Sparse Matrix Algorithms
Iterative Methods
Subsections:
The conjugate gradient algorithm can be interpreted as the following optimization problem: minimize 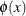 defined by
defined by
![\[ \phi (x) = 1/2 x^ T Ax - x^ T b \]](images/imlug_sma0007.png)
where 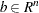 and
and 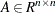 are symmetric and positive definite.
are symmetric and positive definite.
At each iteration is minimized along an A-conjugate direction, constructing orthogonal residuals:
![\[ r_ i \; \bot \; {\mathcal K}_ i(A;\, r_0),\quad r_ i = A x_ i - b \]](images/imlug_sma0010.png)
where 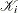 is a Krylov subspace:
is a Krylov subspace:
![\[ {\mathcal K}_ i\, (A; r) = \mbox{span} \{ r,\, Ar,\, A^2r,\, \ldots ,\, A^{i - 1}r\} \]](images/imlug_sma0012.png)
Minimum residual algorithms work by minimizing the Euclidean norm 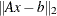 over . At each iteration,
over . At each iteration, 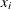 is the vector in that gives the smallest residual.
is the vector in that gives the smallest residual.
The biconjugate gradient algorithm belongs to a more general class of Petrov-Galerkin methods, where orthogonality is enforced
in a different i-dimensional subspace ( remains in ):
![\[ r_ i \; \bot \; \{ w,\, A^ T w,\, (A^ T)^{2} w,\, \ldots ,\, (A^ T)^{\, i - 1} w\} \]](images/imlug_sma0015.png)