| The OPTEX Procedure |
Constructing a Nonstandard Design
[See OPTEXG1 in the SAS/QC Sample Library]This example shows how you can use the OPTEX procedure to construct a design for a complicated experiment for which no standard design is available.
A chemical company is designing a new reaction process. The engineers have isolated the following five factors that might affect the total yield:
Variable |
Description |
Range |
|---|---|---|
RTemp |
Temperature of the reaction chamber |
150-350 degrees |
Press |
Pressure of the reaction chamber |
10-30 psi |
Time |
Amount of time for the reaction |
3-5 minutes |
Solvent |
Amount of solvent used |
20-25 % |
Source |
Source of raw materials |
1, 2, 3, 4, 5 |
While there are only two solvent levels of interest, the reaction control factors (RTemp, Press, and Time) might be curvilinearly related to the total yield, and thus, require three levels in the experiment. The Source factor is categorical with five levels. Additionally, some combinations of the factors are known to be problematic; simultaneously setting all three reaction control factors to their lowest feasible levels will result in worthless sludge, while setting them all to their highest levels can damage the reactor. Standard experimental designs do not apply to this situation.
Creating the Candidate Set
You can use the OPTEX procedure to generate a design for this experiment. The first step in generating an optimal design is to prepare a data set containing the candidate runs (that is, the feasible factor level combinations). In many cases, this step involves the most work. You can use a variety of SAS data manipulation tools to set up the candidate data set. In this example, the candidate runs are all possible combinations of the factor levels except those with all three control factors at their low levels and at their high levels, respectively. The PLAN procedure (refer to the SAS/STAT 9.22 User's Guide) provides an easy way to create a full factorial data set, which can then be subsetted by using the DATA step, as shown in the following statements:
proc plan ordered;
factors RTemp=3 Press=3 Time=3 Solvent=2 Source=5 / noprint;
output out=Candidate
RTemp nvals=(150 to 350 by 100)
Press nvals=( 10 to 30 by 10)
Time nvals=( 3 to 5 )
Solvent nvals=( 20 to 25 by 5)
Source nvals=( 1 to 5 );
data Candidate; set Candidate;
if (^((RTemp = 150) & (Press = 10) & (Time = 3)));
if (^((RTemp = 350) & (Press = 30) & (Time = 5)));
proc print data=Candidate(obs=10);
run;
A partial listing of the candidate data set Candidate is shown in Figure 10.1.
Generating the Design
The next step is to invoke the OPTEX procedure, specifying the candidate data set as the input data set. You must also provide a model for the experiment by using the MODEL statement, which uses the linear modeling syntax of the GLM procedure (refer to the SAS/STAT 9.22 User's Guide). Since Source is a classification (qualitative) factor, you need to specify it in a CLASS statement. To detect possible crossproduct effects in the other factors, as well as the quadratic effects of the three reaction control factors, you can use a modified response surface model, as shown in the following statements:
proc optex data=Candidate seed=12345;
class Source;
model Source Solvent|RTemp|Press|Time@2
RTemp*RTemp Press*Press Time*Time;
run;
Note that the MODEL statement does not involve a response variable (unlike the MODEL statement in the GLM procedure). The default number of runs for a design is assumed by the OPTEX procedure to be 10 plus the number of parameters (a total of 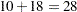 in this case). Thus, the procedure searches for 28 runs among the candidates in Candidate that enable D-optimal estimation of the effects in the model. (See the section Optimality Criteria for a precise definition of D-optimality.) Randomness is built into the search algorithm to overcome the problem of local optima. As such by default, the OPTEX procedure takes 10 random "tries" to find the best design. The output, shown in Figure 10.2, lists efficiency factors for the 10 designs found. These designs are all very close in terms of their D-efficiency.
in this case). Thus, the procedure searches for 28 runs among the candidates in Candidate that enable D-optimal estimation of the effects in the model. (See the section Optimality Criteria for a precise definition of D-optimality.) Randomness is built into the search algorithm to overcome the problem of local optima. As such by default, the OPTEX procedure takes 10 random "tries" to find the best design. The output, shown in Figure 10.2, lists efficiency factors for the 10 designs found. These designs are all very close in terms of their D-efficiency.
| Design Number | D-Efficiency | A-Efficiency | G-Efficiency | Average Prediction Standard Error |
|---|---|---|---|---|
| 1 | 57.0082 | 32.8139 | 78.3162 | 0.8319 |
| 2 | 56.7660 | 27.3874 | 75.8168 | 0.8563 |
| 3 | 56.2145 | 28.7217 | 74.9937 | 0.8594 |
| 4 | 55.8960 | 28.7509 | 74.4196 | 0.8559 |
| 5 | 55.7341 | 29.9372 | 74.4554 | 0.8544 |
| 6 | 55.6224 | 31.4902 | 73.6200 | 0.8626 |
| 7 | 55.5762 | 28.3016 | 75.8959 | 0.8652 |
| 8 | 55.5080 | 30.3889 | 78.4385 | 0.8552 |
| 9 | 55.3366 | 28.5103 | 74.7014 | 0.8614 |
| 10 | 55.2176 | 26.8133 | 76.2307 | 0.8660 |
The final step is to save the best design in a data set. You can do this interactively by submitting the OUTPUT statement immediately after the preceding statements. Then use the PRINT procedure to list the design. The design is listed in Figure 10.3.
output out=Reactor; proc print data=Reactor; run;
| Class Level Information | ||||||
|---|---|---|---|---|---|---|
| Class | Levels | Values | ||||
| Source | 5 | 1 | 2 | 3 | 4 | 5 |
| Factor Ranges | ||
|---|---|---|
| Factor | Low Value | High Value |
| Solvent | 20.000000 | 25.000000 |
| RTemp | 150.000000 | 350.000000 |
| Press | 10.000000 | 30.000000 |
| Time | 3.000000 | 5.000000 |
| Design Number | D-Efficiency | A-Efficiency | G-Efficiency | Average Prediction Standard Error |
|---|---|---|---|---|
| 1 | 57.0082 | 32.8139 | 78.3162 | 0.8319 |
| 2 | 56.7660 | 27.3874 | 75.8168 | 0.8563 |
| 3 | 56.2145 | 28.7217 | 74.9937 | 0.8594 |
| 4 | 55.8960 | 28.7509 | 74.4196 | 0.8559 |
| 5 | 55.7341 | 29.9372 | 74.4554 | 0.8544 |
| 6 | 55.6224 | 31.4902 | 73.6200 | 0.8626 |
| 7 | 55.5762 | 28.3016 | 75.8959 | 0.8652 |
| 8 | 55.5080 | 30.3889 | 78.4385 | 0.8552 |
| 9 | 55.3366 | 28.5103 | 74.7014 | 0.8614 |
| 10 | 55.2176 | 26.8133 | 76.2307 | 0.8660 |
| Obs | Solvent | RTemp | Press | Time | Source |
|---|---|---|---|---|---|
| 1 | 20 | 150 | 20 | 4 | 5 |
| 2 | 20 | 250 | 10 | 5 | 5 |
| 3 | 20 | 350 | 30 | 3 | 5 |
| 4 | 25 | 150 | 30 | 5 | 5 |
| 5 | 25 | 250 | 10 | 3 | 5 |
| 6 | 25 | 350 | 20 | 5 | 5 |
| 7 | 20 | 150 | 10 | 5 | 4 |
| 8 | 20 | 150 | 30 | 3 | 4 |
| 9 | 20 | 350 | 10 | 3 | 4 |
| 10 | 20 | 350 | 20 | 5 | 4 |
| 11 | 25 | 250 | 30 | 4 | 4 |
| 12 | 20 | 250 | 10 | 3 | 3 |
| 13 | 20 | 350 | 30 | 4 | 3 |
| 14 | 25 | 150 | 30 | 3 | 3 |
| 15 | 25 | 350 | 10 | 5 | 3 |
| 16 | 25 | 350 | 20 | 3 | 3 |
| 17 | 20 | 150 | 30 | 5 | 2 |
| 18 | 20 | 250 | 30 | 3 | 2 |
| 19 | 20 | 350 | 10 | 5 | 2 |
| 20 | 25 | 150 | 10 | 4 | 2 |
| 21 | 25 | 250 | 20 | 5 | 2 |
| 22 | 25 | 350 | 30 | 4 | 2 |
| 23 | 20 | 150 | 20 | 3 | 1 |
| 24 | 20 | 250 | 20 | 4 | 1 |
| 25 | 20 | 250 | 30 | 5 | 1 |
| 26 | 25 | 150 | 10 | 5 | 1 |
| 27 | 25 | 350 | 10 | 4 | 1 |
| 28 | 25 | 350 | 30 | 3 | 1 |
Customizing the Number of Runs
The OPTEX procedure provides options with which you can customize many aspects of the design optimization process. Suppose the budget for this experiment can only accommodate 25 runs. You can use the N= option in the GENERATE statement to request a design with this number of runs.
proc optex data=Candidate seed=12345;
class source;
model source Solvent|RTemp|Press|Time@2
RTemp*RTemp Press*Press Time*Time;
generate n=25;
run;
Including Specific Runs
If there are factor combinations that you want to include in the final design, you can use the OPTEX procedure to augment those combinations optimally. For example, suppose you want to force four specific factor combinations to be in the design. If these combinations are saved in a data set, you can force them into the design by specifying the data set with the AUGMENT= option in the GENERATE statement. This technique is demonstrated in the following statements:
data Preset;
input Solvent RTemp Press Time Source;
datalines;
20 350 10 5 4
20 150 10 4 3
25 150 30 3 3
25 250 10 5 3
;
proc optex data=Candidate seed=12345;
class Source;
model Source Solvent|RTemp|Press|Time@2
RTemp*RTemp Press*Press Time*Time;
generate n=25 augment=preset;
output out=Reactor2;
run;
The final design is listed in Figure 10.4. Note that the points in the AUGMENT= data set appear as observations 7, 11, 15, and 16.
Using an Alternative Search Technique
You can also specify a variety of optimization methods with the GENERATE statement. The default method is relatively fast; while other methods might find better designs, they take longer to run and the improvement is usually only marginal. The method that generally finds the best designs is the Fedorov procedure described by Fedorov (1972). The following statements show how to request this method:
proc optex data=Candidate seed=12345;
class Source;
model Source Solvent|RTemp|Press|Time@2
RTemp*RTemp Press*Press Time*Time;
generate n=25 method=fedorov;
output out=Reactor2;
run;
proc print data=Reactor2; run;
| Obs | Solvent | RTemp | Press | Time | Source |
|---|---|---|---|---|---|
| 1 | 20 | 150 | 30 | 5 | 5 |
| 2 | 20 | 250 | 20 | 4 | 5 |
| 3 | 20 | 350 | 10 | 3 | 5 |
| 4 | 25 | 150 | 10 | 4 | 5 |
| 5 | 25 | 350 | 20 | 5 | 5 |
| 6 | 25 | 350 | 30 | 3 | 5 |
| 7 | 20 | 150 | 20 | 3 | 4 |
| 8 | 20 | 350 | 30 | 4 | 4 |
| 9 | 25 | 150 | 30 | 5 | 4 |
| 10 | 25 | 250 | 10 | 5 | 4 |
| 11 | 20 | 150 | 10 | 4 | 3 |
| 12 | 20 | 250 | 30 | 5 | 3 |
| 13 | 25 | 150 | 10 | 5 | 3 |
| 14 | 25 | 150 | 30 | 3 | 3 |
| 15 | 25 | 350 | 20 | 3 | 3 |
| 16 | 20 | 150 | 30 | 3 | 2 |
| 17 | 20 | 350 | 10 | 5 | 2 |
| 18 | 25 | 150 | 20 | 5 | 2 |
| 19 | 25 | 250 | 10 | 3 | 2 |
| 20 | 25 | 350 | 30 | 4 | 2 |
| 21 | 20 | 150 | 10 | 5 | 1 |
| 22 | 20 | 350 | 30 | 3 | 1 |
| 23 | 25 | 150 | 20 | 3 | 1 |
| 24 | 25 | 250 | 30 | 5 | 1 |
| 25 | 25 | 350 | 10 | 4 | 1 |
The efficiencies for the resulting designs are shown in Figure 10.5.
| Design Number | D-Efficiency | A-Efficiency | G-Efficiency | Average Prediction Standard Error |
|---|---|---|---|---|
| 1 | 56.9072 | 27.6680 | 75.2161 | 0.9023 |
| 2 | 56.8715 | 27.4939 | 72.8202 | 0.9058 |
| 3 | 56.6148 | 27.7799 | 75.1840 | 0.9031 |
| 4 | 56.3021 | 31.4247 | 76.0654 | 0.9044 |
| 5 | 56.0569 | 25.4498 | 70.2491 | 0.9290 |
| 6 | 55.9501 | 26.8714 | 75.6991 | 0.9144 |
| 7 | 55.8461 | 29.0473 | 74.1291 | 0.9138 |
| 8 | 55.8355 | 26.9242 | 76.8595 | 0.9062 |
| 9 | 55.7253 | 27.4625 | 74.3391 | 0.9189 |
| 10 | 55.6071 | 26.3825 | 74.1827 | 0.9107 |
In this case, the Fedorov procedure takes several times longer than the default method, and D-efficiency shows no improvement. On the other hand, the longer search method often does improve the design and might take only a few seconds on a reasonably fast computer.
Copyright © SAS Institute, Inc. All Rights Reserved.