| The DISTANCE Procedure |
| VAR Statement |
- VAR level ( variables < / opt-list> )
< level ( variables < / opt-list> ) ...level ( variables < / opt-list> ) > ;
where the syntax for the opt-list is as follows:
ABSENT=value
MISSING=miss-method | value
ORDER=order-option
STD=std-method
WEIGHTS=weight-list
The VAR statement lists variables from which distances are to be computed. The VAR statement is required. The variables can be numeric or character depending on their measurement levels. A variable cannot appear more than once in either the same list or a different list.
level is required. It declares the levels of measurement for those variables specified within the parentheses. Available values for level are as follows:
- ANOMINAL
variables are asymmetric nominal and can be either numeric or character.
- NOMINAL
variables are symmetric nominal and can be either numeric or character.
- ORDINAL
variables are ordinal and can be either numeric or character. Values of ordinal variables are replaced by their corresponding rank scores. If standardization is required, the standardized rank scores are output to the data set specified in the OUTSDZ= option. See the RANKSCORE= option in the PROC DISTANCE statement for methods available for assigning rank scores to ordinal variables. After being replaced by scores, ordinal variables are considered interval.
- INTERVAL
variables are interval and numeric.
- RATIO
variables are ratio and numeric. Ratio variables should always contain positive measurements.
Each variable list can be followed by an option list. Use "/ " after the list of variables to start the option list. An option list contains options that are applied to the variables. The following options are available in the option list:
- ABSENT=
specifies the value to be used as an absence value in an irrelevant absent-absent match for asymmetric nominal variables.
- MISSING=
specifies the method (or numeric value) with which to replace missing data.
- ORDER=
selects the order for assigning scores to ordinal variables.
- STD=
selects the standardization method.
- WEIGHTS=
assigns weights to the variables in the list.
If an option is missing from the current attribute list, PROC DISTANCE provides default values for all the variables in the current list.
For example, in the VAR statement
var ratio(x1-x4/std= mad weights= .5 .5 .1 .5 missing= -99)
interval(x5/std= range)
ordinal(x6/order= desc);
the first option list defines x1–x4 as ratio variables to be standardized by the MAD method. Also, any missing values in x1–x4 should be replaced by –99. x1 is given a weight of 0.5, x2 is given a weight of 0.5, x3 is given a weight of 0.1, and x4 is given a weight of 0.5.
The second option list defines x5 as an interval variable to be standardized by the RANGE method. If the REPLACE option is specified in the PROC DISTANCE statement, missing values in x5 are replaced by the location estimate from the RANGE method. By default, x5 is given a weight of 1.
The last option list defines x6 as an ordinal variable. The scores are assigned from highest to lowest by its unformatted values. Although the STD= option is not specified, x6 is standardized by the default method (STD) because there is more than one level of measurements (ratio, interval, and ordinal) in the VAR statement. Again, if the REPLACE option is specified, missing values in x6 are replaced by the location estimate from the STD method. Finally, by default, x6 is given a weight of 1.
More details for the options are explained as follows.
- STD=std-method
specifies the standardization method. Valid values for std-method are MEAN, MEDIAN, SUM, EUCLEN, USTD, STD, RANGE, MIDRANGE, MAXABS, IQR, MAD, ABW, AHUBER, AWAVE, AGK, SPACING, and L. Table 32.9 lists available methods of standardization as well as their corresponding location and scale measures.
Table 32.9 Available Standardization Methods Method
Scale
Location
MEAN
1
mean
MEDIAN
1
median
SUM
sum
0
EUCLEN
Euclidean length
0
USTD
standard deviation about origin
0
STD
standard deviation
mean
RANGE
range
minimum
MIDRANGE
range/2
midrange
MAXABS
maximum absolute value
0
IQR
interval quartile range
median
MAD
median absolute deviation from median
median
ABW(
 )
) biweight A-estimate
biweight 1-step M-estimate
AHUBER(
)Huber A-estimate
Huber 1-step M-estimate
AWAVE(
) Wave 1-step M-estimate
Wave A-estimate
AGK(p)
AGK estimate (ACECLUS)
mean
SPACING(
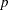 )
)minimum spacing
mid minimum-spacing
L(
) 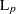
These standardization methods are further documented in the section on the METHOD= option in the PROC STDIZE statement of the STDIZE procedure (see the section Standardization Methods in Chapter 82, The STDIZE Procedure ).
Standardization is not required if there is only one level of measurement, or if only asymmetric nominal and nominal levels are specified; otherwise, standardization is mandatory. When standardization is mandatory, a default method is provided when the STD= option is not specified. You can suppress the mandatory standardization by using the NOSTD option in the PROC DISTANCE statement. See the NOSTD option in the section PROC DISTANCE Statement and the section Mandatory Standardization for details.
The default method is STD for standardizing interval variables and MAXABS for standardizing ratio variables unless METHOD=GOWER or METHOD=DGOWER is specified. If METHOD=GOWER is specified, interval variables are standardized by the RANGE method, and whatever is specified in the STD= option is ignored; if METHOD=DGOWER is specified, the RANGE method is the default standardization method for interval variables. The MAXABS method is the default standardization method for ratio variables for both the GOWER and DGOWER methods.
Notice that a ratio variable should always be positive.
Table 32.10 lists standardization methods and the levels of measurement that can be accepted by each method. For example, the SUM method can be used to standardize ratio variables but not interval or ordinal variables. Also, the AGK and SPACING methods should not be used to standardize ordinal variables. If you apply AGK and SPACING to ranks, the results are degenerate because all the spacings of a given order are equal.
Table 32.10 Legitimate Levels of Measurements for Each Method Standardization
Legitimate
Method
Levels of Measurement
MEAN
ratio, interval, ordinal
MEDIAN
ratio, interval, ordinal
SUM
ratio
EUCLEN
ratio
USTD
ratio
STD
ratio, interval, ordinal
RANGE
ratio, interval, ordinal
MIDRANGE
ratio, interval, ordinal
MAXABS
ratio
IQR
ratio, interval, ordinal
MAD
ratio, interval, ordinal
ABW(
) ratio, interval, ordinal
AHUBER(
) ratio, interval, ordinal
AWAVE(
) ratio, interval, ordinal
AGK(
) ratio, interval
SPACING(
) ratio, interval
L(
) ratio, interval, ordinal
- ABSENT=numner | qs
specifies the value to be used as an absence value in an irrelevant absent-absent match for asymmetric nominal variables. The absence value specified here overwrites the absence value specified through the ABSENT= option in the PROC DISTANCE statement for those variables in the current variable list.
An absence value for a variable can be either a numeric value or a quoted string consisting of combinations of characters. For instance, ., –999, "NA" are legal values for the ABSENT= option.
The default for an absence value for a character variable is "NONE" (notice that a blank value is considered a missing value), and the default for an absence value for a numeric variable is 0.
- MISSING=miss-method | value
specifies the method or a numeric value for replacing missing values. If you omit the MISSING= option, the REPLACE option replaces missing values with the location measure given by the STD= option. Specify the MISSING= option when you want to replace missing values with a different value. You can specify any method that is valid in the STD= option. The corresponding location measure is used to replace missing values.
If a numeric value is given, the value replaces missing values after standardizing the data. However, when standardization is not mandatory, you can specify the REPONLY option with the MISSING= option to suppress standardization for cases in which you want only to replace missing values.
If the NOSTD option is specified, there is no standardization, but missing values are replaced by the corresponding location measures or by the numeric value of the MISSING= option. See the section Missing Values for details about missing values replacement with and without standardization.- ORDER=ASCENDING | ASC
- ORDER=DESCENDING | DESC
- ORDER=ASCFORMATTED | ASCFMT
- ORDER=DESFORMATTED | DESFMT
- ORDER=DSORDER | DATA
specifies the order for assigning score to ordinal variables. The value for the ORDER= option can be one of the following:
- ASCENDING
scores are assigned in lowest-to-highest order of unformatted values.
- DESCENDING
scores are assigned in highest-to-lowest order of unformatted values.
- ASCFORMATTED
scores are assigned in ascending order by their formatted values. This option can be applied to character variables only, since unformatted values are always used for numeric variables.
- DESFORMATTED
scores are assigned in descending order by their formatted values. This option can be applied to character variables only, since unformatted values are always used for numeric variables.
- DSORDER
scores are assigned according to the order of their appearance in the input data set.
The default value is ASCENDING.
- WEIGHTS=weight-list
specifies a list of values for weighting individual variables while computing the proximity. Values in this list can be separated by blanks or commas. You can include one or more items of the form start TO stop BY increment. This list should contain at least one weight. The maximum number of weights you can list is equal to the number of variables. If the number of weights is less than the number of variables, the last value in the weight-list is used for the rest of the variables; conversely, if the number of weights is greater than the number of variables, the trailing weights are discarded.
The default value is 1.
Copyright © SAS Institute, Inc. All Rights Reserved.