| The MI Procedure |
| Missing Data Patterns |
The MI procedure sorts the data into groups based on whether the analysis variables are observed or missing. Note that the input data set does not need to be sorted in any order.
For example, with variables 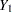 ,
, 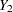 , and
, and 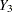 (in that order) in a data set, up to eight groups of observations can be formed from the data set. Figure 54.6 displays the eight groups of observations and an unique missing pattern for each group:
(in that order) in a data set, up to eight groups of observations can be formed from the data set. Figure 54.6 displays the eight groups of observations and an unique missing pattern for each group:
Here, an "X" means that the variable is observed in the corresponding group and a "." means that the variable is missing.
The variable order is used to derive the order of the groups from the data set, and thus determines the order of missing values in the data to be imputed. If you specify a different order of variables in the VAR statement, then the results are different even if the other specifications remain the same.
A data set with variables , , ..., 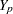 (in that order) is said to have a monotone missing pattern when the event that a variable
(in that order) is said to have a monotone missing pattern when the event that a variable 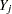 is missing for a particular individual implies that all subsequent variables
is missing for a particular individual implies that all subsequent variables 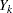 ,
, 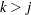 , are missing for that individual. Alternatively, when a variable is observed for a particular individual, it is assumed that all previous variables ,
, are missing for that individual. Alternatively, when a variable is observed for a particular individual, it is assumed that all previous variables , 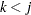 , are also observed for that individual.
, are also observed for that individual.
For example, Figure 54.7 displays a data set of three variables with a monotone missing pattern.
Figure 54.8 displays a data set of three variables with a non-monotone missing pattern.
A data set with an arbitrary missing pattern is a data set with either a monotone missing pattern or a non-monotone missing pattern.
Copyright © SAS Institute, Inc. All Rights Reserved.