The ROBUSTREG Procedure

PROC ROBUSTREG <options> ;
The PROC ROBUSTREG statement invokes the ROBUSTREG procedure. Table 84.1 summarizes the options available in the PROC ROBUSTREG statement.
Table 84.1: PROC ROBUSTREG Statement Options
|
Option |
Description |
|---|---|
|
Saves the estimated covariance matrix |
|
|
Specifies the input SAS data set |
|
|
Computes the final weighted least squares estimates |
|
|
Specifies an input SAS data set that contains initial estimates |
|
|
Displays the iteration history of the iteratively reweighted least squares algorithm |
|
|
Specifies the estimation method |
|
|
Specifies the length of effect names |
|
|
Specifies the order in which to sort classification variables |
|
|
Specifies an output SAS data set that contains the parameter estimates |
|
|
Specifies options that control details of the plots |
|
|
Specifies the seed for the random number generator |
You can specify the following options in the PROC ROBUSTREG statement.
When you specify METHOD=LTS <(options)>, you can specify the following options:
When you specify METHOD=S <(options)>, you can specify the following options:
- ASYMPCOV=H1 | H2 | H3 | H4
-
specifies the type of asymptotic covariance that is computed for the S estimate. The four types are described in the section Asymptotic Covariance and Confidence Intervals. By default, ASYMPCOV=H4.
- CHIF= TUKEY | YOHAI
-
specifies the
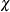 function for the S estimate. PROC ROBUSTREG provides
two functions, Tukey’s bisquare function and Yohai’s optimal function, which you can request by specifying CHIF=TUKEY and CHIF=YOHAI,
respectively. The default is Tukey’s bisquare function.
function for the S estimate. PROC ROBUSTREG provides
two functions, Tukey’s bisquare function and Yohai’s optimal function, which you can request by specifying CHIF=TUKEY and CHIF=YOHAI,
respectively. The default is Tukey’s bisquare function.
- EFF=value
-
specifies the efficiency (as a fraction) of the S estimate. The parameter
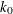 in the function is determined by this efficiency. The default efficiency is determined such that the consistent S estimate has a
breakdown value of 25%. This option is overwritten by the K0= option if both options are used.
in the function is determined by this efficiency. The default efficiency is determined such that the consistent S estimate has a
breakdown value of 25%. This option is overwritten by the K0= option if both options are used.
- K0=value
-
specifies the
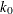 parameter in the function of the S estimate.
If you specify CHIF=TUKEY, the default is 1.548. If you specify CHIF=YOHAI, the default is 0.66. These default values correspond
to a 50% breakdown value of the consistent S estimate.
parameter in the function of the S estimate.
If you specify CHIF=TUKEY, the default is 1.548. If you specify CHIF=YOHAI, the default is 0.66. These default values correspond
to a 50% breakdown value of the consistent S estimate.
- MAXITER=n
-
sets the maximum number of iterations for computing the scale parameter of the S estimate. By default, MAXITER=1000.
- NREP=n
-
specifies the number of repeats of subsampling in the computation of the S estimate. For information about how the default number of repeats is determined, see the section Algorithm.
- NOREFINE
-
suppresses the refinement of the S estimate. For more information, see the section Algorithm.
- SUBSETSIZE=n
-
specifies the size of the subset for the S estimate. For information about how the default value is determined, see the section Algorithm.
- TOLERANCE=value
-
specifies the tolerance for the S estimate of the scale. The default value is 0.001.
When you specify METHOD=MM <(options)>, you can specify the following options:
- ASYMPCOV=H1 | H2 | H3 | H4
-
specifies the type of asymptotic covariance that is computed for the MM estimate. The four types are described in the section Details: ROBUSTREG Procedure. By default, ASYMPCOV=H4.
- BIASTEST <(ALPHA=number)>
-
requests the bias test for the final MM estimate. For more information about this test, see the section Bias Test.
- CHIF=TUKEY | YOHAI
-
selects the
function for the MM estimate. PROC ROBUSTREG provides
two functions, Tukey’s bisquare function and Yohai’s optimal function, which you can request by specifying CHIF=TUKEY and CHIF=YOHAI,
respectively. The default is Tukey’s bisquare function. This function is also used by the initial S estimate if you specify the INITEST=S option.
- CONVERGENCE=criterion <(EPS=number)>
-
specifies a convergence criterion for the MM estimate. Table 84.7 lists the three criteria that are available.
Table 84.7: Options to Specify Convergence Criteria
Type
Option
Coefficient
CONVERGENCE=COEF
Residual
CONVERGENCE=RESID
Weight
CONVERGENCE=WEIGHT
By default, CONVERGENCE=COEF. You can specify the precision of the convergence criterion by using the EPS= option; by default, EPS=1E–8.
- EFF=value
-
specifies the efficiency (as a fraction) of the MM estimate. The parameter
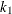 in the function is determined by this efficiency. The default efficiency is set to 0.85, which corresponds to
in the function is determined by this efficiency. The default efficiency is set to 0.85, which corresponds to 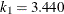 if you specify CHIF=TUKEY or
if you specify CHIF=TUKEY or 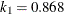 if you specify CHIF=YOHAI.
if you specify CHIF=YOHAI.
- INITEST=LTS | S
-
specifies the initial estimator for the MM estimator. By default, the LTS estimator with its default settings is used as the initial estimator for the MM estimator.
- INITH=h
-
specifies the integer h for the initial LTS estimate that is used by the MM estimator. For information about how to specify h and how the default is determined, see the section Algorithm.
- K0=number
-
specifies the parameter
in the function for the MM estimate.
If you specify CHIF=TUKEY, the default is 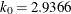 . If you specify CHIF=YOHAI, the default is
. If you specify CHIF=YOHAI, the default is 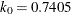 . These default values correspond to the 25% breakdown value of the MM estimator.
. These default values correspond to the 25% breakdown value of the MM estimator.
- MAXITER=n
-
sets the maximum number of iterations during the parameter estimation. By default, MAXITER=1000.