| The MODECLUS Procedure |
| Output Data Sets |
The OUT= data set contains one complete copy of the input data set for each cluster solution. There are additional variables identifying each solution and giving information about individual observations. Solutions with only one remaining cluster when JOIN=p is specified are omitted from the OUT= data set (see the description of the JOIN= option). The OUT= data set can be extremely large, so it is advisable to specify the DROP= data set option to exclude unnecessary variables.
The OUTCLUS= or OUTC= data set contains one observation for each cluster in each cluster solution. The variables identify the solution and provide statistics describing the cluster.
The OUTSUM= or OUTS= data set contains one observation for each cluster solution. The variables identify the solution and provide information about the solution as a whole.
The following variables can appear in all of the output data sets:
_K_, which is the value of the K= option for the current solution. This variable appears only if you specify the K= option.
_DK_, which is the value of the DK= option for the current solution. This variable appears only if you specify the DK= option.
_CK_, which is the value of the CK= option for the current solution. This variable appears only if you specify the CK= option.
_R_, which is the value of the R= option for the current solution. This variable appears only if you specify the R= option.
_DR_, which is the value of the DR= option for the current solution. This variable appears only if you specify the DR= option.
_CR_, which is the value of the CR= option for the current solution. This variable appears only if you specify the CR= option.
_CASCAD_, which is the number of times the density estimates have been cascaded for the current solution. This variable appears only if you specify the CASCADE= option.
_METHOD_, which is the value of the METHOD= option for the current solution. This variable appears only if you specify the METHOD= option.
_NJOIN_, which is the number of clusters that are joined or dissolved in the current solution. This variable appears only if you specify the JOIN option.
_LOCAL_, which is the local dimensionality estimate of the observation. This variable appears only if you specify the LOCAL option.
The OUT= data set contains the following variables:
the variables from the input data set
_OBS_, which is the observation number from the input data set. This variable appears only if you omit the ID statement.
DENSITY, which is the estimated density at the observation. This variable can be renamed by the DENSITY= option.
CLUSTER, which is the number of the cluster to which the observation is assigned. This variable can be renamed by the CLUSTER= option.
The OUTCLUS= data set contains the following variables:
the BY variables, if any
_NCLUS_, which is the number of clusters in the solution
CLUSTER, which is the number of the current cluster
_FREQ_, which is the number of observations in the cluster
_MODE_, which is the maximum estimated density in the cluster
_BFREQ_, which is the number of observations in the cluster with neighbors belonging to a different cluster
_SADDLE_, which is the estimated saddle density for the cluster
_MC_, which is the number of observations within the fixed-radius density-estimation neighborhood of the modal observation. This variable appears only if you specify the TEST or JOIN option.
_SC_, which is the number of observations within the fixed-radius density-estimation neighborhood of the saddle observation. This variable appears only if you specify the TEST or JOIN option.
_OC_, which is the number of observations within the overlap of the two previous neighborhoods. This variable appears only if you specify the TEST or JOIN option.
_Z_, which is the approximate z statistic for the cluster. This variable appears only if you specify the TEST or JOIN option.
_P_, which is the approximate
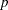 -value for the cluster. This variable appears only if you specify the TEST or JOIN option.
-value for the cluster. This variable appears only if you specify the TEST or JOIN option.
The OUTSUM= data set contains the following variables:
the BY variables, if any
_NCLUS_, which is the number of clusters in the solution
_UNCL_, which is the number of unclassified observations
_CROSS_, which is the likelihood cross validation criterion if you specify the CROSS or CROSSLIST option
Copyright © SAS Institute, Inc. All Rights Reserved.