| The GLMSELECT Procedure |
| CLASS Statement |
The CLASS statement names the classification variables to be used in the analysis. The CLASS statement must precede the MODEL statement.
The following options can be specified after a slash (/):
- DELIMITER=quoted character
specifies the delimiter that is used between levels of classification variables in building parameter names and lists of class level values. The default if you do not specify DELIMITER= is a space. This option is useful if the levels of a classification variable contain embedded blanks.
- SHOW | SHOWCODING
requests a table for each classification variable that shows the coding used for that variable.
You can specify various v-options for each variable by enclosing them in parentheses after the variable name. You can also specify global v-options for the CLASS statement by placing them after a slash (/). Global v-options are applied to all the variables specified in the CLASS statement. If you specify more than one CLASS statement, the global v-options specified in any one CLASS statement apply to all CLASS statements. However, individual CLASS variable v-options override the global v-options.
The following v-options are available:
- CPREFIX=n
specifies that, at most, the first n characters of a CLASS variable name be used in creating names for the corresponding design variables. The default is
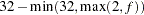 , where
, where  is the formatted length of the CLASS variable. The CPREFIX= applies only when you specify the PARMLABELSTYLE=INTERLACED option in the PROC GLMSELECT statement.
is the formatted length of the CLASS variable. The CPREFIX= applies only when you specify the PARMLABELSTYLE=INTERLACED option in the PROC GLMSELECT statement. - DESCENDING
- DESC
- LPREFIX=n
specifies that, at most, the first n characters of a CLASS variable label be used in creating labels for the corresponding design variables. The default is
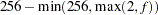 , where is the formatted length of the CLASS variable. The LPREFIX= applies only when you specify the PARMLABELSTYLE=INTERLACED option in the PROC GLMSELECT statement.
, where is the formatted length of the CLASS variable. The LPREFIX= applies only when you specify the PARMLABELSTYLE=INTERLACED option in the PROC GLMSELECT statement. - MISSING
allows missing value (’.’ for a numeric variable and blanks for a character variables) as a valid value for the CLASS variable.
- ORDER=DATA | FORMATTED | FREQ | INTERNAL
specifies the sorting order for the levels of classification variables. This ordering determines which parameters in the model correspond to each level in the data, so the ORDER= option might be useful when you use the CONTRAST or ESTIMATE statement. If ORDER=FORMATTED for numeric variables for which you have supplied no explicit format, the levels are ordered by their internal values. Note that this represents a change from previous releases for how class levels are ordered. Before SAS 8, numeric class levels with no explicit format were ordered by their BEST12. formatted values, and in order to revert to the previous ordering you can specify this format explicitly for the affected classification variables. The change was implemented because the former default behavior for ORDER=FORMATTED often resulted in levels not being ordered numerically and usually required the user to intervene with an explicit format or ORDER=INTERNAL to get the more natural ordering. The following table shows how PROC GLMSELECT interprets values of the ORDER= option.
Value of ORDER=
Levels Sorted By
DATA
order of appearance in the input data set
FORMATTED
external formatted value, except for numeric
variables with no explicit format, which are
sorted by their unformatted (internal) value
FREQ
descending frequency count; levels with the
most observations come first in the order
INTERNAL
unformatted value
By default, ORDER=FORMATTED. For FORMATTED and INTERNAL, the sort order is machine dependent.
For more information about sorting order, refer to the chapter on the SORT procedure in the Base SAS Procedures Guide and the discussion of BY-group processing in SAS Language Reference: Concepts.
- PARAM=keyword
specifies the parameterization method for the classification variable or variables. Design matrix columns are created from CLASS variables according to the following coding schemes. The default is PARAM=GLM. If PARAM=ORTHPOLY or PARAM=POLY, and the CLASS levels are numeric, then the ORDER= option in the CLASS statement is ignored, and the internal, unformatted values are used. See the section CLASS Variable Parameterization for further details.
- EFFECT
specifies effect coding.
- GLM
specifies less-than-full-rank, reference-cell coding; this option can be used only as a global option.
- ORDINAL THERMOMETER
specifies the cumulative parameterization for an ordinal CLASS variable.
- POLYNOMIAL POLY
specifies polynomial coding.
- REFERENCE REF
specifies reference-cell coding.
- ORTHEFFECT
orthogonalizes PARAM=EFFECT.
- ORTHORDINAL ORTHOTHERM
orthogonalizes PARAM=ORDINAL.
- ORTHPOLY
orthogonalizes PARAM=POLYNOMIAL.
- ORTHREF
orthogonalizes PARAM=REFERENCE.
The EFFECT, POLYNOMIAL, REFERENCE, and ORDINAL schemes and their orthogonal parameterizations are full rank. The REF= option in the CLASS statement determines the reference level for the EFFECT and REFERENCE schemes and their orthogonal parameterizations.
- REF=’level’ | keyword
specifies the reference level for PARAM=EFFECT, PARAM=REFERENCE, and their orthogonalizations. For an individual (but not a global) variable REF= option, you can specify the level of the variable to use as the reference level. For a global or individual variable REF= option, you can use one of the following keywords. The default is REF=LAST.
- FIRST
designates the first-ordered level as reference.
- LAST
designates the last-ordered level as reference.
- SPLIT
requests that the columns of the design matrix corresponding to any effect containing a split classification variable can be selected to enter or leave a model independently of the other design columns of that effect. For example, suppose a variable named temp has three levels with values "hot," "warm," and "cold," and a variable named sex has two levels with values "M" and "F" are used in a PROC GLMSELECT job as follows:
proc glmselect; class temp sex/split; model depVar = sex sex*temp; run;As both the classification variables are split, the two effects named in the MODEL statement are split into eight independent effects. The effect "sex" is split into two effects labeled "sex_M" and "sex_F". The effect "sex*temp" is split into six effects labeled "sex_M*temp_hot", "sex_F*temp_hot", "sex_M*temp_warm", "sex_F*temp_warm", "sex_M*temp_cold", and "sex_F*temp_cold", and the previous PROC GLMSELECT step is equivalent to the following:
proc glmselect; model depVar = sex_M sex_F sex_M*temp_hot sex_F*temp_hot sex_M*temp_warm sex_F*temp_warm sex_M*temp_cold sex_F*temp_cold; run;The split option can be used on individual classification variables. For example, consider the following PROC GLMSELECT step:
proc glmselect; class temp(split) sex; model depVar = sex sex*temp; run;In this case the effect "sex" is not split and the effect "sex*temp" is split into three effects labeled "sex*temp_hot", "sex*temp_warm", and "sex*temp_cold". Furthermore each of these three split effects now has two parameters corresponding to the two levels of "sex," and the PROC GLMSELECT step is equivalent to the following:
proc glmselect; class sex; model depVar = sex sex*temp_hot sex*temp_warm sex*temp_cold; run;
Copyright © 2009 by SAS Institute Inc., Cary, NC, USA. All rights reserved.