| The NLP Procedure |
| Introductory Examples |
The following introductory examples illustrate how to get started using the NLP procedure.
An Unconstrained Problem
Consider the simple example of minimizing the Rosenbrock function (Rosenbrock 1960):
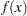 |
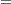 |
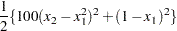 |
|||
 |
|
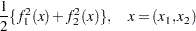 |
The minimum function value is 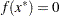 at
at 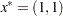 . This problem does not have any constraints.
. This problem does not have any constraints.
The following statements can be used to solve this problem:
proc nlp; min f; decvar x1 x2; f1 = 10 * (x2 - x1 * x1); f2 = 1 - x1; f = .5 * (f1 * f1 + f2 * f2); run;
The MIN statement identifies the symbol f that characterizes the objective function in terms of f1 and f2, and the DECVAR statement names the decision variables x1 and x2. Because there is no explicit optimizing algorithm option specified (TECH=), PROC NLP uses the Newton-Raphson method with ridging, the default algorithm when there are no constraints.
A better way to solve this problem is to take advantage of the fact that 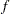 is a sum of squares of
is a sum of squares of 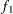 and
and 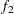 and to treat it as a least squares problem. Using the LSQ statement instead of the MIN statement tells the procedure that this is a least squares problem, which results in the use of one of the specialized algorithms for solving least squares problems (for example, Levenberg-Marquardt).
and to treat it as a least squares problem. Using the LSQ statement instead of the MIN statement tells the procedure that this is a least squares problem, which results in the use of one of the specialized algorithms for solving least squares problems (for example, Levenberg-Marquardt).
proc nlp; lsq f1 f2; decvar x1 x2; f1 = 10 * (x2 - x1 * x1); f2 = 1 - x1; run;
The LSQ statement results in the minimization of a function that is the sum of squares of functions that appear in the LSQ statement. The least squares specification is preferred because it enables the procedure to exploit the structure in the problem for numerical stability and performance.
PROC NLP displays the iteration history and the solution to this least squares problem as shown in Figure 6.1. It shows that the solution has 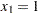 and
and 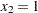 . As expected in an unconstrained problem, the gradient at the solution is very close to
. As expected in an unconstrained problem, the gradient at the solution is very close to 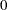 .
.
| Parameter Estimates | 2 |
|---|---|
| Functions (Observations) | 2 |
| Optimization Start | |||
|---|---|---|---|
| Active Constraints | 0 | Objective Function | 7.7115046337 |
| Max Abs Gradient Element | 38.778863865 | Radius | 450.91265904 |
| Iteration | Restarts | Function Calls |
Active Constraints |
Objective Function |
Objective Function Change |
Max Abs Gradient Element |
Lambda | Ratio Between Actual and Predicted Change |
||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 2 | 0 | 7.41150 | 0.3000 | 77.0013 | 0 | 0.0389 | ||
| 2 | 0 | 3 | 0 | 1.9337E-28 | 7.4115 | 6.39E-14 | 0 | 1.000 |
| Optimization Results | |||
|---|---|---|---|
| Iterations | 2 | Function Calls | 4 |
| Jacobian Calls | 3 | Active Constraints | 0 |
| Objective Function | 1.933695E-28 | Max Abs Gradient Element | 6.394885E-14 |
| Lambda | 0 | Actual Over Pred Change | 1 |
| Radius | 7.7001288198 | ||
Boundary Constraints on the Decision Variables
Bounds on the decision variables can be used. Suppose, for example, that it is necessary to constrain the decision variables in the previous example to be less than 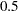 . That can be done by adding a BOUNDS statement.
. That can be done by adding a BOUNDS statement.
proc nlp; lsq f1 f2; decvar x1 x2; bounds x1-x2 <= .5; f1 = 10 * (x2 - x1 * x1); f2 = 1 - x1; run;
The solution in Figure 6.2 shows that the decision variables meet the constraint bounds.
| Optimization Results | ||||
|---|---|---|---|---|
| Parameter Estimates | ||||
| N | Parameter | Estimate | Gradient Objective Function |
Active Bound Constraint |
| 1 | x1 | 0.500000 | -0.500000 | Upper BC |
| 2 | x2 | 0.250000 | 0 | |
Linear Constraints on the Decision Variables
More general linear equality or inequality constraints of the form
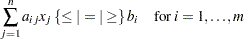 |
can be specified in a LINCON statement. For example, suppose that in addition to the bounds constraints on the decision variables it is necessary to guarantee that the sum 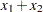 is less than or equal to
is less than or equal to 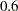 . That can be achieved by adding a LINCON statement:
. That can be achieved by adding a LINCON statement:
proc nlp; lsq f1 f2; decvar x1 x2; bounds x1-x2 <= .5; lincon x1 + x2 <= .6; f1 = 10 * (x2 - x1 * x1); f2 = 1 - x1; run;
The output in Figure 6.3 displays the iteration history and the convergence criterion.
| Parameter Estimates | 2 |
|---|---|
| Functions (Observations) | 2 |
| Lower Bounds | 0 |
| Upper Bounds | 2 |
| Linear Constraints | 1 |
| Iteration | Restarts | Function Calls |
Active Constraints |
Objective Function |
Objective Function Change |
Max Abs Gradient Element |
Lambda | Ratio Between Actual and Predicted Change |
||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 2 | 0 | ' | 0.23358 | 3.6205 | 3.3399 | 0 | 0.939 | |
| 2 | 1 | 6 | 0 | ' | 0.16687 | 0.0667 | 0.4865 | 174.8 | 0.535 | |
| 3 | 2 | 8 | 1 | 0.16679 | 0.000084 | 0.2677 | 0.00430 | 0.0008 | ||
| 4 | 2 | 9 | 1 | 0.16658 | 0.000209 | 0.000650 | 0 | 0.998 | ||
| 5 | 2 | 10 | 1 | 0.16658 | 1.233E-9 | 1.185E-6 | 0 | 0.998 |
| Optimization Results | |||
|---|---|---|---|
| Iterations | 5 | Function Calls | 11 |
| Jacobian Calls | 7 | Active Constraints | 1 |
| Objective Function | 0.1665792899 | Max Abs Gradient Element | 1.1847291E-6 |
| Lambda | 0 | Actual Over Pred Change | 0.9981768536 |
| Radius | 0.0000994255 | ||
Figure 6.4 shows that the solution satisfies the linear constraint. Note that the procedure displays the active constraints (the constraints that are tight) at optimality.
| Optimization Results | |||
|---|---|---|---|
| Parameter Estimates | |||
| N | Parameter | Estimate | Gradient Objective Function |
| 1 | x1 | 0.423645 | -0.312000 |
| 2 | x2 | 0.176355 | -0.312000 |
Nonlinear Constraints on the Decision Variables
More general nonlinear equality or inequality constraints can be specified using an NLINCON statement. Consider the least squares problem with the additional constraint
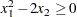 |
This constraint is specified by a new function c1 constrained to be greater than or equal to 0 in the NLINCON statement. The function c1 is defined in the programming statements.
proc nlp tech=QUANEW; min f; decvar x1 x2; bounds x1-x2 <= .5; lincon x1 + x2 <= .6; nlincon c1 >= 0; c1 = x1 * x1 - 2 * x2; f1 = 10 * (x2 - x1 * x1); f2 = 1 - x1; f = .5 * (f1 * f1 + f2 * f2); run;
Figure 6.5 shows the iteration history, and Figure 6.6 shows the solution to this problem.
| Parameter Estimates | 2 |
|---|---|
| Lower Bounds | 0 |
| Upper Bounds | 2 |
| Linear Constraints | 1 |
| Nonlinear Constraints | 1 |
| Optimization Start | |||
|---|---|---|---|
| Objective Function | 3.6940664349 | Maximum Constraint Violation | 0 |
| Maximum Gradient of the Lagran Func | 24.167449944 | ||
| Iteration | Restarts | Function Calls |
Objective Function |
Maximum Constraint Violation |
Predicted Function Reduction |
Step Size |
Maximum Gradient Element of the Lagrange Function |
|
|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 9 | 1.33999 | 0 | 1.1315 | 0.558 | 7.172 | |
| 2 | 0 | 10 | 0.81134 | 0 | 0.2944 | 1.000 | 2.896 | |
| 3 | 0 | 11 | 0.61022 | 0 | 0.1518 | 1.000 | 2.531 | |
| 4 | 0 | 12 | 0.49146 | 0 | 0.1575 | 1.000 | 1.736 | |
| 5 | 0 | 13 | 0.37940 | 0 | 0.0957 | 1.000 | 0.464 | |
| 6 | 0 | 14 | 0.34677 | 0 | 0.0367 | 1.000 | 0.603 | |
| 7 | 0 | 15 | 0.33136 | 0 | 0.00254 | 1.000 | 0.257 | |
| 8 | 0 | 16 | 0.33020 | 0 | 0.000332 | 1.000 | 0.0218 | |
| 9 | 0 | 17 | 0.33003 | 0 | 3.92E-6 | 1.000 | 0.00200 | |
| 10 | 0 | 18 | 0.33003 | 0 | 2.053E-8 | 1.000 | 0.00002 |
| Optimization Results | |||
|---|---|---|---|
| Iterations | 10 | Function Calls | 19 |
| Gradient Calls | 13 | Active Constraints | 1 |
| Objective Function | 0.3300307258 | Maximum Constraint Violation | 0 |
| Maximum Projected Gradient | 9.4437885E-6 | Value Lagrange Function | 0.3300307155 |
| Maximum Gradient of the Lagran Func | 9.1683548E-6 | Slope of Search Direction | -2.053448E-8 |
| Note: | At least one element of the (projected) gradient is greater than 1e-3. |
| Optimization Results | ||||
|---|---|---|---|---|
| Parameter Estimates | ||||
| N | Parameter | Estimate | Gradient Objective Function |
Gradient Lagrange Function |
| 1 | x1 | 0.246960 | 0.753147 | 0.753147 |
| 2 | x2 | 0.030495 | -3.049459 | -3.049459 |
| Linear Constraints Evaluated at Solution | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.32255 | = | 0.6000 | - | 1.0000 | * | x1 | - | 1.0000 | * | x2 | |
| Values of Nonlinear Constraints | ||||||||
|---|---|---|---|---|---|---|---|---|
| Constraint | Value | Residual | Lagrange Multiplier |
|||||
| [ | 2 | ] | c1_G | 2.112E-8 | 2.112E-8 | . | ||
Not all of the optimization methods support nonlinear constraints. In particular the Levenberg-Marquardt method, the default for LSQ, does not support nonlinear constraints. (For more information about the particular algorithms, see the section Optimization Algorithms.) The Quasi-Newton method is the prime choice for solving nonlinear programs with nonlinear constraints. The option TECH=QUANEW in the PROC NLP statement causes the Quasi-Newton method to be used.
A Simple Maximum Likelihood Example
The following is a very simple example of a maximum likelihood estimation problem with the log likelihood function:
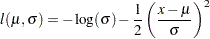 |
The maximum likelihood estimates of the parameters 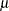 and
and  form the solution to
form the solution to
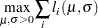 |
where
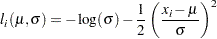 |
In the following DATA step, values for  are input into SAS data set X; this data set provides the values of
are input into SAS data set X; this data set provides the values of 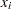 .
.
data x; input x @@; datalines; 1 3 4 5 7 ;
In the following statements, the DATA=X specification drives the building of the objective function. When each observation in the DATA=X data set is read, a new term 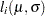 using the value of is added to the objective function LOGLIK specified in the MAX statement.
using the value of is added to the objective function LOGLIK specified in the MAX statement.
proc nlp data=x vardef=n covariance=h pcov phes; profile mean sigma / alpha=.5 .1 .05 .01; max loglik; parms mean=0, sigma=1; bounds sigma > 1e-12; loglik=-0.5*((x-mean)/sigma)**2-log(sigma); run;
After a few iterations of the default Newton-Raphson optimization algorithm, PROC NLP produces the results shown in Figure 6.7.
| Optimization Results | ||||||
|---|---|---|---|---|---|---|
| Parameter Estimates | ||||||
| N | Parameter | Estimate | Approx Std Err |
t Value | Approx Pr > |t| |
Gradient Objective Function |
| 1 | mean | 4.000000 | 0.894427 | 4.472136 | 0.006566 | -1.33149E-10 |
| 2 | sigma | 2.000000 | 0.632456 | 3.162278 | 0.025031 | 5.6064146E-9 |
In unconstrained maximization, the gradient (that is, the vector of first derivatives) at the solution must be very close to zero and the Hessian matrix at the solution (that is, the matrix of second derivatives) must have nonpositive eigenvalues. The Hessian matrix is displayed in Figure 6.8.
| Hessian Matrix | ||
|---|---|---|
| mean | sigma | |
| mean | -1.250000003 | 1.33149E-10 |
| sigma | 1.33149E-10 | -2.500000014 |
Under reasonable assumptions, the approximate standard errors of the estimates are the square roots of the diagonal elements of the covariance matrix of the parameter estimates, which (because of the COV=H specification) is the same as the inverse of the Hessian matrix. The covariance matrix is shown in Figure 6.9.
| Covariance Matrix 2: H = (NOBS/d) inv(G) |
||
|---|---|---|
| mean | sigma | |
| mean | 0.7999999982 | 4.260769E-11 |
| sigma | 4.260769E-11 | 0.3999999978 |
The PROFILE statement computes the values of the profile likelihood confidence limits on SIGMA and MEAN, as shown in Figure 6.10.
| Wald and PL Confidence Limits | |||||||
|---|---|---|---|---|---|---|---|
| N | Parameter | Estimate | Alpha | Profile Likelihood Confidence Limits |
Wald Confidence Limits | ||
| 1 | mean | 4.000000 | 0.500000 | 3.384431 | 4.615569 | 3.396718 | 4.603282 |
| 1 | mean | . | 0.100000 | 2.305716 | 5.694284 | 2.528798 | 5.471202 |
| 1 | mean | . | 0.050000 | 1.849538 | 6.150462 | 2.246955 | 5.753045 |
| 1 | mean | . | 0.010000 | 0.670351 | 7.329649 | 1.696108 | 6.303892 |
| 2 | sigma | 2.000000 | 0.500000 | 1.638972 | 2.516078 | 1.573415 | 2.426585 |
| 2 | sigma | . | 0.100000 | 1.283506 | 3.748633 | 0.959703 | 3.040297 |
| 2 | sigma | . | 0.050000 | 1.195936 | 4.358321 | 0.760410 | 3.239590 |
| 2 | sigma | . | 0.010000 | 1.052584 | 6.064107 | 0.370903 | 3.629097 |
Copyright © SAS Institute, Inc. All Rights Reserved.