| The CATMOD Procedure |
| Generalized Logits Model |
Over the course of one school year, third-graders from three different schools are exposed to three different styles of mathematics instruction: a self-paced computer-learning style, a team approach, and a traditional class approach. The students are asked which style they prefer, and their responses, classified by the type of program they are in (a regular school day versus a regular school day supplemented with an afternoon school program), are displayed in Table 28.3. The data set is from Stokes, Davis, and Koch (2000), and it is also analyzed in the section Nominal Response Data: Generalized Logits Model of Chapter 51, The LOGISTIC Procedure.
Learning Style Preference |
||||
|---|---|---|---|---|
School |
Program |
Self |
Team |
Class |
1 |
Regular |
10 |
17 |
26 |
1 |
Afternoon |
5 |
12 |
50 |
2 |
Regular |
21 |
17 |
26 |
2 |
Afternoon |
16 |
12 |
36 |
3 |
Regular |
15 |
15 |
16 |
3 |
Afternoon |
12 |
12 |
20 |
The levels of the response variable (self, team, and class) have no essential ordering, so a logistic regression is performed on the generalized logits. The model to be fit is
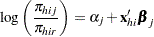 |
where 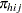 is the probability that a student in school
is the probability that a student in school 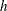 and program
and program 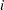 prefers teaching style
prefers teaching style 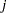 ,
, 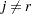 , and style
, and style  is the class style. There are separate sets of intercept parameters
is the class style. There are separate sets of intercept parameters 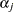 and regression parameters
and regression parameters 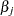 for each logit, and the matrix
for each logit, and the matrix  is the set of explanatory variables for the
is the set of explanatory variables for the 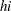 th population. Thus, two logits are modeled for each school and program combination (population): the logit comparing self to class and the logit comparing team to class.
th population. Thus, two logits are modeled for each school and program combination (population): the logit comparing self to class and the logit comparing team to class.
The following statements create the data set school and request the analysis. Generalized logits are the default response functions, and maximum likelihood estimation is the default method for analyzing generalized logits, so only the WEIGHT and MODEL statements are required. The option ORDER=DATA means that the response variable levels are ordered as they exist in the data set: self, team, and class; the logits are formed by comparing self to class and by comparing team to class. The results of this analysis are shown in Figure 28.6 and Figure 28.7.
data school; length Program $ 9; input School Program $ Style $ Count @@; datalines; 1 regular self 10 1 regular team 17 1 regular class 26 1 afternoon self 5 1 afternoon team 12 1 afternoon class 50 2 regular self 21 2 regular team 17 2 regular class 26 2 afternoon self 16 2 afternoon team 12 2 afternoon class 36 3 regular self 15 3 regular team 15 3 regular class 16 3 afternoon self 12 3 afternoon team 12 3 afternoon class 20 ;
proc catmod order=data; weight Count; model Style=School Program School*Program; run;
A summary of the data set is displayed in Figure 28.6; the variable levels that form the three responses and six populations are listed in the "Response Profiles" and "Population Profiles" tables, respectively.
| Data Summary | |||
|---|---|---|---|
| Response | Style | Response Levels | 3 |
| Weight Variable | Count | Populations | 6 |
| Data Set | SCHOOL | Total Frequency | 338 |
| Frequency Missing | 0 | Observations | 18 |
The analysis of variance table is displayed in Figure 28.7. Since this is a saturated model, there are no degrees of freedom remaining for a likelihood ratio test, and missing values are displayed in the table. The interaction effect is clearly nonsignificant, so a main-effects model is fit.
Since PROC CATMOD is an interactive procedure, you can analyze the main-effects model by simply submitting the new MODEL statement as follows:
model Style=School Program; run;
You can check the population and response profiles (not shown) to confirm that they are the same as those in Figure 28.6. The analysis of variance table is shown in Figure 28.8. The likelihood ratio chi-square statistic is 1.78 with a p-value of 0.7766, indicating a good fit; the Wald chi-square tests for the school and program effects are also significant. Since School has three levels, two parameters are estimated for each of the two logits they modeled, for a total of four degrees of freedom. Since Program has two levels, one parameter is estimated for each of the two logits, for a total of two degrees of freedom.
The parameter estimates and tests for individual parameters are displayed in Figure 28.9. The order of the parameters corresponds to the order of the population and response variables as shown in the profile tables (see Figure 28.6), with the levels of the response variables varying most rapidly. The first response function is the logit that compares self to class, and the corresponding parameters have Function Number=1. The second logit (Function Number=2) compares team to class. The School=1 parameters are the differential effects versus School=3 for their respective logits, and the School=2 parameters are likewise differential effects versus School=3. The Program parameters are the differential effects of 'regular' versus 'afternoon' for the two response functions.
| Analysis of Maximum Likelihood Estimates | ||||||
|---|---|---|---|---|---|---|
| Parameter | Function Number |
Estimate | Standard Error |
Chi- Square |
Pr > ChiSq | |
| Intercept | 1 | -0.7979 | 0.1465 | 29.65 | <.0001 | |
| 2 | -0.6589 | 0.1367 | 23.23 | <.0001 | ||
| School | 1 | 1 | -0.7992 | 0.2198 | 13.22 | 0.0003 |
| 1 | 2 | -0.2786 | 0.1867 | 2.23 | 0.1356 | |
| 2 | 1 | 0.2836 | 0.1899 | 2.23 | 0.1352 | |
| 2 | 2 | -0.0985 | 0.1892 | 0.27 | 0.6028 | |
| Program | regular | 1 | 0.3737 | 0.1410 | 7.03 | 0.0080 |
| regular | 2 | 0.3713 | 0.1353 | 7.53 | 0.0061 | |
The Program variable has nearly the same effect on both logits, while School=1 has the largest effect of the schools.
Copyright © SAS Institute, Inc. All Rights Reserved.