| The UNIVARIATE Procedure |
| Goodness-of-Fit Tests |
When you specify the NORMAL option in the PROC UNIVARIATE statement or you request a fitted parametric distribution in the HISTOGRAM statement, the procedure computes goodness-of-fit tests for the null hypothesis that the values of the analysis variable are a random sample from the specified theoretical distribution. See Example 4.22.
When you specify the NORMAL option, these tests, which are summarized in the output table labeled "Tests for Normality," include the following:
Shapiro-Wilk test
Kolmogorov-Smirnov test
Anderson-Darling test
Cramér-von Mises test
The Kolmogorov-Smirnov 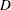 statistic, the Anderson-Darling statistic, and the Cramér-von Mises statistic are based on the empirical distribution function (EDF). However, some EDF tests are not supported when certain combinations of the parameters of a specified distribution are estimated. See Table 4.84 for a list of the EDF tests available. You determine whether to reject the null hypothesis by examining the
statistic, the Anderson-Darling statistic, and the Cramér-von Mises statistic are based on the empirical distribution function (EDF). However, some EDF tests are not supported when certain combinations of the parameters of a specified distribution are estimated. See Table 4.84 for a list of the EDF tests available. You determine whether to reject the null hypothesis by examining the 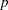 -value that is associated with a goodness-of-fit statistic. When the -value is less than the predetermined critical value (
-value that is associated with a goodness-of-fit statistic. When the -value is less than the predetermined critical value ( ), you reject the null hypothesis and conclude that the data did not come from the specified distribution.
), you reject the null hypothesis and conclude that the data did not come from the specified distribution.
If you want to test the normality assumptions for analysis of variance methods, beware of using a statistical test for normality alone. A test’s ability to reject the null hypothesis (known as the power of the test) increases with the sample size. As the sample size becomes larger, increasingly smaller departures from normality can be detected. Because small deviations from normality do not severely affect the validity of analysis of variance tests, it is important to examine other statistics and plots to make a final assessment of normality. The skewness and kurtosis measures and the plots that are provided by the PLOTS option, the HISTOGRAM statement, the PROBPLOT statement, and the QQPLOT statement can be very helpful. For small sample sizes, power is low for detecting larger departures from normality that may be important. To increase the test’s ability to detect such deviations, you may want to declare significance at higher levels, such as 0.15 or 0.20, rather than the often-used 0.05 level. Again, consulting plots and additional statistics can help you assess the severity of the deviations from normality.
Shapiro-Wilk Statistic
If the sample size is less than or equal to 2000 and you specify the NORMAL option, PROC UNIVARIATE computes the Shapiro-Wilk statistic, 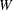 (also denoted as
(also denoted as 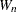 to emphasize its dependence on the sample size
to emphasize its dependence on the sample size  ). The statistic is the ratio of the best estimator of the variance (based on the square of a linear combination of the order statistics) to the usual corrected sum of squares estimator of the variance (Shapiro and Wilk; 1965). When is greater than three, the coefficients to compute the linear combination of the order statistics are approximated by the method of Royston (1992). The statistic is always greater than zero and less than or equal to one
). The statistic is the ratio of the best estimator of the variance (based on the square of a linear combination of the order statistics) to the usual corrected sum of squares estimator of the variance (Shapiro and Wilk; 1965). When is greater than three, the coefficients to compute the linear combination of the order statistics are approximated by the method of Royston (1992). The statistic is always greater than zero and less than or equal to one  .
.
Small values of lead to the rejection of the null hypothesis of normality. The distribution of is highly skewed. Seemingly large values of (such as 0.90) may be considered small and lead you to reject the null hypothesis. The method for computing the -value (the probability of obtaining a statistic less than or equal to the observed value) depends on . For 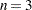 , the probability distribution of is known and is used to determine the -value. For
, the probability distribution of is known and is used to determine the -value. For 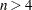 , a normalizing transformation is computed:
, a normalizing transformation is computed:
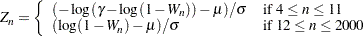 |
The values of  ,
, 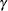 , and
, and 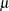 are functions of obtained from simulation results. Large values of
are functions of obtained from simulation results. Large values of 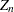 indicate departure from normality, and because the statistic has an approximately standard normal distribution, this distribution is used to determine the -values for .
indicate departure from normality, and because the statistic has an approximately standard normal distribution, this distribution is used to determine the -values for .
EDF Goodness-of-Fit Tests
When you fit a parametric distribution, PROC UNIVARIATE provides a series of goodness-of-fit tests based on the empirical distribution function (EDF). The EDF tests offer advantages over traditional chi-square goodness-of-fit test, including improved power and invariance with respect to the histogram midpoints. For a thorough discussion, refer to D’Agostino and Stephens (1986).
The empirical distribution function is defined for a set of independent observations 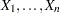 with a common distribution function
with a common distribution function  . Denote the observations ordered from smallest to largest as
. Denote the observations ordered from smallest to largest as 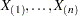 . The empirical distribution function,
. The empirical distribution function, 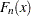 , is defined as
, is defined as
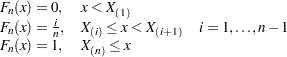 |
Note that is a step function that takes a step of height 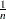 at each observation. This function estimates the distribution function . At any value
at each observation. This function estimates the distribution function . At any value  , is the proportion of observations less than or equal to , while is the probability of an observation less than or equal to . EDF statistics measure the discrepancy between and .
, is the proportion of observations less than or equal to , while is the probability of an observation less than or equal to . EDF statistics measure the discrepancy between and .
The computational formulas for the EDF statistics make use of the probability integral transformation 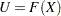 . If
. If  is the distribution function of
is the distribution function of 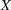 , the random variable
, the random variable  is uniformly distributed between 0 and 1.
is uniformly distributed between 0 and 1.
Given observations , the values 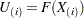 are computed by applying the transformation, as discussed in the next three sections.
are computed by applying the transformation, as discussed in the next three sections.
PROC UNIVARIATE provides three EDF tests:
Kolmogorov-Smirnov
Anderson-Darling
Cramér-von Mises
The following sections provide formal definitions of these EDF statistics.
Kolmogorov D Statistic
The Kolmogorov-Smirnov statistic () is defined as
 |
The Kolmogorov-Smirnov statistic belongs to the supremum class of EDF statistics. This class of statistics is based on the largest vertical difference between and .
The Kolmogorov-Smirnov statistic is computed as the maximum of 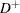 and
and  , where is the largest vertical distance between the EDF and the distribution function when the EDF is greater than the distribution function, and is the largest vertical distance when the EDF is less than the distribution function.
, where is the largest vertical distance between the EDF and the distribution function when the EDF is greater than the distribution function, and is the largest vertical distance when the EDF is less than the distribution function.
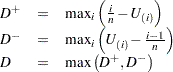 |
PROC UNIVARIATE uses a modified Kolmogorov statistic to test the data against a normal distribution with mean and variance equal to the sample mean and variance.
Anderson-Darling Statistic
The Anderson-Darling statistic and the Cramér-von Mises statistic belong to the quadratic class of EDF statistics. This class of statistics is based on the squared difference  . Quadratic statistics have the following general form:
. Quadratic statistics have the following general form:
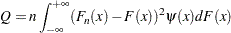 |
The function 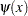 weights the squared difference
weights the squared difference 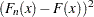 .
.
The Anderson-Darling statistic (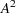 ) is defined as
) is defined as
 |
Here the weight function is 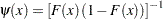 .
.
The Anderson-Darling statistic is computed as
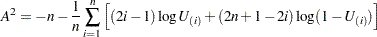 |
Cramér-von Mises Statistic
The Cramér-von Mises statistic (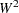 ) is defined as
) is defined as
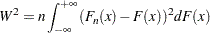 |
Here the weight function is  .
.
The Cramér-von Mises statistic is computed as
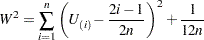 |
Probability Values of EDF Tests
Once the EDF test statistics are computed, PROC UNIVARIATE computes the associated probability values (-values). The UNIVARIATE procedure uses internal tables of probability levels similar to those given by D’Agostino and Stephens (1986). If the value is between two probability levels, then linear interpolation is used to estimate the probability value.
The probability value depends upon the parameters that are known and the parameters that are estimated for the distribution. Table 4.84 summarizes different combinations fitted for which EDF tests are available.
Distribution |
Parameters |
Tests Available |
||
|---|---|---|---|---|
Threshold |
Scale |
Shape |
||
beta |
|
|
|
all |
|
|
|
all |
|
exponential |
|
|
all |
|
|
|
all |
||
|
|
all |
||
|
|
all |
||
gamma |
|
|
|
all |
|
|
|
all |
|
|
|
|
all |
|
|
|
|
all |
|
|
|
|
all |
|
|
|
|
all |
|
|
|
|
all |
|
|
|
|
all |
|
lognormal |
|
|
|
all |
|
|
|
|
|
|
|
|
|
|
|
|
|
all |
|
|
|
|
all |
|
|
|
|
all |
|
|
|
|
all |
|
|
|
|
all |
|
normal |
|
|
all |
|
|
|
|
||
|
|
|
||
|
|
all |
||
Weibull |
|
|
|
all |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
all |
|
|
|
|
all |
|
|
|
|
all |
|
|
|
|
all |
|
 known
known known
known  unknown
unknown  unknown
unknown  known
known  known
known  known
known  known
known  known
known  known
known  known
known Copyright © SAS Institute, Inc. All Rights Reserved.