The MVPMODEL Procedure

The MVPMODEL procedure performs principal component analysis (PCA) on multivariate process measurement data that consist of p continuous variables that are assumed to be correlated. The input data set for PROC MVPMODEL provides the values of the p variables that are to be analyzed.
The MVPMODEL procedure computes the following quantities:
-
the loadings from the principal component analysis
-
the eigenvalues from the principal component analysis, which are the variances of the principal component variables
-
the scores from the principal component analysis
-
the
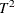 statistic for each observation
statistic for each observation
-
the SPE (squared prediction error) statistic for each observation, also known as SSE, Q, or DModX
By default, principal components are computed from the correlation matrix of the variables. Optionally, they can be computed
from their covariance matrix instead. The number of principal components in the model (denoted by j, where ![]() ) can be specified or determined by one of several cross validation methods.
) can be specified or determined by one of several cross validation methods.
By default, PROC MVPMODEL outputs the correlation matrix of the input variables and the eigenvalues of the correlation matrix. When ODS Graphics is enabled, the output can also include the following plots:
-
a scree plot and a variance-explained plot of the principal components (these plots are created by default)
-
when using cross validation, plots of W and root mean PRESS (predicted residual sum of squares) for each principal component
-
pairwise score plots of principal component scores
-
pairwise loading plots of principal component loadings
PROC MVPMODEL saves information about the principal component model in the following two output data sets, which can subsequently serve as inputs to the MVPMONITOR and MVPDIAGNOSE procedures:
-
an output data set which contains all the variables and observations in the input data set together with observationwise statistics, such as scores, residuals,
, and SPE
-
an output data set that contains the j loadings for each process variable and the eigenvalues associated with each of the principal components