSTER procedure.
Suppose you want to determine whether national figures for birth rates, death rates, and infant death rates can be used to determine certain types or categories of countries. You want to perform a cluster analysis to determine whether the observations can be formed into groups suggested by the data. Previous studies indicate that the clusters computed from this type of data can be elongated and elliptical. Thus, you need to perform a linear transformation on the raw data before the cluster analysis.
The following data[22] from Rouncefield (1995) are the birth rates, death rates, and infant death rates for 97 countries. The following statements create the SAS data
set Poverty:
data poverty; input Birth Death InfantDeath Country &$20. @@; datalines; 24.7 5.7 30.8 Albania 12.5 11.9 14.4 Bulgaria 13.4 11.7 11.3 Czechoslovakia 12 12.4 7.6 Former E. Germany ... more lines ... 41.7 10.3 66 Zimbabwe ;
The data set Poverty contains the character variable Country and the numeric variables Birth, Death, and InfantDeath, which represent the birth rate per thousand, death rate per thousand, and infant death rate per thousand, respectively.
The $20. format in the INPUT statement specifies that the variable Country is a character variable with a length of 20. The preceding & enables the reading of blanks in the middle of the country names.
The double trailing at sign (@@) in the INPUT statement specifies that observations are input from each line until all values
have been read.
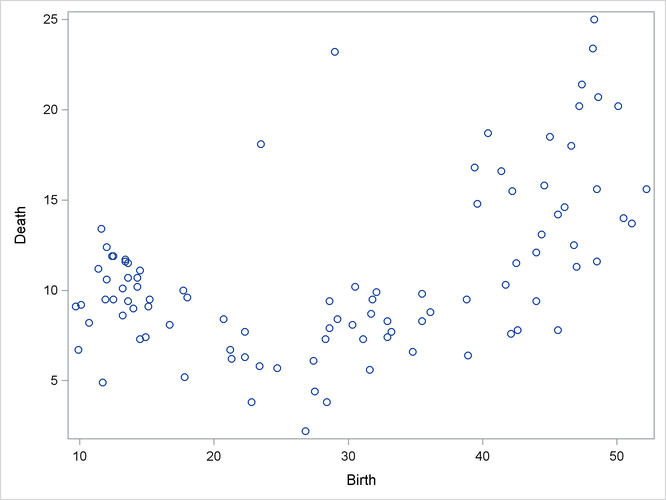
It is often useful when beginning a cluster analysis to look at the data graphically. The following statements use the SGPLOT
procedure to make a scatter plot of the variables Birth and Death.
proc sgplot data=poverty; scatter y=Death x=Birth; run;
The plot, displayed in Figure 24.1, indicates the difficulty of dividing the points into clusters. Plots of the other variable pairs (not shown) display similar characteristics. The clusters that comprise these data might be poorly separated and elongated. Data with poorly separated or elongated clusters must be transformed.
If you know the within-cluster covariances, you can transform the data to make the clusters spherical. However, since you do not know what the clusters are, you cannot calculate exactly the within-cluster covariance matrix. The ACECLUS procedure estimates the within-cluster covariance matrix to transform the data, even when you have no knowledge of cluster membership or the number of clusters.
The following statements perform the ACECLUS procedure transformation by using the SAS data set Poverty:
proc aceclus data=poverty out=ace proportion=.03; var Birth Death InfantDeath; run;
The OUT= option creates an output data set called Ace to contain the canonical variable scores. The PROPORTION= option specifies that approximately 3 percent of the pairs are
included in the estimation of the within-cluster covariance matrix. The VAR statement specifies that the variables Birth, Death, and InfantDeath are used in computing the canonical variables.
The results of this analysis are displayed in Figure 24.2 through Figure 24.5.
Figure 24.2 displays the number of observations, the number of variables, and the settings for the PROPORTION and CONVERGE options. The PROPORTION option is set at 0.03, as specified in the previous statements. The CONVERGE parameter is set at its default value of 0.001. Figure 24.2 next displays the means, standard deviations, and sample covariance matrix of the analytical variables.
The type of matrix used for the initial within-cluster covariance estimate is displayed in Figure 24.3. In this example, that initial estimate is the full covariance matrix. The threshold value that corresponds to the PROPORTION=0.03 setting is given as 0.292815.
Figure 24.3: Table of Iteration History from the ACECLUS Procedure
| Iteration History | ||||
|---|---|---|---|---|
| Iteration | RMS Distance |
Distance Cutoff |
Pairs Within Cutoff |
Convergence Measure |
| 1 | 2.449 | 0.717 | 385.0 | 0.552025 |
| 2 | 12.534 | 3.670 | 446.0 | 0.008406 |
| 3 | 12.851 | 3.763 | 521.0 | 0.009655 |
| 4 | 12.882 | 3.772 | 591.0 | 0.011193 |
| 5 | 12.716 | 3.723 | 628.0 | 0.008784 |
| 6 | 12.821 | 3.754 | 658.0 | 0.005553 |
| 7 | 12.774 | 3.740 | 680.0 | 0.003010 |
| 8 | 12.631 | 3.699 | 683.0 | 0.000676 |
Figure 24.3 displays the iteration history. For each iteration, PROC ACECLUS displays the following measures:
-
root mean square distance between all pairs of observations
-
distance cutoff for including pairs of observations in the estimate of within-cluster covariances (equal to RMS*Threshold)
-
number of pairs within the cutoff
-
convergence measure
Figure 24.4 displays the approximate within-cluster covariance matrix and the table of eigenvalues from the canonical analysis. The first column of the eigenvalues table contains numbers for the eigenvectors. The next column of the table lists the eigenvalues of Inv(ACE)*(COV-ACE).
The next three columns of the eigenvalue table (Figure 24.4) display measures of the relative size and importance of the eigenvalues. The first column lists the difference between each eigenvalue and its successor. The last two columns display the individual and cumulative proportions that each eigenvalue contributes to the total sum of eigenvalues.
The raw and standardized canonical coefficients are displayed in Figure 24.5. The coefficients are standardized by multiplying the raw coefficients with the standard deviation of the associated variable.
The ACECLUS procedure uses these standardized canonical coefficients to create the transformed canonical variables, which
are the linear transformations of the original input variables, Birth, Death, and InfantDeath.
The following statements invoke the CLUSTER procedure, using the SAS data set Ace created in the previous ACECLUS procedure:
proc cluster data=ace outtree=tree noprint method=ward; var can1 can2 can3 ; copy Birth--Country; run;
The OUTTREE= option creates the output SAS data set Tree that is used in a subsequent step to display cluster membership. The NOPRINT option suppresses the display of the output.
The METHOD= option specifies Ward’s minimum-variance clustering method.
The VAR statement specifies that the canonical variables computed in the ACECLUS procedure are used in the cluster analysis.
The COPY statement specifies that all the variables from the SAS data set Poverty (Birth—Country) are added to the output data set Tree.
The following statements use PROC TREE to create an output SAS data set called New. The NCLUSTERS= option specifies the number of clusters desired in the SAS data set New. The NOPRINT option suppresses the display of the output.
proc tree data=tree out=new nclusters=3 noprint; copy Birth Death InfantDeath can1 can2 ; id Country; run;
The COPY statement copies the canonical variables Can1 and Can2 (computed in the preceding ACECLUS procedure) and the original analytical variables Birth, Death, and InfantDeath into the output SAS data set New.
The following statements invoke the SGPLOT procedure, using the SAS data set created by PROC TREE:
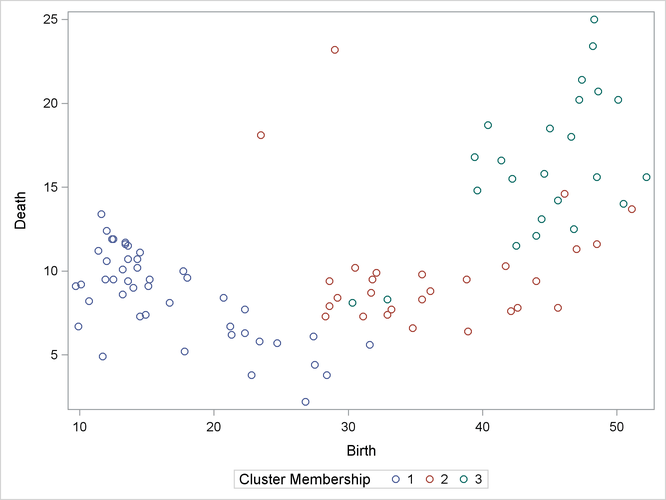
proc sgplot data=new; scatter y=Death x=Birth / group=cluster; keylegend / title="Cluster Membership"; run;
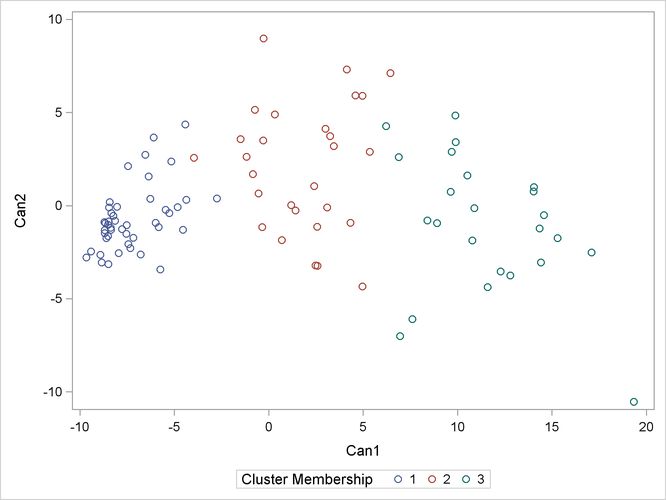
proc sgplot data=new; scatter y=can2 x=can1 / group=cluster; keylegend / title="Cluster Membership"; run;
The first PROC SGPLOT statement requests a scatter plot of the two variables Birth and Death, using the variable CLUSTER as the identification variable.
The second PROC SGPLOT statement requests a plot of the two canonical variables, using the value of the variable CLUSTER as the identification variable.
Figure 24.6 and Figure 24.7 display the separation of the clusters when three clusters are calculated.
[22] These data have been compiled from the United Nations Demographic Yearbook 1990 (United Nations publications, Sales No. E/F.91.XII.1, copyright 1991, United Nations, New York) and are reproduced with the permission of the United Nations.