Creating Aggregation Tables with the Summarized Aggregation Table Wizard
To create an aggregation table (that is, the target
table) with the Summarized Aggregation Table wizard, respond to the
wizard's prompts.
How to Specify Library Information
If this aggregation
table is the first target table that is specified for this Aggregation
transformation, an additional page of the wizard opens. This page
prompts you for the physical target location and for information about
the SAS library where the data will be stored. When this page opens,
the following fields are already specified with default values. If
you want to modify these fields, perform the following steps:
How to Select a Filter
Filters can limit the
amount of data that is input to an aggregation table. To select a
filter and a column for data-duplication checking, perform the following
steps:
-
The Expression field displays the formula that defines the filter. It cannot be changed from this location. For information about how to modify the expression field of a filter, see Modify a Filter of an Aggregation Transformation.
Note: For more information
about how to work with filters, see Working with Aggregation Transformation Filters .
Specify Aging
Managing Your Data: Aging and Purging Options
SAS IT Resource Management
provides several ways of managing the amount of data that is kept
in the aggregation tables of your IT data mart. You can apply the
aging and purging functions to both simple and summarized aggregations.
The selection of the aging and purging attributes for a simple or
a summarized aggregation table can be performed on the Specify aging page of the wizard.
-
You can specify whether and how you want to age your data when you create the Aggregation transformation. Based on these specifications, data will be kept in the aggregation tables or aged out of them.By entering a value for the Age limit in days, you are specifying the age range that data will be present in the table. The minimum number of days is 1; the maximum number of days is 9999.Note: Columns that are used for aging are DATETIME columns. For these columns, one day of aging extends over 24 hours of data collection, which might extend over one or more days.You are not specifying that the data is to be aged out after that number of days. Instead, the value that you specify is the number of days of data that you want to keep. Calculate what is aged out by subtracting the value of the Age limit in days from the latest date of the new or existing data. The resulting date is the date before which data will age out. For example, in the following figure, Day 9 is the latest date of the data and the Age limit in days is seven.

How to Specify Aging Criteria
You can specify whether
and how you want to age your data when you define the aggregation
target table. Based on these specifications, data will be kept in
the aggregation table or aged out of it. To specify aging criteria
for the target table, perform the following steps:
-
To perform aging for the target table, check the corresponding check box. This action enables you to select the column to be used for aging and to specify the format of that column.
-
The Column field displays a list of the columns from the source table that are available to use for aging the data. From the drop-down list, select the column that you want to use. It is displayed in the Column field. The format of the selected field is displayed.Note: If you want to specify percent change for a variable, you must select an aging column. SAS IT Resource Management uses that aging column in order to calculate the period-to-period changes for that variable. The selected aging column is automatically added to the list of class columns for this aggregation table.
-
-
To specify the completed day, check the corresponding check box. This action enables you to select the column to use to determine whether a day is complete. (This option is enabled if aging has been specified for this aggregation table and the source table has a column called DATETIME.)This feature is useful only for tables where the aging column represents a DAY or less. For example, this feature is not useful for WEEKDATE aggregations.Note: If the Apply completed day option is deselected on an existing aggregation table that previously selected that option, the rank columns of that table are analyzed. If they depend on Completed Day being selected, a message is displayed that lists the rank columns that would be affected and the deselection of the Completed Day option is not permitted.
How to Specify Class and ID Variables
On the Specify class
and ID variables page, you can specify the columns from the source
table that are to be included in the target aggregation table as class
variables and as ID variables. After the class and ID variables have
been selected, you can modify the name, label, and the format attributes
of the output columns. These changes can be performed on the Specify
column details page of the wizard for summarized aggregations.
-
A class variable is used to group or classify data. For example, the value of a class variable could be a device address.Note: If aging is being performed on this target aggregation table, then the aging column is automatically added to the list of class columns. The aging column cannot be deleted from the list of class variables if it is in use as the aging column. If aging is turned off, the column can be removed from the list of class variables.
Note: If a variable is based on
a time period that is greater than your aging column, do not specify
it as a class column. Instead, specify it as an ID column. For example,
if your aging column is DAYDATE, do not specify WEEKDATE as another
class column. Instead specify it as an ID column.
You can select the
entire list of available columns by clicking the double right arrow.
Back arrows can be used to deselect one, several, or all columns.
After your data has
been aggregated, you can change the class list. If you remove columns
from the class list, the existing data in the summarized aggregation
table is merged again so that it matches the new class list. If you
add new columns to the class list, then these new columns in the summarized
aggregation table will have a missing value (for numeric) or blank
value (for character) in the existing data. (You cannot remove a class
or ID column if it is used as the source for a join column in another
aggregation table. Similarly, you cannot remove a class or ID column
if it is used as the source column of a rank column in this aggregation
table.)
The value that is assigned
to the ID variable is the last value that is read into the group that
is defined by the unique combination of class variables.
Note: If an input column is given
a role as a class variable, ID variable, or a statistic, it cannot
simultaneously be assigned a different role. Therefore, it will not
be available for selection. If all available variables are assigned
as class or ID variables, then no variables will be available to be
used as analysis variables. In that case, the Select analysis variables
page will not be displayed. Similarly, if no analysis variables are
selected, the Specify statistics page will not be displayed.
How to Specify Column Details
How to Specify Analysis Variables
On the Select analysis
variables page, you can select analysis variables that can be used
to calculate statistics. If no analysis variables are selected, no
statistics can be specified for this aggregation and the Specify statistics page of the wizard is not displayed.
Note: If you do not want to specify
statistics, ranking, percent change, join columns, or a computed column
for this aggregation table, click Finish,
which updates the Aggregation transformation with this new aggregation
table and returns you to the process flow diagram. For information, see Completing the Specification of the Summarized Aggregation Table.
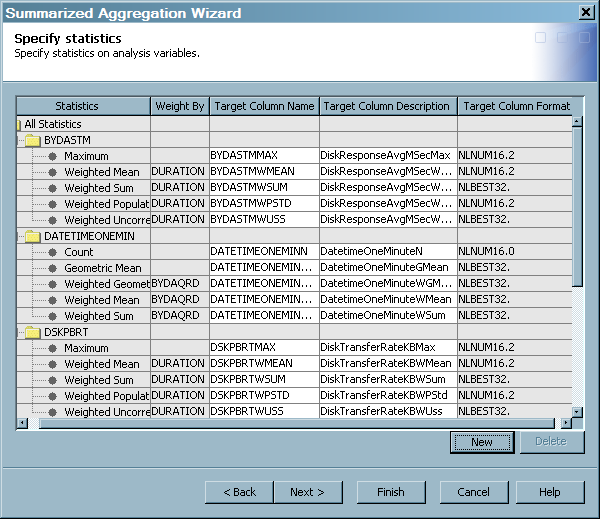
Specify Statistics
About Specifying Statistics
On the Specify statistics
page, you can calculate or delete one or more statistics on analysis
variables that you selected on the previous page. These variables
are displayed in a grid format, which contains a row for each analysis
variable. The grid contains the following columns: Statistics, Weight By, Target Column Name, Target Column Description, and Target Column Format. Except for the Statistics column, which displays the names of the selected analysis variables,
the columns of the grid are blank until the statistic is specified.
Note: For the list of statistics
that SAS IT Resource Management enables you to create, see Statistics.
Note: If you do not want to specify
statistics, percent change columns, rank columns, join columns, or
a computed column for this aggregation table, click Finish, which updates the Aggregation transformation with this new aggregation
target table and returns you to the process flow diagram. For information, see Completing the Specification of the Summarized Aggregation Table.
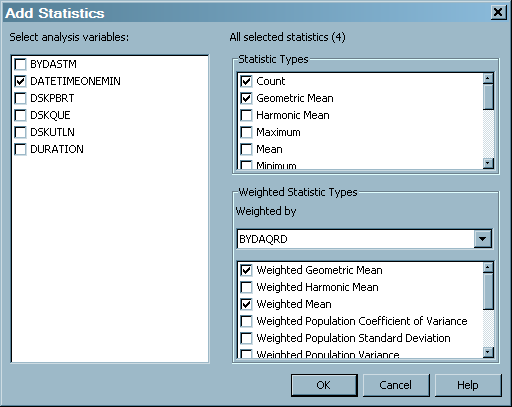
How to Create Statistics for an Analysis Variable
-
In the Select analysis variables panel, check the box next to the analysis variable for which you want to specify statistics. (Checking multiple analysis variables enables you to specify the same statistics for all the analysis variables that you selected. Otherwise, check an analysis variable and specify the statistics for it individually.)
-
Click OK to add the requested and any underlying statistics to the grid under the analysis variable. The row displays these statistics along with its attributes, such as Weight By, Target Column Name, Target Column Description, and Target Column Format. These fields contain the default values that are associated with the statistics. To modify a field on this grid, highlight it, and change it as needed by typing the revision in the field.
How to Delete a Statistic
To delete a statistic
from the list of statistics that will be created for an analysis variable,
perform the following steps:
-
Click Delete. If the statistic that you want to delete is used to generate another statistical column, a warning message is displayed that lists the statistical columns where the statistic is needed. You must first delete those statistical columns before you can delete this statistic. (You cannot remove a statistic column if it is used for a rank column, percent change column, or join column.)
Note: Deleting a statistic that
depends on another statistic does not delete any underlying statistic.
Note: If you do not want to specify
percent change, ranking, join columns, or a computed column for this
aggregation table, click Finish, which updates
the Aggregation transformation with this new aggregation table and
returns you to the process flow diagram. For information, see Completing the Specification of the Summarized Aggregation Table.
Deleting Multiple Statistic, Percent Change, Rank, and Join Columns
In some instances, you
might want to delete multiple columns at the same time. For example,
you might want to delete all of the statistics for a particular analysis
variable, or only some of the statistics. You can delete all of the
statistics for a particular analysis variable by either selecting
all the statistics individually, or by selecting the analysis variable
itself. Either action will accomplish the same purpose.
However, if your selection
of columns to delete includes an analysis variable and some, but not
all, of the statistics for that analysis variable, a message is displayed.
The message states that you selected conflicting choices and, therefore,
no columns will be deleted. The message advises you to select either
an analysis variable or one or more statistics.
Specify Percent Change
About Specifying Percent Change
Percent change information
is displayed in a grid format, which contains a row for each statistic
that is being calculated. The grid contains the following columns: Statistics, Weight By, Statistic Column Name, Target Column Name, Target Column Description, and Target Column Format. Except for the statistic that
is being calculated, all cells of the grid are initially blank.
On the Specify percent
change page, you can specify the percent change for statistics. If
you want to specify percent change for a variable, you must have selected
an aging column. SAS IT Resource Management uses that aging column
in order to calculate the period-to-period changes for that variable.
Note: If you do not want to specify
percent change columns, rank columns, join columns, or a computed
column for this aggregation table, click Finish, which updates the Aggregation transformation with this new aggregation
target table and returns you to the process flow diagram. For information, see Completing the Specification of the Summarized Aggregation Table.
How to Remove Percent Change Calculation for a Statistic
Specify Ranking
About Ranking
The ranking of data
determines the position of the value of a variable or a value within
a selected group of class variables. You can specify that ranks be
computed on class variables, ID variables, or statistical variables.
Only numeric variables can be ranked.
SAS IT Resource Management
computes a dense rank, which means that the rank numbers are sequentially
numbered, without gaps. The ranks start with 1 and are incremented
by 1. Ties receive the same rank. For more information about ranking,
see “The RANK Procedure” chapter in the Base SAS Procedures Guide.
Ranks are computed before
the calculation of computed columns so that ranks can be used in the
calculation of a computed column.
On the Specify ranking
page, you can specify the variables that you want to rank and how
these variables should be ranked. You can also delete a rank variable.
Rank variables are displayed in a grid format, which contains a row
for each defined rank variable. The grid contains the following columns: Rank Columns, Target Column Name, Target Column Description, Rank Order, Rank Grouping,
and Completed Days, which are all initially
blank until you add a ranking specification for a variable.
Note: Jobs that calculate rank
variables might require lengthy processing time because the data might
have to be read multiple times. For best results, minimize the number
of rank variables that you specify.
Note: If you do not want to specify
rank columns, join columns, or a computed column for this aggregation
table, click Finish, which updates the Aggregation
transformation with this new aggregation target table and returns
you to the process flow diagram. For information, see Completing the Specification of the Summarized Aggregation Table.
How to Specify Ranking for a Variable
-
Alternatively, to rank variables over specific class variables, click the corresponding option. (The list of variables with this option includes only the statistics columns that you specified on the previous page.) In the Rank over the following class variables box, check the class variables over which you want to rank selected variables.Note: You can select any class variables over which to rank the selected statistic. However, you should leave at least one class variable deselected. The class variables that are not selected are the variables over which the statistic is to be ranked. For example, you might have an aggregation table of average CPU Utilization, and the class variables are DAYDATE, DOMAIN, and MACHINE. If you request a descending rank of Average CPU Utilization using a Rank Grouping of DAYDATE and DOMAIN, then that request would result in a ranking of Average CPU utilization for all machines within the DOMAIN for the given DAYDATE. Thus, the observation where the rank value is 1 would be the machine with the highest average CPU utilization, ranked separately for each unique DOMAIN and DAYDATE combination. Alternatively, if you request a descending rank of Average CPU Utilization using a Rank Grouping of DAYDATE, DOMAIN, and MACHINE, then that request would result in a ranking of Average CPU utilization for a single row of data, which is not a useful ranking.
How to Delete a Rank Variable
For information about
deleting multiple percent change columns, see the information in the
preceding topic called "Deleting Multiple Statistic, Percent Change,
Rank, and Join Columns.”
CAUTION:
Rank columns
are often used as filters in information maps. If you remove a rank
column that is used as a filter in an information map, then the information
map, the information map job, and the report jobs that depend on that
filter might fail to run.
Note: If you do not want to specify
join columns or a computed column for this aggregation table, click Finish, which updates the Aggregation transformation
with this new aggregation target table and returns you to the process
flow diagram. For information, see Completing the Specification of the Summarized Aggregation Table.
Specify Join Columns
About Specifying Join Columns
Note: Jobs that include joined
columns might require lengthy processing time. For best results, minimize
the number of joined columns that you specify.
Information about join
columns is displayed in a grid format, which contains a row for each
column that is to be joined. The grid contains the following columns: Source Columns, Target Column Name, Target Column Description, and Target Column Format. The entries in the grid are initially
blank.
On the Specify join
columns page, you can specify columns from other aggregation tables
in this Aggregation transformation to join with columns in this target
table.
CAUTION:
If you
changed the list of class columns for an aggregation table by adding
an aging column, you might have made the join invalid.
Note: If you do not want to specify
join columns or a computed column for this aggregation table, click Finish, which updates the Aggregation transformation
with this new aggregation target table and returns you to the process
flow diagram. For information, see Completing the Specification of the Summarized Aggregation Table.
How to Specify Join Columns
-
Select columns from the list in the Available Columns. Use the arrow to transfer those columns to the Selected Columns panel and click OK. The selected columns are entered automatically into the appropriate cells of the grid, along with their corresponding default values for Target Column Name, Target Column Description, and Target Column Format.
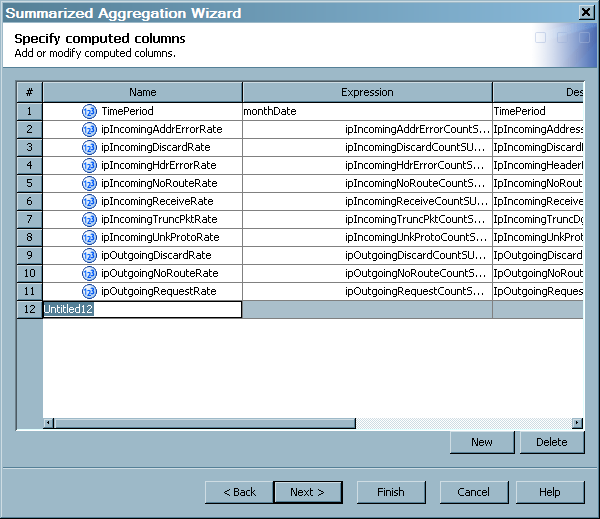
Specify Computed Columns
About Computed Columns
A computed column
stores the results of computational tasks. For example, a computed
column can be used to convert unit measurements so that all the data
uses the same standardized units of measurement. You can add, modify,
or delete computed columns on the Add or modify computed columns page
that is available in the Summarized Aggregation wizard or the Simple Aggregation wizard.
By default, a computed column is numeric.
Note: If you change a computed
column, the values for the computed column are recalculated for that
column in all rows of the data when the job is executed. (This recalculation
is performed even if no new data is added to the aggregation table.)
The Specify computed
columns page displays a grid that shows the following fields for each
computed column: Name, Expression, Description, Length, Type, Informat, and Format.
Tip
A computed column called TimePeriod is automatically added to every simple
and summarized aggregation table. Its value is always the same as
the aging column, and you can refer to TimePeriod instead of referring to the aging column directly. This technique
simplifies reporting, especially in those instances where you do not
know the name of the aging column. (If no aging is specified for the
target table, then the field is set to missing.) The expression for
this column is defined when the aggregation wizard is completed. For
example, if the aging column of an aggregation table is DAYDATE, the
expression for the TimePeriod computed column is DAYDATE and its expression
is TIMEPERIOD=DAYDATE;How to Add a Computed Column
How to Modify a Computed Column
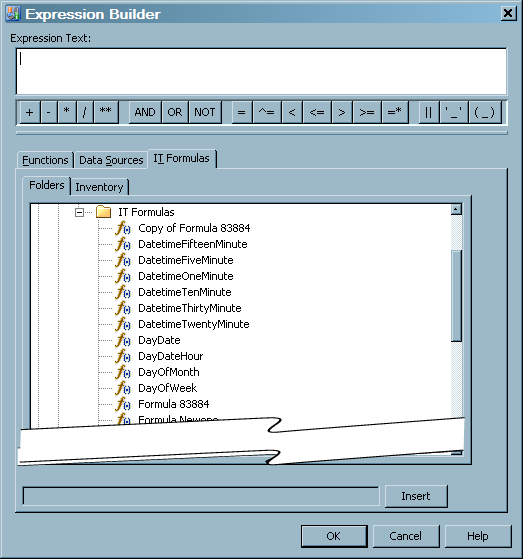
-
In the Expression field, you can specify a modified computation for this computed column by entering it in this field or by using the Expression Builder function that is provided by SAS Data Integration SAS IT Resource Management. Double-click in the field and click ... to open the Expression Builder window.Apart from the many functions that are available from the Functions and Data Sources tabs of this window, the Expression Builder window provides another tab to assist you in defining the computation for this column—the IT Formulas tab.
-
The Data Sources tab of the Expression Builder window lists all the columns that are generated in the aggregation table output. Select the column that you want to use in the expression and click Insert.For simple aggregations, the Data Source tab displays all the output columns that you selected for the simple aggregation table. For the summarized aggregation table, the Data Source tab displays all the class, ID, statistic, percent change, rank, and join columns that you selected for the summarized aggregation table. In addition, it displays the system-generated LastUpdated, CompletedDay, and ContribCount variables.All variable names that are used in the computation are the output column names. For example, if you choose to use an input column named SYSTEM as a class variable, you might rename it MACHINE. Then, if you want to use that column when defining a computed column, you should refer to that column as MACHINE, not SYSTEM.
In addition to the conventional rValue expression (where the expression consists of code that is appropriate only for the right-hand side of an assignment statement), SAS IT Resource Management also supports more complex expressions. For example, your expression can use SAS code that might include loops, IF statements, and so on. This code must be written in valid SAS DATA step syntax.When you are satisfied with the expression that you defined, click OK in the Expression Builder window to close that window and place the expression in the appropriate field of the computed column. -
In the Type field, you can change the type of the computed column. Double-click in the field and use the arrow to display the drop-down list of valid types (either character or numeric) from which you can select the type for this computed column. Fields that are the result of a calculation should be specified as numeric. By default, the computed column is numeric.
-
In the Length field, you can change the length of the computed column. For numeric type columns (not character type columns), this numeric value must be from 2 through 8. (Reducing the length of a numeric computed column might introduce precision errors.) For character computed columns, the length can be from 1 through 32767.
How to Delete a Computed Column
Deleting a computed
column removes it from the metadata for a table. The column will no
longer be generated when the Aggregation transformation job is run.
However, deleting a computed column does not remove the column from
the physical tables of aggregated data that have already been generated.
When you have finished
working with your computed columns, click Next to continue to the final page of the wizard.
Note: After the job is redeployed
and executed, changes to the computed columns will be reflected in
the physical table. For information about redeploying jobs, see Redeploy All Jobs on the Server.
Completing the Specification of the Summarized Aggregation Table
The final page of the
wizard displays the details for the summarized aggregation table that
you specified. If you are satisfied with your choices, click Finish. Click OK to return
to the process flow diagram.
Aggregation tables are
stored in sorted order, with an asserted
BY-processing can be performed using the class list,
if the BY list matches the same SORTEDBY assertion. With SAS IT Resource
Management, you can leverage SAS Data Integration Studio to define
additional indexes for use where BY-processing is required. If you
require a sorted aggregation table, you can input that table to a
SORT transformation and store the resulting table wherever you want.
SORTEDBY= data set option. The SORTEDBY assertion reflects that the data is
stored in the following order:
-
aging column
-
alphabetical list of the remaining class columns
For information about
indexes, see Indexing an Aggregation Table.