The HPIMPUTE Procedure

Obtaining the Statistics for Imputation
PROC HPIMPUTE first computes the imputation value and then imputes with that value. Some statistics (such as the mean, minimum, and maximum) are computed precisely. The pseudomedian, which is calculated if you specify METHOD=PMEDIAN in the IMPUTE statement, is an estimation of the median. The computation of the median requires sorting the entire data. However, in a distributed computing environment, each grid node contains only a part of the entire data. Sorting all the data in such an environment requires a lot of internode communications, degrading the performance dramatically. To address this challenge, a binning-based method is used to estimate the pseudomedian.
For variable x, assume that the data set is {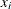 }, where
}, where 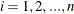 . Let
. Let 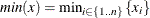 , and let
, and let 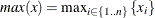 . The range of the variable is
. The range of the variable is 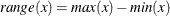 .
.
A simple bucket binning method is used to obtain the basic information. Let N be the number of buckets, ranging from 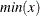 to
to 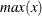 . For each bucket
. For each bucket 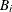 ,
, 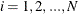 , PROC HPIMPUTE keeps following information:
, PROC HPIMPUTE keeps following information:
-
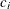 : count of x in
: count of x in
-
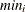 : minimum value of x in
: minimum value of x in
-
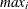 : maximum value of x in
: maximum value of x in
For each bucket , the range 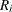 is
is
![\[ R_ i= \begin{cases} \lbrack min(x)+(i-1)*d, min(x)+i*d) & \text { if } i<N \\ \lbrack min(x)+(i-1)*d, max(x)\rbrack & \text { if } i=N \end{cases} \]](images/prochp_hpimpute0014.png)
where 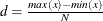
To calculate the pseudomedian, PROC HPIMPUTE finds the smallest I, such that 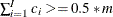 , where m is the number of nonmissing observations of x in the data set. Therefore, the pseudomedian value Q is
, where m is the number of nonmissing observations of x in the data set. Therefore, the pseudomedian value Q is
![\[ Q= \begin{cases} min_{I} & \text { if } \sum _{i=1}^{I}{c_ i} > 0.5*m \\ max_{I} & \text { if } \sum _{i=1}^{I}{c_ i} = 0.5*m \end{cases} \]](images/prochp_hpimpute0017.png)
N is set to 10,000 in PROC HPIMPUTE. Experiments show that the pseudomedian is a good estimate of the median and that the performance is satisfactory.