| The NLIN Procedure |
Example 60.4 Affecting Curvature through Parameterization
The work of Ratkowksy (1983, 1990) has brought into focus the importance of close-to-linear behavior of parameters in nonlinear regression models. The curvature in a nonlinear model consists of two components, the intrinsic curvature and the parameter-effects curvature. Intrinsic curvature expresses the degree to which the nonlinear model bends as values of the parameters change. This is not the same as the curviness of the model as a function of the covariates (the  variables). Intrinsic curvature is a function of the type of model you are fitting and the data. This curvature component cannot be affected by reparameterization of the model. According to Ratkowsky (1983), the intrinsic curvature component is typically smaller than the parameter-effects curvature, which can be affected by altering the parameterization of the model.
variables). Intrinsic curvature is a function of the type of model you are fitting and the data. This curvature component cannot be affected by reparameterization of the model. According to Ratkowsky (1983), the intrinsic curvature component is typically smaller than the parameter-effects curvature, which can be affected by altering the parameterization of the model.
In models with low curvature, the nonlinear least-squares parameter estimators behave similarly to least-squares estimators in linear regression models, which have a number of desirable properties. If the model is correct, they are best linear unbiased estimators and are normally distributed if the model errors are normal (otherwise they are asymptotically normal). As you lower the curvature of a nonlinear model, you can expect that the parameter estimators approach the behavior of the linear regression model estimators: they behave "close to linear."
This example uses a simple data set and a commonly applied model for dose-response relationships to examine how the parameter-effects curvature can be reduced. The statistic by which an estimator’s behavior is judged is Hougaard’s measure of skewness (Hougaard 1982, 1985).
The log-logistic model
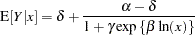 |
is a popular model to express the response  as a function of dose . The response is bounded between the asymptotes
as a function of dose . The response is bounded between the asymptotes  and
and 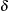 . The term in the denominator governs the transition between the asymptotes and depends on two parameters,
. The term in the denominator governs the transition between the asymptotes and depends on two parameters, 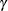 and
and 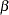 . The log-logistic model can be viewed as a member of a broader class of dose-response functions, those relying on switch-on or switch-off mechanisms (see, for example, Schabenberger and Pierce 2002, Sect. 5.8.6). A switch function is usually a monotonic function
. The log-logistic model can be viewed as a member of a broader class of dose-response functions, those relying on switch-on or switch-off mechanisms (see, for example, Schabenberger and Pierce 2002, Sect. 5.8.6). A switch function is usually a monotonic function 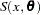 that takes values between 0 and 1. A switch-on function increases in ; a switch-off function decreases in . In the log-logistic case, the function
that takes values between 0 and 1. A switch-on function increases in ; a switch-off function decreases in . In the log-logistic case, the function
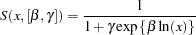 |
is a switch-off function for 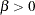 and a switch-on function for
and a switch-on function for 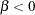 . You can write general dose-response functions with asymptotes simply as
. You can write general dose-response functions with asymptotes simply as
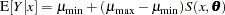 |
The following DATA step creates a small data set from a dose-response experiment with response y:
data logistic;
input dose y;
logdose = log(dose);
datalines;
0.009 106.56
0.035 94.12
0.07 89.76
0.15 60.21
0.20 39.95
0.28 21.88
0.50 7.46
;
A graph of these data is produced with the following statements:
proc sgplot data=logistic;
scatter y=y x=dose;
xaxis type=log logstyle=linear;
run;
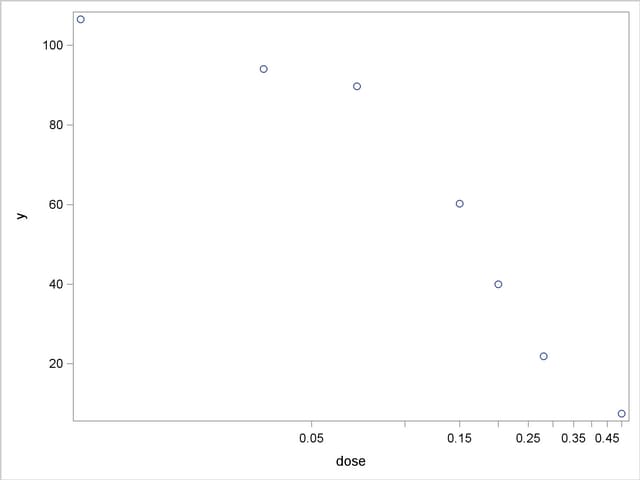
When dose is expressed on the log scale, the sigmoidal shape of the dose-response relationship is clearly visible (Output 60.4.1). The log-logistic switching model in the preceding parameterization is fit with the following statements in the NLIN procedure:
ods select IterHistory ConvergenceStatus Anova ParameterEstimates;
proc nlin data=logistic hougaard;
parameters alpha=100 beta=3 gamma=300;
delta = 0;
Switch = 1/(1+gamma*exp(beta*log(dose)));
model y = delta + (alpha - delta)*Switch;
run;
The lower asymptote was assumed to be 0 in this case. Since is not listed in the PARAMETERS statement and is assigned a value in the program, it is assumed to be constant. Note that the term Switch is the switch-off function in the log-logistic model. The HOUGAARD option in the PROC NLIN statement requests that Hougaard’s skewness measure is added to the table of parameter estimates.
The NLIN procedure converges after  iteration and achieves a residual mean squared error of
iteration and achieves a residual mean squared error of 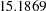 (Output 60.4.2). This value is not that important by itself, but it is worth noting since this model fit is compared to the fit with other parameterizations later on.
(Output 60.4.2). This value is not that important by itself, but it is worth noting since this model fit is compared to the fit with other parameterizations later on.
| Iterative Phase | ||||
|---|---|---|---|---|
| Iter | alpha | beta | gamma | Sum of Squares |
| 0 | 100.0 | 3.0000 | 300.0 | 386.4 |
| 1 | 100.4 | 2.8011 | 162.8 | 129.1 |
| 2 | 100.8 | 2.6184 | 101.4 | 69.2710 |
| 3 | 101.3 | 2.4266 | 69.7579 | 68.2167 |
| 4 | 101.7 | 2.3790 | 69.0358 | 60.8223 |
| 5 | 101.8 | 2.3621 | 67.3709 | 60.7516 |
| 6 | 101.8 | 2.3582 | 67.0044 | 60.7477 |
| 7 | 101.8 | 2.3573 | 66.9150 | 60.7475 |
| 8 | 101.8 | 2.3571 | 66.8948 | 60.7475 |
| 9 | 101.8 | 2.3570 | 66.8902 | 60.7475 |
| 10 | 101.8 | 2.3570 | 66.8892 | 60.7475 |
The table of parameter estimates displays the estimates of the three model parameters, their approximate standard errors, 95% confidence limits, and Hougaard’s skewness measure (Output 60.4.3). Parameters for which this measure is less than 0.1 in absolute value exhibit very close-to-linear behavior, and values less than 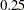 in absolute value indicate reasonably close-to-linear behavior (Ratkowsky 1990). According to these rules, the estimators
in absolute value indicate reasonably close-to-linear behavior (Ratkowsky 1990). According to these rules, the estimators 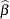 and
and 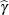 suffer from substantial curvature. The estimator is especially "far from linear." Inferences involving that rely on the reported standard errors and/or confidence limits for this parameter might be questionable.
suffer from substantial curvature. The estimator is especially "far from linear." Inferences involving that rely on the reported standard errors and/or confidence limits for this parameter might be questionable.
One method of reducing the parameter-effects curvature is to replace a parameter with its expected-value parameterization. Schabenberger et al. (1999) and Schabenberger and Pierce (2002, Sect. 5.7.2) refer to this method as reparameterization through defining relationships. A defining relationship is obtained by equating the mean response at a chosen value of (say,  ) to the model:
) to the model:
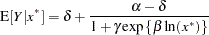 |
This equation is then solved for a parameter that is subsequently replaced in the original equation. This method is particularly useful if has an interesting interpretation. For example, let 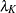 denote the value that reduces the response by
denote the value that reduces the response by 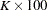 %,
%,
 |
Because exhibits large skewness, it is the target in the first round of reparameterization. Setting the expression for the conditional mean at equal to the mean function when 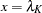 yields the following expression:
yields the following expression:
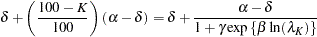 |
This expression is solved for , and the result is substituted back into the model equation. This leads to a log-logistic model in which is replaced by the parameter , the dose at which the response was reduced by %. The new model equation is
 |
A particularly interesting choice is  , since
, since 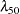 is the dose at which the response is halved. In studies of mortality, this concentration is also known as the LD50. For the special case of the model equation becomes
is the dose at which the response is halved. In studies of mortality, this concentration is also known as the LD50. For the special case of the model equation becomes
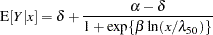 |
You can fit the model in the LD50 parameterization with the following statements:
ods select ConvergenceStatus Anova ParameterEstimates;
proc nlin data=logistic hougaard;
parameters alpha=100 beta=3 LD50=0.15;
delta = 0;
Switch = 1/(1+exp(beta*log(dose/LD50)));
model y = delta + (alpha - delta)*Switch;
output out=nlinout pred=p lcl=lcl ucl=ucl;
run;
Partial results from this NLIN run are shown in Output 60.4.4. The analysis of variance tables in Output 60.4.2 and Output 60.4.4 are identical. Changing the parameterization of a model does not affect the model fit. It does, however, affect the interpretation of the parameters and the statistical properties (close-to-linear behavior) of the parameter estimators. The skewness measure of the parameter LD50 is considerably reduced compared to the skewness of the parameter in the previous parameterization. Also, has been replaced by a parameter with a useful interpretation, the dose that yields a 50% reduction in mean response. Also notice that the skewness measures of and are not affected by the 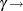 LD50 reparameterization.
LD50 reparameterization.
| NOTE: Convergence criterion met. |
| Note: | An intercept was not specified for this model. |
| Source | DF | Sum of Squares | Mean Square | F Value | Approx Pr > F |
|---|---|---|---|---|---|
| Model | 3 | 33965.4 | 11321.8 | 745.50 | <.0001 |
| Error | 4 | 60.7475 | 15.1869 | ||
| Uncorrected Total | 7 | 34026.1 |
| Parameter | Estimate | Approx Std Error |
Approximate 95% Confidence Limits |
Skewness | |
|---|---|---|---|---|---|
| alpha | 101.8 | 3.0034 | 93.4752 | 110.2 | 0.1415 |
| beta | 2.3570 | 0.2928 | 1.5440 | 3.1699 | 0.4987 |
| LD50 | 0.1681 | 0.00915 | 0.1427 | 0.1935 | -0.0605 |
To reduce the parameter-effects curvature of the parameter, you can use the technique of defining relationships again. This can be done generically, by solving
 |
for , treating 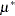 as the new parameter (in lieu of ), and choosing a value for that leads to low skewness. This results in the expected-value parameterization of . Solving for yields
as the new parameter (in lieu of ), and choosing a value for that leads to low skewness. This results in the expected-value parameterization of . Solving for yields
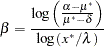 |
The interpretation of the parameter that replaces in the model equation is simple: it is the mean dose response when the dose is . Fixing 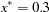 , the following PROC NLIN statements fit this model:
, the following PROC NLIN statements fit this model:
ods select ConvergenceStatus Anova ParameterEstimates;
proc nlin data=logistic hougaard;
parameters alpha=100 mustar=20 LD50=0.15;
delta = 0;
xstar = 0.3;
beta = log((alpha - mustar)/(mustar - delta)) / log(xstar/LD50);
Switch = 1/(1+exp(beta*log(dose/LD50)));
model y = delta + (alpha - delta)*Switch;
output out=nlinout pred=p lcl=lcl ucl=ucl;
run;
Note that the switch-off function continues to be written in terms of and the LD50. The only difference from the previous model is that is now expressed as a function of the parameter . Using expected-value parameterizations is a simple mechanism to lower the curvature in a model and to arrive at starting values. The starting value for can be gleaned from Output 60.4.1 at 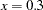 .
.
Output 60.4.5 shows selected results from this NLIN run. The ANOVA table is again unaffected by the change in parameterization. The curvature for is greatly reduced in comparison to the curvature for the parameter in the previous model (compare Output 60.4.5 and Output 60.4.4).
| NOTE: Convergence criterion met. |
| Note: | An intercept was not specified for this model. |
| Source | DF | Sum of Squares | Mean Square | F Value | Approx Pr > F |
|---|---|---|---|---|---|
| Model | 3 | 33965.4 | 11321.8 | 745.50 | <.0001 |
| Error | 4 | 60.7475 | 15.1869 | ||
| Uncorrected Total | 7 | 34026.1 |
| Parameter | Estimate | Approx Std Error |
Approximate 95% Confidence Limits |
Skewness | |
|---|---|---|---|---|---|
| alpha | 101.8 | 3.0034 | 93.4752 | 110.2 | 0.1415 |
| mustar | 20.7073 | 2.6430 | 13.3693 | 28.0454 | -0.0572 |
| LD50 | 0.1681 | 0.00915 | 0.1427 | 0.1935 | -0.0605 |
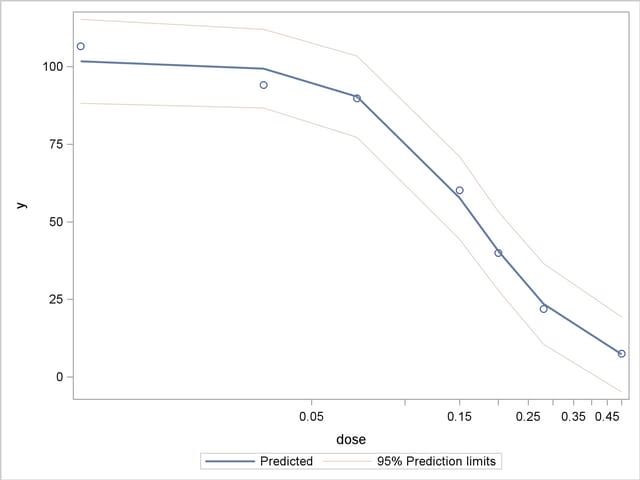
The following statements produce a graph of the observed and fitted values along with the 95% prediction limits (Output 60.4.6). The graph is based on the data set created with the OUTPUT statement in the most recent PROC NLIN run.
proc sgplot data=nlinout;
scatter y=y x=dose;
series y=p x=dose / name="fit"
lineattrs=GraphFit
LegendLabel="Predicted";
series y=lcl x=dose / lineattrs=GraphConfidence
name="lcl"
legendlabel="95% Prediction limits";
series y=ucl x=dose / lineattrs=GraphConfidence;
keylegend "fit" "lcl";
xaxis type=log logstyle=linear;
run;
Copyright © 2009 by SAS Institute Inc., Cary, NC, USA. All rights reserved.