| The OPTMODEL Procedure |
READ DATA Statement
- READ DATA SAS-data-set [ NOMISS ] INTO [ [set-name =] [ read-key-column(s) ] ] [ read-column(s) ] ;
The READ DATA statement reads data from a SAS data set into PROC OPTMODEL parameter and variable locations. The arguments to the READ DATA statement are as follows:
- SAS-data-set
-
specifies the input data set name and options.
- set-name
-
specifies a set parameter in which to save the set of observation key
values read from the input data set.
- read-key-column(s)
-
provide the index values for array destinations.
- read-column(s)
- specify the data values to read and the destination locations.
The following example uses the READ DATA statement to copy data set variables j and k from the SAS data set indata into parameters of the same name. The READ= data set option is used to specify a password.
proc optmodel;
number j, k;
read data indata(read=secret) into j k;
Key Columns
If any read-key-column(s) are specified, then the READ DATA statement reads all observations from the input data set. If no read-key-column(s) are specified, then only the first observation of the data set is read. The data set is closed after reading the requested information.Each read-key-column declares a local dummy parameter and specifies a data set variable that supplies the column value. The values of the specified data set variables from each observation are combined into a key tuple. This combination is known as the observation key. The observation key is used to index array locations specified by the read-column(s) items. The observation key is expected to be unique for each observation read from the data set.
The syntax for a read-key-column(s) is as follows:
- name [ = source-name ] [ /trim-option ]
A read-key-column creates a local dummy parameter named name that holds an element of the observation key tuple. The dummy parameter can be used in subsequent read-column(s) items to reference the element value. If a source-name is given, then it specifies the data set variable that supplies the value. Otherwise the source data set variable has the same name as the dummy parameter, name . Use the special data set variable name _N_ to refer to the number identification of the observations.
You can specify a set-name to save the set of observation keys into a set parameter. If the observation key consists of a single scalar value, then the set member type must match the scalar type. Otherwise the set member type must be a tuple with element types that match the corresponding observation key element types.
The READ DATA statement initially assigns an empty set to the target set-name parameter. As observations are read, a tuple for each observation key is added to the set. A set used to index an array destination in the read-column(s) can be read at the same time as the array values. Consider a data set, invdata, created by the following code:
data invdata;
input item $ invcount;
datalines;
table 100
sofa 250
chair 80
;
The following code reads the data set invdata, which has two variables, item and invcount. The READ DATA statement constructs a set of inventory items, Items. At the same time, the parameter location invcount[item] is assigned the value of the data set variable invcount in the corresponding observation.
proc optmodel;
set<string> Items;
number invcount{Items};
read data invdata into Items=[item] invcount;
print invcount;
The output of this code is shown in Output 6.23.
Figure 6.23: READ DATA Statement: Key Column
When observations are read, the values of data set variables are copied to parameter locations. Numeric values are copied unchanged. For character values, trim-option controls how leading and trailing blanks are processed. Trim-option is ignored when the value type is numeric. Specify any of the following keywords for trim-option:
- TRIM | TR
- removes leading and trailing blanks from the data set value. This is the default behavior.
- LTRIM | LT
- removes only leading blanks from the data set value.
- RTRIM | RT
- removes only trailing blanks from the data set value.
- NOTRIM | NT
- copies the data set value with no changes.
Columns
Read-column(s) specify data set variables to read and PROC OPTMODEL parameter locations to which to assign the values. The types of the input data set variables must match the types of the parameters. Array parameters can be implicitly or explicitly indexed by the observation key values.
Normally, missing values from the data set are assigned to the parameters that are specified in the read-column(s). The NOMISS keyword suppresses the assignment of missing values, leaving the corresponding parameter locations unchanged. Note that the parameter location does not need to have a valid index in this case. This permits a single statement to read data into multiple arrays that have different index sets.
Read-column(s) has the following forms:
- identifier-expression [ = name | COL( name-expression ) ] [ /trim-option ]
-
transfers an input data set variable to a target parameter or
variable. Identifier-expression specifies the
target. If the identifier-expression specifies an array without an
explicit index, then the observation key provides an implicit index.
The name of the input data set variable can be specified with a
name or a COL expression. Otherwise the data set variable name is
given by the name part of the identifier-expression. For COL
expressions, the string-valued name-expression is evaluated to
determine the data set variable name. Trim-option controls
removal of leading and trailing blanks in the incoming data. For example, the
following code reads the data set variables column1 and column2
from the data set exdata into the PROC OPTMODEL parameters p
and q, respectively. The observation numbers in exdata are read into
the set indx, which indexes p and q.
data exdata; input column1 column2; datalines; 1 2 3 4 ;proc optmodel; number n init 2; set<num> indx; number p{indx}, q{indx}; read data exdata into indx=[_N_] p=column1 q=col("column"||n); print p q;
The output is shown in Output 6.24.
Figure 6.24: READ DATA Statement: Identifier Expressions - { index-set } < read-column(s) >
-
performs the transfers by iterating
each column specified by <read-column(s) > for each member of the
index-set. If there are
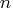 columns and
columns and 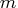 index set members, then
index set members, then 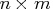 columns are generated. The dummy
parameters from the index set can be used in the columns to
generate distinct input data set variable names in the iterated
columns, using COL expressions. The columns are expanded when the
READ DATA statement is executed, before any observations are read. This
form of read-column(s) cannot be nested. In other words, the
following form of read-column(s) is NOT allowed:
columns are generated. The dummy
parameters from the index set can be used in the columns to
generate distinct input data set variable names in the iterated
columns, using COL expressions. The columns are expanded when the
READ DATA statement is executed, before any observations are read. This
form of read-column(s) cannot be nested. In other words, the
following form of read-column(s) is NOT allowed:
{ index-set } < { index-set } < read-column(s) > >
An example demonstrating the use of the iterated column read-option follows.
You can use an iterated column read-option to read multiple data set variables into the same array. For example, a data set might store an entire row of array data in a group of data set variables. The following code demonstrates how to read a data set containing demand data divided by day:
data dmnd;
input loc $ day1 day2 day3 day4 day5;
datalines;
East 1.1 2.3 1.3 3.6 4.7
West 7.0 2.1 6.1 5.8 3.2
;
proc optmodel;
set DOW = 1..5; /* days of week, 1=Monday, 5=Friday */
set<string> LOC; /* locations */
number demand{LOC, DOW};
read data dmnd
into LOC=[loc]
{d in DOW} < demand[loc, d]=col("day"||d) >;
print demand;
This reads a set of demand variables named DAY1--DAY5 from each
observation, filling in the two-dimensional array demand. The
output is shown in Output 6.25.
Figure 6.25: Demand Data
Copyright © 2008 by SAS Institute Inc., Cary, NC, USA. All rights reserved.