| The QUANTREG Procedure |
Example 72.1 Comparison of Algorithms
This example illustrates and compares the three algorithms for regression estimation available in the QUANTREG procedure. The simplex algorithm is the default because of its stability. Although this algorithm is slower than the interior point and smoothing algorithms for large data sets, the difference is not as significant for data sets with fewer than 5,000 observations and 50 variables. The simplex algorithm can also compute the entire quantile process, which is shown in Example 72.2.
The following statements generate 1,000 random observations. The first 950 observations are from a linear model, and the last 50 observations are significantly biased in the  -direction. In other words, 5
-direction. In other words, 5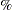 of the observations are contaminated with outliers.
of the observations are contaminated with outliers.
data a (drop=i);
do i=1 to 1000;
x1=rannor(1234);
x2=rannor(1234);
e=rannor(1234);
if i > 950 then y=100 + 10*e;
else y=10 + 5*x1 + 3*x2 + 0.5 * e;
output;
end;
run;
The following statements invoke the QUANTREG procedure to fit a median regression model with the default simplex algorithm. They produce the results in Output 72.1.1 through Output 72.1.3.
proc quantreg data=a;
model y = x1 x2;
run;
Output 72.1.1 displays model information and summary statistics for variables in the model. It indicates that the simplex algorithm is used to compute the optimal solution and the rank method is used to compute confidence intervals of the parameters.
By default, the QUANTREG procedure fits a median regression model. This is indicated by the quantile value 0.5 in Output 72.1.2, which also displays the objective function value and the predicted value of the response at the means of the covariates.
Output 72.1.3 displays parameter estimates and confidence limits. These estimates are reasonable, which indicates that median regression is robust to the 50 outliers.
| Model Information | |
|---|---|
| Data Set | WORK.A |
| Dependent Variable | y |
| Number of Independent Variables | 2 |
| Number of Observations | 1000 |
| Optimization Algorithm | Simplex |
| Method for Confidence Limits | Inv_Rank |
The following statements refit the model by using the interior point algorithm:
proc quantreg algorithm=interior(tolerance=1e-6)
ci=none data=a;
model y = x1 x2 / itprint nosummary;
run;
The TOLERANCE= option specifies the stopping criterion for convergence of the interior point algorithm, which is controlled by the duality gap. Although the default criterion is 1E 8, the value 1E6 is often sufficient. The ITPRINT option requests the iteration history for the algorithm. The option CI=NONE suppresses the computation of confidence limits, and the option NOSUMMARY suppresses the table of summary statistics.
8, the value 1E6 is often sufficient. The ITPRINT option requests the iteration history for the algorithm. The option CI=NONE suppresses the computation of confidence limits, and the option NOSUMMARY suppresses the table of summary statistics.
Output 72.1.4 displays model fit information.
| Model Information | |
|---|---|
| Data Set | WORK.A |
| Dependent Variable | y |
| Number of Independent Variables | 2 |
| Number of Observations | 1000 |
| Optimization Algorithm | Interior |
Output 72.1.5 displays the iteration history of the interior point algorithm. Note that the duality gap is less than 1E6 in the final iteration. The table also provides the number of iterations, the number of corrections, the primal step length, the dual step length, and the objective function value at each iteration.
| Iteration History of Interior Point Algorithm | |||||
|---|---|---|---|---|---|
| Duality Gap |
Iter | Correction | Primal Step |
Dual Step |
Objective Function |
| 2623 | 1 | 1 | 0.3113 | 0.4910 | 3303.4688 |
| 3215 | 2 | 2 | 0.0427 | 1.0000 | 2461.3774 |
| 1127 | 3 | 3 | 0.9882 | 0.3653 | 2451.1337 |
| 760.88658 | 4 | 4 | 0.3381 | 1.0000 | 2442.8104 |
| 77.10290 | 5 | 5 | 1.0000 | 0.8916 | 2441.2627 |
| 8.43666 | 6 | 6 | 0.9370 | 0.8381 | 2441.2085 |
| 1.82868 | 7 | 7 | 0.8375 | 0.7674 | 2441.1985 |
| 0.40584 | 8 | 8 | 0.6980 | 0.8636 | 2441.1948 |
| 0.09550 | 9 | 9 | 0.9438 | 0.5955 | 2441.1930 |
| 0.00665 | 10 | 10 | 0.9818 | 0.9304 | 2441.1927 |
| 0.0002248 | 11 | 11 | 0.9179 | 0.9994 | 2441.1927 |
| 5.44651E-8 | 12 | 12 | 1.0000 | 1.0000 | 2441.1927 |
Output 72.1.6 displays the parameter estimates obtained with the interior point algorithm, which are identical to those obtained with the simplex algorithm.
The following statements refit the model by using the smoothing algorithm. They produce the results in Output 72.1.7 through Output 72.1.9.
proc quantreg algorithm=smooth(rratio=.5) ci=none data=a;
model y = x1 x2 / itprint nosummary;
run;
The RRATIO= option controls the reduction speed of the threshold. Output 72.1.7 displays the model fit information.
| Model Information | |
|---|---|
| Data Set | WORK.A |
| Dependent Variable | y |
| Number of Independent Variables | 2 |
| Number of Observations | 1000 |
| Optimization Algorithm | Smooth |
Output 72.1.8 displays the iteration history of the smoothing algorithm. The threshold controls the convergence. Note that the thresholds decrease by a factor of at least 0.5, the value specified with the RRATIO= option. The table also provides the number of iterations, the number of factorizations, the number of full updates, the number of partial updates, and the objective function value in each iteration. For details concerning the smoothing algorithm, refer to Chen (2007).
| Iteration History of Smoothing Algorithm | |||||
|---|---|---|---|---|---|
| Threshold | Iter | Refac | Full Update |
Partial Update |
Objective Function |
| 227.24557 | 1 | 1 | 1000 | 0 | 4267.0988 |
| 116.94090 | 15 | 4 | 1480 | 2420 | 3631.9653 |
| 1.44064 | 17 | 4 | 1480 | 2583 | 2441.4719 |
| 0.72032 | 20 | 5 | 1980 | 2598 | 2441.3315 |
| 0.36016 | 22 | 6 | 2248 | 2607 | 2441.2369 |
| 0.18008 | 24 | 7 | 2376 | 2608 | 2441.2056 |
| 0.09004 | 26 | 8 | 2446 | 2613 | 2441.1997 |
| 0.04502 | 28 | 9 | 2481 | 2617 | 2441.1971 |
| 0.02251 | 30 | 10 | 2497 | 2618 | 2441.1956 |
| 0.01126 | 32 | 11 | 2505 | 2620 | 2441.1946 |
| 0.00563 | 34 | 12 | 2510 | 2621 | 2441.1933 |
| 0.00281 | 35 | 13 | 2514 | 2621 | 2441.1930 |
| 0.0000846 | 36 | 14 | 2517 | 2621 | 2441.1927 |
| 1E-12 | 37 | 14 | 2517 | 2621 | 2441.1927 |
Output 72.1.9 displays the parameter estimates obtained with the smoothing algorithm, which are identical to those obtained with the simplex and interior point algorithms. All three algorithms should have the same parameter estimates unless the problem does not have a unique solution.
The interior point algorithm and the smoothing algorithm offer better performance than the simplex algorithm for large data sets. Refer to Chen (2004) for more details on choosing an appropriate algorithm on the basis of data set size. All three algorithms should have the same parameter estimates, unless the optimization problem has multiple solutions.
Copyright © 2009 by SAS Institute Inc., Cary, NC, USA. All rights reserved.