MCHART Statement: SHEWHART Procedure

Input Data Sets
DATA= Data Set
You can read raw data (process measurements) from a DATA= data set specified in the PROC SHEWHART statement. Each process specified in the MCHART statement must be a SAS variable in the DATA= data set. This variable provides measurements that
must be grouped into subgroup samples indexed by the values of the subgroup-variable. The subgroup-variable, which is specified in the MCHART statement, must also be a SAS variable in the DATA= data set. Each observation in a DATA=
data set must contain a value for each process and a value for the subgroup-variable. If the ith subgroup contains 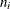 items, there should be consecutive observations for which the value of the subgroup-variable is the index of the ith subgroup. For example, if each subgroup contains five items and there are 30 subgroup samples, the DATA= data set should
contain 150 observations.
items, there should be consecutive observations for which the value of the subgroup-variable is the index of the ith subgroup. For example, if each subgroup contains five items and there are 30 subgroup samples, the DATA= data set should
contain 150 observations.
Other variables that can be read from a DATA= data set include
-
_PHASE_(if the READPHASES= option is specified) -
block-variables
-
symbol-variable
-
BY variables
-
ID variables
By default, the SHEWHART procedure reads all of the observations in a DATA= data set. However, if the DATA= data set includes
the variable _PHASE_, you can read selected groups of observations (referred to as phases) by specifying the READPHASES= option (for an example, see Displaying Stratification in Phases).
For an example of a DATA= data set, see Creating Charts for Medians from Raw Data.
LIMITS= Data Set
You can read preestablished control limits (or parameters from which the control limits can be calculated) from a LIMITS=
data set specified in the PROC SHEWHART statement. For example, the following statements read control limit information from
the data set Conlims:
proc shewhart data=Info limits=Conlims; mchart Weight*Batch; run;
The LIMITS= data set can be an OUTLIMITS= data set that was created in a previous run of the SHEWHART procedure. Such data sets always contain the variables required for a LIMITS= data set. The LIMITS= data set can also be created directly using a DATA step. When you create a LIMITS= data set, you must provide one of the following:
-
the variables
_LCLM_,_MEAN_, and_UCLM_, which specify the control limits directly -
the variables
_MEAN_and_STDDEV_, which are used to calculate the control limits according to the equations in Table 18.23
In addition, note the following:
-
The variables
_VAR_and_SUBGRP_are required. These must be character variables whose lengths are no greater than 32. -
The variable
_INDEX_is required if you specify the READINDEX= option; this must be a character variable whose length is no greater than 48. -
The variables
_LIMITN_,_SIGMAS_(or_ALPHA_), and_TYPE_are optional, but they are recommended to maintain a complete set of control limit information. The variable_TYPE_must be a character variable of length 8; valid values are 'ESTIMATE', 'STANDARD', 'STDMU', and 'STDSIGMA'. -
BY variables are required if specified with a BY statement.
For an example, see the section Reading Preestablished Control Limits.
HISTORY= Data Set
You can read subgroup summary statistics from a HISTORY= data set specified in the PROC SHEWHART statement. This enables you to reuse OUTHISTORY= data sets that have been created in previous runs of the SHEWHART procedure or to read output data sets created with SAS summarization procedures, such as PROC UNIVARIATE.
A HISTORY= data set used with the MCHART statement must contain the following:
-
the subgroup-variable
-
a subgroup mean variable for each process
-
a subgroup median variable for each process
-
a subgroup sample size variable for each process
-
either a subgroup range variable or a subgroup standard deviation variable for each process
The names of the subgroup summary statistics variables must be the process name concatenated with the following special suffix characters:
|
Subgroup Summary Statistic |
Suffix Character |
|---|---|
|
Subgroup median |
M |
|
Subgroup mean |
X |
|
Subgroup sample size |
N |
|
Subgroup range |
R |
|
Subgroup standard deviation |
S |
You must provide the subgroup mean variable only if you specify the MEDCENTRAL= AVGMEAN option. If you specify the STDDEVIATIONS option, the subgroup standard deviation variable must be included; otherwise, the subgroup range variable must be included.
For example, consider the following statements:
proc shewhart history=Summary; mchart (Weight Yieldstrength)*Batch / medcentral=avgmean; run;
The data set Summary must include the variables Batch, WeightX, WeightM, WeightR, WeightN, YieldstrengthX, YieldstrengthM, YieldstrengthR, and YieldstrengthN. If the STDDEVIATIONS option were specified in the preceding MCHART statement, it would be necessary for Summary to include the variables Batch, WeightX, WeightM, WeightS, WeightN, YieldstrengthX, YieldstrengthM, YieldstrengthS, and YieldstrengthN.
Note that if you specify a process name that contains 32 characters, the names of the summary variables must be formed from the first 16 characters and the last 15 characters of the process name, suffixed with the appropriate character.
Other variables that can be read from a HISTORY= data set include
-
_PHASE_(if the READPHASES= option is specified) -
block-variables
-
symbol-variable
-
BY variables
-
ID variables
By default, the SHEWHART procedure reads all the observations in a HISTORY= data set. However, if the data set includes the
variable _PHASE_, you can read selected groups of observations (referred to as phases) by specifying the READPHASES= option (see Displaying Stratification in Phases for an example).
For an example of a HISTORY= data set, see Creating Charts for Medians from Subgroup Summary Data.
TABLE= Data Set
You can read summary statistics and control limits from a TABLE= data set specified in the PROC SHEWHART statement. This enables you to reuse an OUTTABLE= data set created in a previous run of the SHEWHART procedure. Because the SHEWHART procedure simply displays the information in a TABLE= data set, you can use TABLE= data sets to create specialized control charts. Examples are provided in Specialized Control Charts: SHEWHART Procedure.
Table 18.26 lists the variables required in a TABLE= data set used with the MCHART statement.
Table 18.26: Variables Required in a TABLE= Data Set
|
Variable |
Description |
|---|---|
|
|
Lower control limit for median |
|
|
Nominal sample size associated with the control limits |
|
|
Process mean |
|
Subgroup-variable |
Values of the subgroup-variable |
|
|
Subgroup median |
|
|
Subgroup sample size |
|
|
Upper control limit for median |
Other variables that can be read from a TABLE= data set include
-
block-variables
-
symbol-variable
-
BY variables
-
ID variables
-
_PHASE_(if the READPHASES= option is specified). This variable must be a character variable whose length is no greater than 48. -
_TESTS_(if the TESTS= option is specified). This variable is used to flag tests for special causes and must be a character variable of length 8. -
_VAR_. This variable is required if more than one process is specified or if the data set contains information for more than one process. This variable must be a character variable whose length is no greater than 32.
For an example of a TABLE= data set, see Saving Control Limits.