Character Encoding
Overview of Character Encoding
All input to a computer
is represented internally as numbers. The computer assigns a number
to each character – technically, the number is a binary number
(base 2 numbering system, consisting of 0s and 1s).
Because most of us do
not think in binary numbers, computers provide hexadecimal (base 16
numbering system) representation as a shorthand for binary representation.
For example, for the decimal number 167, it's easier to understand
the hexadecimal number A7 than the equivalent binary number 10100111.
Therefore, you can think of the computer's internal numeric representation
of all data as a hexadecimal number.
What is Character Encoding?
All data that is stored,
transmitted, or processed by a computer is in an encoding. An encoding
maps each character to a unique numeric representation. For example:
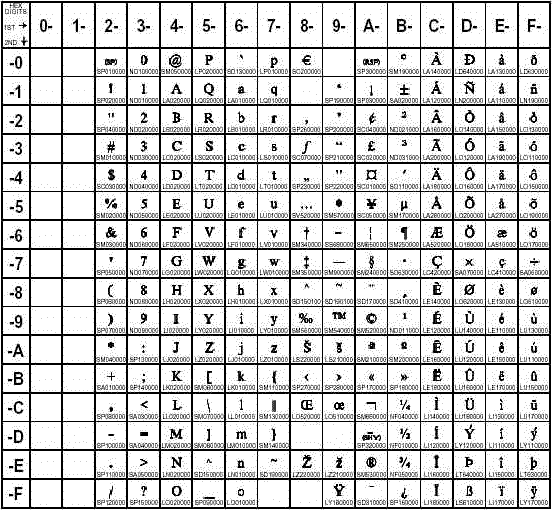
To assign the numeric
representation to a character, an encoding uses a code page, which
is an ordered set of characters in which a numeric index (code point
value) is associated with each character. The position of a character
on the code page determines its two-digit hexadecimal number. The
first digit of the hexadecimal number is determined by the column,
and the second digit by the row. For example, the following is the
code page for the Windows Latin1 encoding. The numeric representation
for the uppercase A is the hexadecimal number 41, and the numeric
representation for the equal sign (=) is the hexadecimal number 3D.
Encoding is the combination
of a character set with an encoding method:
-
A character set is the repertoire of characters and symbols that are used by a language or group of languages. A character set includes national characters (which are characters specific to a particular nation or group of nations), special characters (such as punctuation marks), the unaccented Latin characters A through Z, the digits 0 through 9, and control characters that are needed by the computer.
-
An encoding method is the set of rules that are used to assign the numbers to the set of characters that are in an encoding. These rules govern such things as the size of the encoding (number of bits used to store the numeric representation of the character) and the ranges in the code page where characters are allowed to appear.
When the rules of the
encoding method are followed, and numbers are assigned to the characters,
the result is called an encoding.
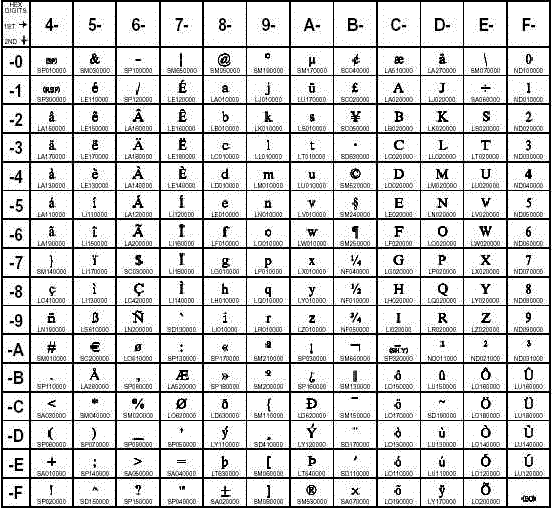
An individual character
can have different positions in code pages for different encodings,
which result in different hexadecimal numbers. For example, the position
of the uppercase letter A in the Wlatin1 code page (shown above) results
in the hexadecimal number 41, while in the following Danish EBCDIC
code page, the position of the uppercase letter A results in the hexadecimal
number C1.
Common Encodings
There are many encodings
that address the requirements of different languages. Very few languages
use only the 26 characters A through Z of the Latin alphabet. In addition,
there are different encodings to address different operating system
standards.
An encoding that represents
each character in one byte is a single-byte character set (SBCS).
A single-byte character set can be either 7 bits (providing up to
128 characters) or 8 bits (providing up to 256 characters). An example
of an 8-bit SBCS is the Latin1 encoding (represents the characters
of Western Europe). (Note that the term octet, for the international
community, is an 8-bit byte. Since a byte is not 8 bits in all computer
systems, octet provides an unambiguous term.)
A multiple-byte character
set (MBCS) is a mixed-width encoding in which some characters consist
of more than one byte. For example, the Japanese, Korean, Simplified
Chinese, and Traditional Chinese are MBCS encodings. A double-byte
character set (DBCS) is a specific type of an MBCS encoding that includes
characters that consist of two bytes.
The following are common
encodings:
Is a 7-bit encoding
for the United States that provides 128 character combinations. The
encoding contains characters for uppercase and lowercase English,
American English punctuation, base 10 numbers, and a few control characters.
The set of 128 characters is the one common denominator that is contained
in most encodings, excluding EBCDIC-based encodings. ASCII is used
by personal computers.
Is a 7-bit encoding
that is an international standard and provides 128 character combinations.
The ISO 646 family of encodings is like ASCII except for 12 code points
for national variants. The 12 national variants represent specific
characters needed for a particular language.
Is an 8-bit encoding
that provides 256 character combinations. There are multiple EBCDIC-based
encodings. EBCDIC is used on IBM mainframes and most IBM midrange
computers. EBCDIC follows ISO 646 conventions to facilitate translations
between itself and 7-bit ASCII-based encodings. Characters A through
Z and 0 through 9 are mapped to the same code points on all EBCDIC
code pages, while the rest of the code points can be used for special
characters and national characters, depending on the encoding.
Is an 8-bit extension
of ASCII that supports all of the ASCII code points and adds 12 more,
providing 256 character combinations. Latin1, which is officially
named ISO-8859-1, is the most frequently used member of the ISO 8859
family of encodings. In addition to the ASCII characters, Latin1 contains
accented characters, other letters needed for languages of Western
Europe, and some special characters.
Uses two bytes for
each character rather than one and provides up to 65,536 character
combinations. Unicode can handle the scripts of basically all of the
world's languages. For example, the Japanese language, which has thousands
of characters, uses a 16-bit, multiple-byte character set. There are
various forms of Unicode, including UTF-8, UTF-16, and UTF-32.