| The GA Procedure |
| PROC GA Statement |
invokes the GA procedure
The following options are used with the PROC GA statement.
-
DATA
 =SAS-data-set
=SAS-data-set
specifies a data set containing data required to specify the problem, where
is an integer from 1 to 5. The data set is read and variables created matching the variables of the data set. If the data set has more than one observation, then the newly created variables are vector arrays with the size equal to the number of observations. - FIRSTGEN=SAS-data-set
specifies a SAS data set containing the initial solution generation. Different segments in the solution should be identified by variable names consisting of a letter followed by numbers representing the elements in the segments, in alphabetical order. For example, if the first segment of the solution uses real encoding and contains 10 elements, it should be represented by the numeric variables A1, A2, ..., A10. A second segment with integer encoding and five elements would be specified in the variables B1, B2, ..., B5. For Boolean encoding each Boolean element is represented by one variable in the data set, and for sequence encoding each position in the sequence is represented by one variable. If the data set contains a field named OBJECTIVE, then the value of that field becomes the objective value for that solution at initialization time (overriding the value computed by the input objective function), unless the field value is a missing value. The FIRSTGEN= and LASTGEN= options are designed to work together, so that a data set generated from a run of the GA procedure with a LASTGEN= option set can be specified in the FIRSTGEN= option of a subsequent run of the GA procedure, to continue the optimization from where it finished. If the number of observations in the data set is less than the population size specified in the Initialize call, additional members are generated as specified in the Initialize call to complete the population. This feature makes it easy to seed an initial randomly generated population with chosen superior solutions generated by heuristics or a previous run of the GA procedure. If the data set contains more observations than the population size, the population is filled starting at the first observation, and the additional observations are not used.
- LASTGEN=SAS-data-set
specifies a SAS data set into which the final solution generation is written. Different segments in the solution are identified by variable names consisting of a letter followed by numbers representing the elements in the segments, in alphabetical order. For example, if the first segment of the solution uses real encoding and contains 10 elements, it would be represented by the numeric variables A1, A2, ..., A10. A second segment with integer encoding and five elements would be specified in the variables B1, B2, ..., B5. For Boolean encoding each Boolean element is represented by one variable in the data set, and for sequence encoding each position in the sequence is represented by one variable. In addition to the solutions elements, the final objective value for each solution is output in the OBJECTIVE variable. The FIRSTGEN= and LASTGEN= options are designed to work together, so that a data set generated with a LASTGEN= option can be specified in the FIRSTGEN= option of a later run of the GA procedure.
- LIBRARY=library-list
specifies a library or group of libraries for the procedure to search to resolve subroutine or function calls. The libraries can be created by using PROC FCMP and PROC PROTO. This option supplements the action of the CMPLIB= SAS option, but it permits you to designate libraries specific to this procedure invocation. Use the libref.catalog format to specify the two-level name of the library; library-list can be either a single library, a range of library names, or a list of libraries. The following examples demonstrate the use of the LIBRARY= option.
proc ga library = sasuser.xlib; proc ga library = xlib1-xlib5; proc ga library = (sasuser.xlib xlib1-xlib5 work.example);
-
MATRIX=SAS-data-set
specifies a data set containing two-dimensional matrix data, where
is an integer from 1 to 5. A two-dimensional numeric array with the same name as the option is created and initialized from the data set. This option is provided to facilitate the input of tabular data to be used in setting up the optimization problem. Examples of data that might be provided by this option include a distance matrix for a traveling salesman problem or a matrix of coefficients for linear constraints. -
MAXITER=
specifies the maximum number of iterations to permit for the optimization process. A ContinueFor call overrides a limit set by this option.
-
NOVALIDATE=
controls the amount of solution validity checking performed by the procedure. By default, the procedure verifies that valid solutions are being supplied at initialization and when the solution population is being updated by genetic operators or other user actions. If a solution segment has elements that exceed bounds set by a SetBounds call, those elements will be reset to the bound and a warning will be issued. If a solution segment contains other illegal values, an error will be signaled. This action is useful for maintaining the validity of the optimization and avoiding some errors that are often difficult to trace. However, this activity does consume CPU time, and you might want to use a strategy where you generate infeasible solutions at initialization or via genetic operators and then repair the solutions later in an update or objective routine. The NOVALIDATE= option enables you to do so, by turning off the validation checks. If
is 1, validation is turned off for initialization only, and if is 2, validation is turned off for update only. If is 3, all solution validity checking is turned off. -
NOVALIDATEWARNING=
controls the output of warning messages related to solution validation checking. Depending on the value of the NOVALIDATE option, warning messages will be issued when the procedure repairs initial or updated solution segments to fit within bounds set with the SetBounds call. If
is 1, validation warnings are turned off for initialization only; and if is 2, validation warnings are turned off for update only. If is 3, all solution validation warnings are turned off. -
SEED=
specifies an initial seed to begin random number generation. This option is provided for reproducibility of results. If it is not specified, or if it is set to 0, a seed is chosen based on the system clock. The SEED value should be a nonnegative integer less than
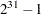 .
.
Copyright © SAS Institute, Inc. All Rights Reserved.