| The CAPABILITY Procedure |
Dictionary of Options
The following entries describe in detail the options specific to the COMPHISTOGRAM statement. The note Traditional Graphics identifies options that can be used only with traditional graphics output. See Dictionary of Common Options for detailed descriptions of options common to all the plot statements.
- BARLABEL=COUNT | PERCENT | PROPORTION
[Traditional Graphics] displays labels above the histogram bars. If you specify BARLABEL=COUNT, the label shows the number of observations associated with a given bar. BARLABEL=PERCENT shows the percent of observations represented by that bar. If you specify BARLABEL=PROPORTION, the label displays the proportion of observations associated with the bar.
- BARWIDTH=value
[Traditional Graphics] specifies the width of the histogram bars in screen percent units.
- C=value-list | MISE
specifies the standardized bandwidth parameter
 for kernel density estimates requested with the KERNEL option. You can specify up to five values to display multiple estimates in each cell. You can also specify the keyword MISE to request the bandwidth parameter that minimizes the estimated mean integrated square error (MISE). For example, consider the following statements (for more information, see Kernel Density Estimates):
for kernel density estimates requested with the KERNEL option. You can specify up to five values to display multiple estimates in each cell. You can also specify the keyword MISE to request the bandwidth parameter that minimizes the estimated mean integrated square error (MISE). For example, consider the following statements (for more information, see Kernel Density Estimates): proc capability; comphist length / class=batch kernel(c = 0.5 1.0 mise); run;
The KERNEL option displays three density estimates. The first two have standardized bandwidths of 0.5 and 1.0, respectively. The third has a bandwidth parameter that minimizes the MISE. You can also use the C= and K= options (K= specifies kernel type) to display multiple estimates. For example, consider the following statements:
proc capability; comphist length / class = batch kernel(c = 0.75 k = normal triangular); run;Here two estimates are displayed. The first uses a normal kernel and bandwidth parameter of 0.75, and the second uses a triangular kernel and a bandwidth parameter of 0.75. In general, if more kernel types are specified than bandwidth parameters, the last bandwidth parameter in the list will be repeated for the remaining estimates. Likewise, if more bandwidth parameters are specified than kernel types, the last kernel type will be repeated for the remaining estimates. The default is MISE.
- CBARLINE=color
[Traditional Graphics] specifies the color of the outline of the histogram bars. This option overrides the C= option in the SYMBOL1 statement.
- CFILL=color
[Traditional Graphics] specifies a color used to fill the bars of the histograms (or the areas under a fitted curve if you also specify the FILL option). See the entry for the FILL option for additional details. See Output 5.6.1 and Example 5.7 for examples. Refer to SAS/GRAPH: Reference for a list of colors. By default, bars and curve areas are not filled.
- CFRAMENLEG=color | EMPTY
- CFRAMENLEG
[Traditional Graphics] specifies that the legend requested with the NLEGEND option (or the variable _TILELB_ in a CLASSSPEC= data set) is to be framed and that the frame is to be filled with the color indicated. If you specify CFRAMENLEG=EMPTY, a frame is drawn but not filled with a color.
- CGRID=color
[Traditional Graphics] specifies the color for grid lines requested with the GRID option. By default, grid lines are the same color as the axes. If you use CGRID=, you do not need to specify the GRID option.
- CLASS=variable
- CLASS=(variable1 variable2)
specifies that a comparative histogram is to be created using the levels of the variables (also referred to as class-variables or classification variables).
If you specify a single variable, a one-way comparative histogram is created. The observations in the input data set are sorted by the formatted values (levels) of the variable. A separate histogram is created for the process variable values in each level, and these component histograms are arranged in an array to form the comparative histogram. Uniform horizontal and vertical axes are used to facilitate comparisons. For an example, see Figure 5.5.2.
If you specify two classification variables, a two-way comparative histogram is created. The observations in the input data set are cross-classified according to the values (levels) of these variables. A separate histogram is created for the process variable values in each cell of the cross-classification, and these component histograms are arranged in a matrix to form the comparative histogram. The levels of variable1 are used to label the rows of the matrix, and the levels of variable2 are used to label the columns of the matrix. Uniform horizontal and vertical axes are used to facilitate comparisons. For an example, see Output 5.7.1.
Classification variables can be numeric or character. Formatted values are used to determine the levels. You can specify whether missing values are to be treated as a level with the MISSING1 and MISSING2 options.
If a label is associated with a classification variable, the label is displayed on the comparative histogram. The variable label is displayed parallel to the column (or row) labels. For an example, see Figure 5.5.2.
- CLASSKEY='value'
- CLASSKEY=('value1' 'value2')
specifies the key cell in a comparative histogram requested with the CLASS= option. The bin size and midpoints are first determined for the key cell, and then the midpoint list is extended to accommodate the data ranges for the remaining cells. Thus, the choice of the key cell determines the uniform horizontal axis used for all cells.
If you specify CLASS=variable, you can specify CLASSKEY=’value’ to identify the key cell as the level for which variable is equal to value. You must specify a formatted value. By default, the levels are sorted in the order determined by the ORDER1= option, and the key cell is the level that occurs first in this order. The cells are displayed in this order from top to bottom (or left to right), and, consequently, the key cell is displayed at the top or at the left. If you specify a different key cell with the CLASSKEY= option, this cell is displayed at the top or at the left unless you also specify the NOKEYMOVE option.
If you specify CLASS=(variable1 variable2), you can specify CLASSKEY=(’value1’ ’value2’) to identify the key cell as the level for which variable1 is equal to value1 and variable2 is equal to value2. Here, value1 and value2 must be formatted values, and they must be enclosed in quotes. For an example of the CLASSKEY= option with a two-way comparative histogram, see Output 5.7.1. By default, the levels of variable1 are sorted in the order determined by the ORDER1= option, and within each of these levels, the levels of variable2 are sorted in the order determined by the ORDER2= option. The default key cell is the combination of levels of variable1 and variable2 that occurs first in this order. The cells are displayed in order of variable1 from top to bottom and in order of variable2 from left to right. Consequently, the default key cell is displayed in the upper left corner. If you specify a different key cell with the CLASSKEY= option, this cell is displayed in the upper left corner unless you also specify the NOKEYMOVE option.
- CLASSSPEC=SAS-data-set
- CLASSSPECS=SAS-data-set
specifies a data set that provides distinct specification limits for each cell, as well as a color, legend, and label for the corresponding tile. The following table lists the variables that are read from a CLASSSPECS= data set:
Variable Name
Description
BY variables
subsets the data set
Classification variables
specifies the structure of the comparative histogram
_VAR_
specifies name of process variable (must be character variable of length 8)
_LSL_
specifies lower specification limit for tile
_TARGET_
specifies target value for tile
_USL_
specifies upper specification limit for tile
_CTILE_
specifies background color for tiles (must be character variable of length 8)
_TILELG_
specifies text displayed in color tile legend at bottom of comparative histogram (character variable of length not greater than 16)
_TILELB_
specifies text displayed in corner of each tile (character variable of length not greater than 16)
If you specify a CLASSSPEC= data set, you cannot use the SPEC statement or a SPEC= data set. If you use a BY statement, the CLASSSPEC= data set must contain one observation for each unique combination of process and classification variables within each BY group. See Example 5.6 for an example of a CLASSSPECS= data set.
Also note that
you can suppress the background color for a tile by assigning the value 'EMPTY' or a blank value to the variable _CTILE_
you can use the NLEGENDPOS= option to specify the corner of the tile in which the _TILELB_ label is displayed. You can frame the label with the CFRAMENLEG= option.
you cannot use the variable _TILELG_ unless you specify the variable _CTILE_
the variable _TILELB_ takes precedence over the NLEGEND option
- CLIPSPEC=CLIP | NOFILL
[Traditional Graphics] specifies that histogram bars are clipped at the upper and lower specification limit lines when there are no observations outside the specification limits. The bar intersecting the lower specification limit is clipped if there are no observations less than the lower limit; the bar intersecting the upper specification limit is clipped if there are no observations greater than the upper limit. If you specify CLIPSPEC=CLIP, the histogram bar is truncated at the specification limit. If you specify CLIPSPEC=NOFILL, the portion of a filled histogram bar outside the specification limit is left unfilled. Specifying CLIPSPEC=NOFILL when histogram bars are not filled has no effect.
- ENDPOINTS=value-list | KEY | UNIFORM
specifies that histogram interval endpoints, rather than midpoints, are aligned with horizontal axis tick marks, and specifies how the endpoints are determined. The method you specify is used for all process variables analyzed with the COMPHISTOGRAM statement.
If you specify ENDPOINTS=value-list, the values must be listed in increasing order and must be evenly spaced. The difference between consecutive endpoints is used as the width of the histogram bars. The first value is the lower bound of the first histogram bin and the last value is the upper bound of the last bin. Thus, the number of values in the list is one greater than the number of bins it specifies. If the range of the values does not cover the range of the data as well as any specification limits (LSL and USL) that are given, the list is extended in either direction as necessary.
If you specify ENDPOINTS=KEY, the procedure first determines the endpoints for the data in the key cell. The initial number of endpoints is based on the number of observations in the key cell by using the method of Terrell and Scott (1985). The endpoint list for the key cell is then extended in either direction as necessary until it spans the data in the remaining cells. If the key cell contains no observations, the method of determining bins reverts to ENDPOINTS=UNIFORM.
If you specify ENDPOINTS=UNIFORM, the procedure determines the endpoints by using all the observations as if there were no cells. In other words, the number of endpoints is computed from the total sample size by using the method of Terrell and Scott (1985).
- FILL
fills areas under a fitted density curve with colors and patterns. Enclose the FILL option in parentheses after the keyword NORMAL or KERNEL. Depending on the area to be filled (outside or between the specification limits), you can specify the color and pattern with options in the SPEC statement and the COMPHISTOGRAM statement, as summarized in the following table:
Area Under Curve
Statement
Option
between specification
COMPHIST
CFILL=color
limits
COMPHIST
PFILL=pattern
left of lower
SPEC
CLEFT=color
specification limit
SPEC
PLEFT=pattern
right of upper
SPEC
CRIGHT=color
specification limit
SPEC
PRIGHT=pattern
If you do not display specification limits, you can use the CFILL= and PFILL= options to specify the color and pattern for the entire area under the curve. Solid fills are used by default if patterns are not specified. You can specify the FILL option with only one fitted curve. For an example, see Output 5.6.1. Refer to SAS/GRAPH: Reference for a list of available patterns and colors. If you do not specify the FILL option but you do specify the options in the preceding table, the colors and patterns are applied to the corresponding areas under the histogram.
- FRONTREF
[Traditional Graphics]draws reference lines requested with the HREF= and VREF= options in front of the histogram bars. By default, reference lines are drawn behind the histogram bars and can be obscured by them.
- GRID
adds a grid to the comparative histogram. Grid lines are horizontal lines positioned at major tick marks on the vertical axis.
- HOFFSET=value
[Traditional Graphics] specifies the offset in percent screen units at both ends of the horizontal axis. Specify HOFFSET=0 to eliminate the default offset.
- INTERTILE=value
specifies the distance in horizontal percent screen units between tiles. For an example, see Figure 5.5.3. By default, the tiles are contiguous.
- K=NORMAL | TRIANGULAR | QUADRATIC
specifies the type of kernel (normal, triangular, or quadratic) used to compute kernel density estimates requested with the KERNEL option. Enclose the K= option in parentheses after the keyword KERNEL. You can specify a single type or a list of types. If you specify more estimates than types, the last kernel type in the list is used for the remaining estimates. By default, a normal kernel is used.
- KERNEL<( kernel-options )>
requests a kernel density estimate for each cell of the comparative histogram. You can specify the kernel-options described in the following table:
Option
Description
FILL
specifies that the area under the curve is to be filled
COLOR=
specifies the color of the curve
L=
specifies the line style for the curve
W=
specifies the width of the curve
K=
specifies the type of kernel
C=
specifies the smoothing parameter
LOWER=
specifies the lower bound for the curve
UPPER=
specifies the upper bound for the curve
See Output 5.6.1 for an example. By default, the estimate is based on the AMISE method. For more information, see Kernel Density Estimates.
- LOWER=value
specifies the lower bound for a kernel density estimate curve. Enclose the LOWER= option in parentheses after the KERNEL option. You can specify a single lower bound or a list of lower bounds. By default, a kernel density estimate curve has no lower bound.
-
LGRID=

[Traditional Graphics] specifies the line type for the grid requested with the GRID option. If you use the LGRID= option, you do not need to specify the GRID option. The default is 1, which produces a solid line.
-
MAXNBIN=
specifies the maximum number of bins to be displayed. This option is useful in situations where the scales or ranges of the data distributions differ greatly from cell to cell. By default, the bin size and midpoints are determined for the key cell, and then the midpoint list is extended to accommodate the data ranges for the remaining cells. However, if the cell scales differ considerably, the resulting number of bins may be so great that each cell histogram is scaled into a narrow region. By limiting the number of bins with the MAXNBIN= option, you can narrow the window about the data distribution in the key cell. Note that the MAXNBIN= option provides an alternative to the MAXSIGMAS= option.
- MAXSIGMAS=value
limits the number of bins to be displayed to a range of value standard deviations (of the data in the key cell) above and below the mean of the data in the key cell. This option is useful in situations where the scales or ranges of the data distributions differ greatly from cell to cell. By default, the bin size and midpoints are determined for the key cell, and then the midpoint list is extended to accommodate the data ranges for the remaining cells. If the cell scales differ considerably, however, the resulting number of bins may be so great that each cell histogram is scaled into a narrow region. By limiting the number of bins with the MAXSIGMAS= option, you narrow the window about the data distribution in the key cell. Note that the MAXSIGMAS= option provides an alternative to the MAXNBIN= option.
- MIDPOINTS=value-list | KEY | UNIFORM
specifies how midpoints are determined for the bins in the comparative histogram. The method you specify is used for all process variables analyzed with the COMPHISTOGRAM statement.
If you specify MIDPOINTS=value-list, the values must be listed in increasing order and must be evenly spaced. The difference between consecutive midpoints is used as the width of the histogram bars. If the range of the values does not cover the range of the data as well as any specification limits (LSL and USL) that are given, the list is extended in either direction as necessary. See Example 5.6 for an illustration.
If you specify MIDPOINTS=KEY, the procedure first determines the midpoints for the data in the key cell. The initial number of midpoints is based on the number of observations in the key cell by using the method of Terrell and Scott (1985). The midpoint list for the key cell is then extended in either direction as necessary until it spans the data in the remaining cells.
If you specify MIDPOINTS=UNIFORM, the procedure determines the midpoints using all the observations as if there were no cells. In other words, the number of midpoints is computed from the total sample size by using the method of Terrell and Scott (1985).
By default, MIDPOINTS=KEY. However, if the key cell contains no observations, the default is MIDPOINTS=UNIFORM.
- MISSING1
specifies that missing values of the first CLASS= variable are to be treated as a level of the CLASS= variable. If the first CLASS= variable is a character variable, a missing value is defined as a blank internal (unformatted) value. If the process variable is numeric, a missing value is defined as any of the SAS System missing values. If you do not specify MISSING1, observations for which the first CLASS= variable is missing are excluded from the analysis.
- MISSING2
specifies that missing values of the second CLASS= variable are to be treated as a level of the CLASS= variable. If the second CLASS= variable is a character variable, a missing value is defined as a blank internal (unformatted) value. If the process variable is numeric, a missing value is defined as any of the SAS System missing values. If you do not specify MISSING2, observations for which the second CLASS= variable is missing are excluded from the analysis.
- MU=value
specifies the parameter
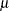 for the normal density curves requested with the NORMAL option. Enclose the MU= option in parentheses after the NORMAL option. The default value is the sample mean of the observations in the cell.
for the normal density curves requested with the NORMAL option. Enclose the MU= option in parentheses after the NORMAL option. The default value is the sample mean of the observations in the cell. - NLEGEND<=’label’>
[Traditional Graphics] specifies the form of a legend that is displayed inside each tile and indicates the sample size of the cell. The following two forms are available:
If you specify the NLEGEND option, the form is
 where is the cell sample size.
where is the cell sample size. If you specify the NLEGEND=’label’ option, the form is label
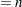 where is the cell sample size. The label can be up to 16 characters and must be enclosed in quotes. For instance, you might specify NLEGEND=’Number of Parts’ to request a label of the form Number of Parts .
where is the cell sample size. The label can be up to 16 characters and must be enclosed in quotes. For instance, you might specify NLEGEND=’Number of Parts’ to request a label of the form Number of Parts .
See Figure 5.5.2 for an example. You can use the CFRAMENLEG= option to frame the sample size legend. The variable _TILELB_ in a CLASSSPECS= data set overrides the NLEGEND option. By default, no legend is displayed.
- NLEGENDPOS=NW | NE
[Traditional Graphics] specifies the position of the legend requested with the NLEGEND option or the variable _TILELB_ in a CLASSSPEC= data set. If NLEGENDPOS=NW, the legend is displayed in the northwest corner of the tile; if NLEGENDPOS=NE, the legend is displayed in the northeast corner of the tile. See Figure 5.5.2 for an illustration. The default is NE.
- NOBARS
suppresses the display of the bars in a comparative histogram.
- NOCHART
suppresses the creation of a comparative histogram. This is an alias for NOPLOT.
- NOKEYMOVE
suppresses the rearrangement of cells that occurs by default when you use the CLASSKEY= option to specify the key cell. For details, see the entry for the CLASSKEY= option.
- NOPLOT
suppresses the creation of a comparative histogram. This option is useful when you are using the COMPHISTOGRAM statement solely to create an output data set.
- NORMAL<(normal-options)>
displays a normal density curve for each cell of the comparative histogram. The equation of the normal density curve is
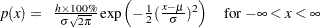
where
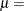 mean
mean 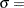 standard deviation
standard deviation 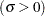
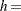 width of histogram interval
width of histogram interval If you specify values for
and  with the MU= and SIGMA= normal-options, the same curve is displayed for each cell. By default, a distinct curve is displayed for each cell based on the sample mean and standard deviation for that cell. For example, the following statements display a distinct curve for each level of the variable Supplier:
with the MU= and SIGMA= normal-options, the same curve is displayed for each cell. By default, a distinct curve is displayed for each cell based on the sample mean and standard deviation for that cell. For example, the following statements display a distinct curve for each level of the variable Supplier: proc capability noprint; comphist width / class=supplier normal(color=red l=2); run;
The curves are drawn in red with a line style of 2 (a dashed line). See Figure 5.5.3 for another illustration. Table 5.14 lists options that can be specified in parentheses after the NORMAL option.
- ORDER1=INTERNAL | FORMATTED | DATA | FREQ
specifies the display order for the values of the first CLASS= variable.
The levels of the first CLASS= variable are always constructed using the formatted values of the variable, and the formatted values are always used to label the rows (columns) of a comparative histogram. You can use the ORDER1= option to determine the order of the rows (columns) corresponding to these values, as follows:
If you specify ORDER1=INTERNAL, the rows (columns) are displayed from top to bottom (left to right) in increasing order of the internal (unformatted) values of the first CLASS= variable. If there are two or more distinct internal values with the same formatted value, then the order is determined by the internal value that occurs first in the input data set.
For example, suppose that you specify a numeric CLASS= variable called Day (with values 1, 2, and 3). Suppose also that a format (created with the FORMAT procedure) is associated with Day and that the formatted values are as follows: 1 = ’Wednesday’, 2 = ’Thursday’, and 3 = ’Friday’. If you specify ORDER1=INTERNAL, the rows of the comparative histogram will appear in day-of-the-week order (Wednesday, Thursday, Friday) from top to bottom.
If you specify ORDER1=FORMATTED, the rows (columns) are displayed from top to bottom (left to right) in increasing order of the formatted values of the first CLASS= variable. In the preceding illustration, if you specify ORDER1=FORMATTED, the rows will appear in alphabetical order (Friday, Thursday, Wednesday) from top to bottom.
If you specify ORDER1=DATA, the rows (columns) are displayed from top to bottom (left to right) in the order in which the values of the first CLASS= variable first appear in the input data set.
If you specify ORDER1=FREQ, the rows (columns) are displayed from top to bottom (left to right) in order of decreasing frequency count. If two or more classes have the same frequency count, the order is determined by the formatted values.
By default, ORDER1=INTERNAL.
- ORDER2=INTERNAL | FORMATTED | DATA | FREQ
specifies the display order for the values of the second CLASS= variable.
The levels of the second CLASS= variable are always constructed using the formatted values of the variable, and the formatted values are always used to label the columns of a two-way comparative histogram. You can use the ORDER2= option to determine the order of the columns.
The layout of a two-way comparative histogram is determined by using the ORDER1= option to obtain the order of the rows from top to bottom (recall that ORDER1=INTERNAL by default). Then the ORDER2= option is applied to the observations corresponding to the first row to obtain the order of the columns from left to right. If any columns remain unordered (that is, the categories are unbalanced), the ORDER2= option is applied to the observations in the second row, and so on, until all the columns have been ordered.
The values of the ORDER2= option are interpreted as described for the ORDER1= option. By default, ORDER2=INTERNAL.
- OUTHISTOGRAM=SAS-data-set
creates a SAS data set that saves the midpoints or endpoints of the histogram intervals, the observed percent of observations in each interval, and (optionally) the percent of observations in each interval estimated from a fitted normal distribution. By default, interval midpoint values are saved in the variable _MIDPT_. If the ENDPOINTS= option is specified, intervals are identified by endpoint values instead. If RTINCLUDE is specified, the _MAXPT_ variable contains upper endpoint values. Otherwise, lower endpoint values are saved in the _MINPT_ variable.
- PFILL=pattern
[Traditional Graphics] specifies a pattern used to fill the bars of the histograms (or the areas under a fitted curve if you also specify the FILL option). See the entries for the CFILL= and FILL options for additional details. Refer to SAS/GRAPH: Reference for a list of pattern values. By default, the bars and curve areas are not filled.
- RTINCLUDE
includes the right endpoint of each histogram interval in that interval. The left endpoint is included by default.
- SIGMA=value
specifies the parameter
for normal density curves requested with the NORMAL option. Enclose the SIGMA= option in parentheses after the NORMAL option. The default value is the sample standard deviation of the observations in the cell. - TILELEGLABEL=’label’
[Traditional Graphics] specifies a label displayed to the left of the legend that is created when you provide _CTILE_ and _TILELG_ variables in a CLASSSPEC= data set. The label can be up to 16 characters and must be enclosed in quotes. The default label is Tiles:.
- UPPER=value
specifies the upper bound for a kernel density estimate curve. Enclose the UPPER= option in parentheses after the KERNEL option. You can specify a single upper bound or a list of upper bounds. By default, a kernel density estimate curve has no upper bound.
- VOFFSET=value
[Traditional Graphics] specifies the offset in percent screen units at the upper end of the vertical axis.
- VSCALE=PERCENT | COUNT | PROPORTION
specifies the scale of the vertical axis. The value COUNT scales the data in units of the number of observations per data unit. The value PERCENT scales the data in units of percent of observations per data unit. The value PROPORTION scales the data in units of proportion of observations per data unit. The default is PERCENT.
-
WBARLINE=
[Traditional Graphics] specifies the width of bar outlines. By default,
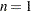 .
. -
WGRID=
[Traditional Graphics] specifies the width of the grid lines requested with the GRID option. By default, grid lines are the same width as the axes. If you use the WGRID= option, you do not need to specify the GRID option.
Copyright © SAS Institute, Inc. All Rights Reserved.