
The Resource Stats Collector block accumulates statistics for resource entities in your model. In the Block Properties dialog box that is associated with the Resource Stats Collector block, you specify the resources for which you want to collect statistics and the types of statistics you want to collect. Statistics are gathered on a continuous basis (whenever the statistic changes).
The Resource Stats Collector block is very flexible and enables you to base definitions of groups of resource entities on both entity type and Boolean rules for attribute values. You define statistics that are based on certain criteria for each group of resource entities. Possible criteria include whether the resource entities in the group are seized, whether the resource entities in the group are in a particular resource state, and whether the attribute values of the resource entities in the group satisfy a particular Boolean expression. For example, you could define a statistic named “utilization” that computes a statistic of type %AvgAvail that has the criterion Seized=TRUE. The result would be the percentage of time that the resource entities in the defined group are seized (“busy”), relative to the time-averaged number of available resource units in the group during the simulation run.
The Resource Stats Collector block uses its data collection facility to store values it collects. The statistics can be saved to a SAS data set or JMP table. The statistics are stored in a data model object, which can be accessed through the block’s OutData port. To visualize the statistics, you can connect a display block (such as the Bar Chart or Table block) to the OutData port. Any block connected to the OutData port is automatically notified when the statistics in the data model object are modified.
- OutData
-
Output port for the latest updated data model object that contains the statistics held by the Resource Stats Collector block.
Use the Groups table to define the groups (collections of resource entities) for which you want to collect statistics. Each group is represented by a single row in the Groups table. For each group, you can set criteria (columns in the Groups table) to restrict the resources included in the group.
- Add
-
Defines a new group for which to collect statistics. Each group represents one observation (row) in the collected data. A group has the following properties: Name, Entity Types, and Attribute Rule. You can edit each property directly in the Groups table.
-
Name specifies a name for the group of resource entities. This name appears as the first variable in the observation, with the title GroupName.
-
Entity Types (optional) restricts the group to include only those resource entities that have a particular entity type.
-
Attribute Rule (optional) restricts the group to include only those resource entities that satisfy the specified Boolean expression for their attributes. You can type the expression in the Attribute Rule field, or you can right-click on the Attribute Rule field and select the Edit option to open the Edit Expression window. For more information about how to write the Boolean expression, see Appendix F: Expressions.
If Entity Types and Attribute Rule are left blank, all resource entities in your model are included in the group.
-
- Remove
-
Removes the selected groups from the collected data.
You use the Statistics table to name and define the statistics to be gathered for the defined groups. Each statistic is represented by a single row in the Statistics table. For each statistic, you set properties (columns in the Statistics table) that define the rules for how the statistic is calculated. Specifically, the Seized, State, and Attribute Rule fields define the resource entity criteria that are used in calculating the statistic.
Resource entities contain resource units, as specified in the ResourceUnits attribute field. A resource entity can represent multiple resource units. The total number of available units of a resource in a group is the sum of the ResourceUnits attribute values for all resource entities in the group. A resource entity must meet all of the specified criteria in order for its associated resource units to be included in the computation of the statistic.
- Add
-
Defines a new statistic in the collected data model. Each statistic represents one variable (column) in the collected data model. A statistic has the following properties: Name, Statistics, Seized, State, and Attribute Rule. You can edit each property directly in the Statistics table.
-
Name specifies the name of the statistic in the data model object.
-
Statistics specifies how to calculate the statistic for each defined resource entity group. The following definitions are used in the statistics descriptions:
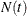 is the total number of resource units in the group at time
is the total number of resource units in the group at time  ,
, 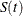 is the number of resource units in the group whose associated resource entity satisfies the criteria at time , and
is the number of resource units in the group whose associated resource entity satisfies the criteria at time , and 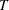 is the simulation run length.
is the simulation run length.
-
%AvgAvail is the percentage of time that the resource units in a group meet the specified criteria relative to the time-averaged number of available resource units in the group during the simulation run. The statistic is computed as a ratio of two time-averaged statistics. The denominator of this ratio is computed as
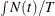 and the numerator of the ratio is computed as
and the numerator of the ratio is computed as 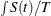 so that the statistic
so that the statistic
%AvgAvail=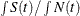 .
.
-
TimeAvg is the time-weighted average of the total number of resource units in the group that satisfy the specified criteria: TimeAvg =
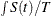 .
.
-
Current is the proportion of resource units in the group that meet the criteria for the statistic, relative to the number of available resource units at time
: Current=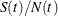 . At the end of a design point replication, Current equals the proportion of resource units in the group that meet the criteria for the statistic when the design point replication
ends. This statistic is particularly useful as an indication of how the proportion of resource units that meet the criteria
changes with time.
. At the end of a design point replication, Current equals the proportion of resource units in the group that meet the criteria for the statistic when the design point replication
ends. This statistic is particularly useful as an indication of how the proportion of resource units that meet the criteria
changes with time.
-
Min is the minimum value of the Current statistic.
-
Max is the maximum value of the Current statistic.
-
Count is the current number of resource units in the group whose associated resource entity meets the criteria for the statistic. At the end of a design point replication, it holds the number of resource units in the group that meet the criteria for the statistic when the design point replication ends.
-
Seized, State, and Attribute Rule are the resource criteria used in calculating the statistic. A resource entity must meet all of the specified criteria in order for its resource units to be included in the statistic.
-
For the Seized criterion, false means a resource entity is available in a resource pool, true means a resource entity is not available in a resource pool, and an empty value means a resource entity can be either seized or unseized.
-
For the State criterion, you can specify that a resource entity must have a particular state. Valid values are Functional, Failed, Maintenance, and Offlined. An empty value means a resource entity can be in any state.
-
For the Attribute Rule criterion, you can specify that a resource entity’s attribute values satisfy a Boolean expression. For more information about how to write the Boolean expression, see Appendix F: Expressions. An empty value means a resource entity’s attributes can have any value.
-
- Remove
-
Removes the selected statistics from the collected data.
- Automatic Save
-
Turns on or off automatic saving of any collected statistics at the end of each design point replication run. If automatic saving is turned on, statistics are saved to a file with the base filename specified in the Base File Name field. Simulation Studio automatically determines the pathname of the folder for this file based on the pathname of the folder that contains your saved project. If the Submit to Remote SAS Workspace Server option is selected, any collected statistics are saved to a file on a remote SAS server. Simulation Studio automatically determines the pathname of the folder for this file on the remote SAS server by using the Default File Path specified in the Simulation Studio Configuration dialog box.
- Save Now
-
Forces the Resource Stats Collector block to attempt an immediate save of any collected statistics. Statistics are saved to the same location as when automatic saving is turned on.
- Location
-
Displays the pathname of the folder for the file in which to save any collected statistics.
- Base File Name
-
Specifies the base filename for the SAS data set or JMP table that is used to save any collected statistics. This name is the prefix of the actual filename. The zero-based index of the design point and the zero-based index of the replication number are added as suffixes to the filename, separated by underscore characters. For example, the statistics for the first replication of the first design point are saved in a file named
BaseFileName_0_0, and the statistics for the second replication of the first design point are saved in a file namedBaseFileName_0_1.