The FMM Procedure (Experimental)

Latent Variables via Data Augmentation
In order to fit finite Bayesian mixture models, the FMM procedure treats the mixture model as a missing data problem and introduces an assignment variable 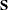 as in Dempster, Laird, and Rubin (1977). Since is not observable, it is frequently referred to as a latent variable. The unobservable variable assigns an observation to a component in the mixture model. The number of states,
as in Dempster, Laird, and Rubin (1977). Since is not observable, it is frequently referred to as a latent variable. The unobservable variable assigns an observation to a component in the mixture model. The number of states, 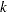 , might be unknown, but it is known to be finite. Conditioning on the latent variable , the component memberships of each observation is assumed to be known, and Bayesian estimation is straightforward for each component in the finite mixture model. That is, conditional on
, might be unknown, but it is known to be finite. Conditioning on the latent variable , the component memberships of each observation is assumed to be known, and Bayesian estimation is straightforward for each component in the finite mixture model. That is, conditional on 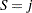 , the distribution of the response is now assumed to be
, the distribution of the response is now assumed to be 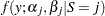 . In other words, each distinct state of the random variable leads to a distinct set of parameters. The parameters in each component individually are then updated using a conjugate Gibbs sampler (where available) or a Metropolis-Hastings sampling algorithm.
. In other words, each distinct state of the random variable leads to a distinct set of parameters. The parameters in each component individually are then updated using a conjugate Gibbs sampler (where available) or a Metropolis-Hastings sampling algorithm.
The FMM procedure assumes that the random variable has a discrete multinomial distribution with probability 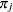 of belonging to a component
of belonging to a component 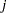 ; it can occupy one of states. The distribution for the latent variable is
; it can occupy one of states. The distribution for the latent variable is
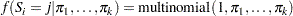 |
where 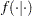 denotes a conditional probability density. The parameters in the density denote the probability that
denotes a conditional probability density. The parameters in the density denote the probability that 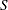 takes on state .
takes on state .
The FMM procedure assumes a conjugate Dirichlet prior distribution on the mixture proportions written as:
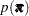 |
 |
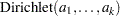 |
where 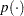 indicates a prior distribution.
indicates a prior distribution.
Using Bayes’ theorem, the likelihood function and prior distributions determine a conditionally conjugate posterior distribution of and 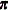 from the multinominomial distribution and Dirichlet distribution, respectively.
from the multinominomial distribution and Dirichlet distribution, respectively.