- Vectors of Parameters
- Bernoulli Distribution
- Beta Distribution
- Binomial Distribution
- Cauchy Distribution
- Chi-Square Distribution
- Erlang Distribution
- Exponential Distribution
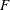 Distribution (
Distribution (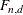 )
)- Gamma Distribution
- Geometric Distribution
- Hypergeometric Distribution
- Laplace Distribution
- Logistic Distribution
- Lognormal Distribution
- Negative Binomial Distribution
- Normal Distribution
- Normal Mixture Distribution
- Pareto Distribution
- Poisson Distribution
- t Distribution
- Table Distribution
- Triangle Distribution
- Tweedie Distribution
- Uniform Distribution
- Wald (Inverse Gaussian) Distribution
- Weibull Distribution
- Summary of Distributions
The RANDGEN subroutine generates random numbers from a specified distribution.
The input arguments to the RANDGEN subroutine are as follows:
- result
-
is a matrix that is to be filled with random samples from the specified distribution.
- distname
-
is the name of the distribution.
- parm1
-
is a distribution parameter.
- parm2
-
is a distribution parameter.
- parm3
-
is a distribution parameter.
The RANDGEN subroutine generates random numbers by using the same numerical method as the RAND function in Base SAS software, with the efficiency optimized for matrices. You can initialize the random number stream that is used by RANDGEN by calling the RANDSEED subroutine. The result parameter should be preallocated to a size equal to the number of values that you want to generate. If result is not initialized, then it receives a single random value.
The following statements fill a vector with 1,000 random values from a standard normal distribution:
call randseed(12345); x = j(1000,1); /* allocate (1000 x 1) vector */ call randgen(x, "Normal"); /* fill it */
Except for the “Table” and “NormalMix” distributions, the distribution parameters are usually scalar values. However, the RANDGEN subroutine also accepts vectors
of parameters. If result is an ![]() matrix, then parm1, parm2, and parm3 can contain 1,
matrix, then parm1, parm2, and parm3 can contain 1, ![]() ,
, ![]() , or
, or ![]() elements. The different sizes are interpreted as follows:
elements. The different sizes are interpreted as follows:
-
If the parameters are scalar quantities, each element of result is a sample value from the same distribution.
-
Otherwise, if the parameters contain
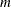 elements, the
elements, the 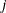 th column of the result matrix consists of random values drawn from the distribution with parameters param1[j], param2[j], and param3[j].
th column of the result matrix consists of random values drawn from the distribution with parameters param1[j], param2[j], and param3[j].
-
Otherwise, if the parameters contain
 elements, the
elements, the 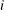 th row of the result matrix consists of random values drawn from the distribution with parameters param1[i], param2[i], and param3[i].
th row of the result matrix consists of random values drawn from the distribution with parameters param1[i], param2[i], and param3[i].
-
Otherwise, if the parameters contain
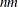 elements, the
elements, the 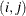 th element of the result matrix contains a random value drawn from the distribution with parameters param1[s], param2[s], and param3[s], where
th element of the result matrix contains a random value drawn from the distribution with parameters param1[s], param2[s], and param3[s], where 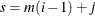 .
.
All parameters must be the same length. You cannot specify a scalar for one parameter and a vector for another. If you pass in parameter vectors that do not satisfy one of the above conditions, then the first element of each parameter is used.
As an example, the ![]() th column of the following matrix is a sample drawn from a normal population with mean
th column of the following matrix is a sample drawn from a normal population with mean ![]() and standard deviation
and standard deviation ![]() :
:
n = 5; m = 4; x = j(n,m); Mu = 1:m; Sigma = (1:m)/m; call randgen(x, "Normal", Mu, Sigma); print x;
Figure 24.298: Columns Drawn from Different Distributions
| x | |||
|---|---|---|---|
| 0.7953097 | 2.109807 | 2.5903507 | 4.567692 |
| 1.1153841 | 1.9143935 | 3.5193908 | 4.461049 |
| 1.1036757 | 2.6768648 | 3.3873821 | 4.5642427 |
| 1.1543757 | 1.6322845 | 2.6431948 | 4.2777107 |
| 0.8030879 | 1.4097247 | 3.0206292 | 2.6724841 |
The following sections describe the distributions that are supported.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
![\[ f(x) = \left\{ \begin{array}{ll} 1 & \mbox{for $p=0,x=0$}\\ p^ x(1-p)^{1-x} & \mbox{for $0<p<1,x=0,1$}\\ 1 & \mbox{for $p=1,x=1$} \end{array} \right. \]](images/imlug_langref1128.png)
The possible values of ![]() are
are ![]() . The parameter
. The parameter ![]() ,
, ![]() , is the probability of a “success.” A success means that
, is the probability of a “success.” A success means that ![]() has the value 1.
has the value 1.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() , and
, and ![]() and
and ![]() are required shape parameters with values
are required shape parameters with values ![]() and
and ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
![\[ f(x) = \left\{ \begin{array}{ll} 1 & \mbox{for $p=0,x=0$}\\ {n \choose x}p^ x(1-p)^{n-x} & \mbox{for $0<p<1,x=0,\ldots ,n$}\\ 1 & \mbox{for $p=1,x=1$} \end{array} \right. \]](images/imlug_langref1135.png)
The range of ![]() is
is ![]() . The parameter
. The parameter ![]() is the success probability, with range
is the success probability, with range ![]() . The parameter
. The parameter ![]() specifies the number of independent trials,
specifies the number of independent trials, ![]() .
.
Intuitively, ![]() is the number of successes in
is the number of successes in ![]() Bernoulli trials with probability
Bernoulli trials with probability ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The parameter
. The parameter ![]() represents degrees of freedom, with
represents degrees of freedom, with ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The Erlang distribution is a gamma distribution with an integer value for the shape parameter, ![]() .
.
The range of ![]() is
is ![]() . The parameter
. The parameter ![]() is an integer shape parameter,
is an integer shape parameter, ![]() . The optional shape parameter
. The optional shape parameter ![]() has the default value
has the default value ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The optional shape parameter
. The optional shape parameter ![]() has the default value
has the default value ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The two parameters
. The two parameters ![]() and
and ![]() are degrees of freedom, with values
are degrees of freedom, with values ![]() and
and ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The parameter
. The parameter ![]() is a shape parameter,
is a shape parameter, ![]() . The optional shape parameter
. The optional shape parameter ![]() has the default value
has the default value ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The parameter
. The parameter ![]() is the success probability, with range
is the success probability, with range ![]() .
.
Intuitively, ![]() is the number of Bernoulli trials (with probability
is the number of Bernoulli trials (with probability ![]() ) until the first success occurs.
) until the first success occurs.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() , where
, where ![]() and
and ![]() . The parameter
. The parameter ![]() is the population size, with range
is the population size, with range ![]() . The parameter
. The parameter ![]() is the size of the category of interest, with range
is the size of the category of interest, with range ![]() . The parameter
. The parameter ![]() is the sample size, with range
is the sample size, with range ![]() .
.
Intuitively, ![]() is obtained by the following experiment. Put
is obtained by the following experiment. Put ![]() red balls and
red balls and ![]() black balls into an urn. The value
black balls into an urn. The value ![]() is the number of red balls in a sample of size
is the number of red balls in a sample of size ![]() that is drawn from the urn without replacement.
that is drawn from the urn without replacement.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The optional location parameter
. The optional location parameter ![]() has the default value
has the default value ![]() . The optional scale parameter
. The optional scale parameter ![]() has the default value
has the default value ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The optional location parameter
. The optional location parameter ![]() has the default value
has the default value ![]() . The optional scale parameter
. The optional scale parameter ![]() has the default value
has the default value ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The optional log-scale parameter
. The optional log-scale parameter ![]() has the default value
has the default value ![]() . The optional shape parameter
. The optional shape parameter ![]() has the default value
has the default value ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The parameter
. The parameter ![]() is the success probability with range
is the success probability with range ![]() . The parameter
. The parameter ![]() is an integer that counts the number of successes, with range
is an integer that counts the number of successes, with range ![]() .
.
Intuitively, ![]() is the number of failures before the
is the number of failures before the ![]() th success during a series of Bernoulli trials with probability of success
th success during a series of Bernoulli trials with probability of success ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The optional parameter
. The optional parameter ![]() (
(![]() ) is the mean (location) parameter, which has the default value
) is the mean (location) parameter, which has the default value ![]() . The optional parameter
. The optional parameter ![]() is the standard deviation, with the default value
is the standard deviation, with the default value ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
where ![]() is the normal PDF with mean
is the normal PDF with mean ![]() and standard deviation
and standard deviation ![]() , and where
, and where ![]() is a vector of probabilities such that
is a vector of probabilities such that
The parameters ![]() ,
, ![]() , and
, and ![]() are vectors with
are vectors with ![]() elements.
elements.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The shape parameter
. The shape parameter ![]() is valid for
is valid for ![]() . The optional scale parameter
. The optional scale parameter ![]() has the default value
has the default value ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The parameter
. The parameter ![]() is a rate parameter with range
is a rate parameter with range ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
![\[ f(x) = \frac{\Gamma \left(\frac{d+1}{2}\right)}{\sqrt {d\pi }\, \Gamma \left(\frac{d}{2}\right)}\left(1+\frac{x^2}{d}\right)^{-\frac{d+1}{2}} \]](images/imlug_langref1186.png)
The range of ![]() is
is ![]() . The parameter
. The parameter ![]() is the degrees of freedom, with the range
is the degrees of freedom, with the range ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
where ![]() is a vector of probabilities, such that
is a vector of probabilities, such that ![]() , and
, and ![]() is the largest integer such that
is the largest integer such that ![]() and
and
Notice that if ![]() , then the values of
, then the values of ![]() are in the range
are in the range ![]() .
.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The parameter
. The parameter ![]() is the horizontal location of the peak of the triangle, with range
is the horizontal location of the peak of the triangle, with range ![]() .
.
Tweedie distributions have three parameters: ![]() is the power parameter,
is the power parameter, ![]() is the mean of the distribution, and
is the mean of the distribution, and ![]() is a scale parameter. The default values for the optional parameters are
is a scale parameter. The default values for the optional parameters are ![]() and
and ![]() . The Tweedie distribution has the property that the variance of the distribution is equal to
. The Tweedie distribution has the property that the variance of the distribution is equal to ![]() .
.
The range of ![]() is
is ![]() . The density function is given by
. The density function is given by
where ![]() for
for ![]() and
and ![]() for
for ![]() . The function
. The function ![]() does not have an analytical expression, but is typically represented by an infinite series.
does not have an analytical expression, but is typically represented by an infinite series.
For most modeling tasks, ![]() . For
. For ![]() in this range, the Tweedie distribution is a sum of
in this range, the Tweedie distribution is a sum of ![]() gamma random variables, where
gamma random variables, where ![]() is Poisson distributed. For details, see the documentation for the SEVERITY procedure in the
SAS/ETS User's Guide. The documentation for the PDF function in
SAS Language Reference: Dictionary is also relevant.
is Poisson distributed. For details, see the documentation for the SEVERITY procedure in the
SAS/ETS User's Guide. The documentation for the PDF function in
SAS Language Reference: Dictionary is also relevant.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The parameters
. The parameters ![]() and
and ![]() default to the values
default to the values ![]() and
and ![]() . You must specify values for both
. You must specify values for both ![]() and
and ![]() if you do not want to use the default values.
if you do not want to use the default values.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The parameter
. The parameter ![]() is a shape parameter. The optional parameter
is a shape parameter. The optional parameter ![]() has the default value
has the default value ![]() .
.
Notice that many references, including the MCMC procedure, list ![]() as the first parameter for the inverse Gaussian distribution. However, the
as the first parameter for the inverse Gaussian distribution. However, the ![]() parameter is listed last for the RAND, PDF, CDF, and QUANTILE functions because it an optional parameter.
parameter is listed last for the RAND, PDF, CDF, and QUANTILE functions because it an optional parameter.
The values of ![]() are drawn from the probability density function:
are drawn from the probability density function:
The range of ![]() is
is ![]() . The shape parameters
. The shape parameters ![]() and
and ![]() are have values
are have values ![]() and
and ![]() .
.
Table 24.5 describes how parameters of the RANDGEN call correspond to the distribution parameters.
Table 24.5: Parameter Assignments for Distributions
|
Distribution |
distname |
parm1 |
parm2 |
parm3 |
|---|---|---|---|---|
|
Bernoulli |
'BERNOULLI' |
|
||
|
Beta |
'BETA' |
|
|
|
|
Binomial |
'BINOMIAL' |
|
|
|
|
Cauchy |
'CAUCHY' |
|||
|
Chi-Square |
'CHISQUARE' |
|
||
|
Erlang |
'ERLANG' |
|
<
|
|
|
Exponential |
'EXPONENTIAL' |
<
|
||
|
|
'F' |
|
|
|
|
Gamma |
'GAMMA' |
|
<
|
|
|
Geometric |
'GEOMETRIC' |
|
||
|
Hypergeometric |
'HYPERGEOMETRIC' |
|
|
|
|
Laplace |
'LAPLACE' |
<
|
<
|
|
|
Logistic |
'LOGISTIC' |
<
|
<
|
|
|
Lognormal |
'LOGNORMAL' |
<
|
<
|
|
|
Negative Binomial |
'NEGBINOMIAL' |
|
|
|
|
Normal |
'NORMAL' |
<
|
<
|
|
|
Normal Mixture |
'NORMALMIX' |
|
|
|
|
Pareto |
'PARETO' |
|
<
|
|
|
Poisson |
'POISSON' |
|
||
|
|
'T' |
|
||
|
Table |
'TABLE' |
|
||
|
Triangle |
'TRIANGLE' |
|
||
|
Tweedie |
'TWEEDIE' |
|
<
|
<
|
|
Uniform |
'UNIFORM' |
<
|
<
|
|
|
Wald |
'WALD' or 'IGAUSS' |
|
<
|
|
|
Weibull |
'WEIBULL' |
|
|
The distname argument can be in lowercase or uppercase, and you need to specify only enough letters to distinguish one distribution from the others, as shown by the following statements:
/* generate 10 samples from a Bernoulli distribution */ r = j(10, 1, .); /* allocate room for samples */ call randgen(r, "ber", 0.5);
Optional arguments are enclosed in angle brackets, along with the default value when the argument is not specified. For example,
if you do not supply values for the parameters of the normal distribution, the default values of ![]() and
and ![]() are used.
are used.
The following example illustrates the RANDGEN call for various distributions:
call randseed(12345);
/* get four random observations from each distribution */
x = j(1, 4, .);
/* each row comes from a different distribution */
DiscreteDist = {'BERN','BINOM','GEOM','HYPER',
'NEGB','POISSON','TABLE'};
D = j(nrow(DiscreteDist), 4, .);
i = 1;
call randgen(x, 'BERN', 0.75); D[i, ] = x; i = i+1;
call randgen(x, 'BINOM', 0.75, 10); D[i, ] = x; i = i+1;
call randgen(x, 'GEOM', 0.02); D[i, ] = x; i = i+1;
call randgen(x, 'HYPER', 10, 3, 5); D[i, ] = x; i = i+1;
call randgen(x, 'NEGB', 0.8, 5); D[i, ] = x; i = i+1;
call randgen(x, 'POISSON', 6.1); D[i, ] = x; i = i+1;
p = {0.2 0.5 0.3};
call randgen(x, 'TABLE', p); D[i, ] = x; i = i+1;
print D[rowname=DiscreteDist label="Discrete"];
ContinDist = {'BETA','CAUCHY','CHISQ','ERLANG','EXPO',
'F','GAMMA','LAPLACE','LOGISTIC','LOGN',
'NORMAL','NORMALMIX','PARETO','T',
'TRIANGLE','TWEEDIE','UNIFORM','WALD','WEIB'};
C = j(nrow(ContinDist), 4, .);
i = 1;
call randgen(x, 'BETA', 3, 0.1); C[i, ] = x; i = i+1;
call randgen(x, 'CAUCHY'); C[i, ] = x; i = i+1;
call randgen(x, 'CHISQ', 22); C[i, ] = x; i = i+1;
call randgen(x, 'ERLANG', 7); C[i, ] = x; i = i+1;
call randgen(x, 'EXPO'); C[i, ] = x; i = i+1;
call randgen(x, 'F', 12, 322); C[i, ] = x; i = i+1;
call randgen(x, 'GAMMA', 7.25); C[i, ] = x; i = i+1;
call randgen(x, 'LAPLACE'); C[i, ] = x; i = i+1;
call randgen(x, 'LOGISTIC'); C[i, ] = x; i = i+1;
call randgen(x, 'LOGN'); C[i, ] = x; i = i+1;
call randgen(x, 'NORMAL'); C[i, ] = x; i = i+1;
p = {0.2 0.5 0.3}; mu = {0 5 10}; sig = {1 1 2};
call randgen(x, 'NORMALMIX',p,mu,sig); C[i,] = x; i = i+1;
call randgen(x, 'PARETO', 3, 1); C[i, ] = x; i = i+1;
call randgen(x, 'T', 4); C[i, ] = x; i = i+1;
call randgen(x, 'TRIANGLE', 0.7); C[i, ] = x; i = i+1;
call randgen(x, 'TWEEDIE', 1.7); C[i, ] = x; i = i+1;
call randgen(x, 'UNIFORM'); C[i, ] = x; i = i+1;
call randgen(x, 'WALD', 1, 2); C[i, ] = x; i = i+1;
call randgen(x, 'WEIB', 0.25, 2.1); C[i, ] = x; i = i+1;
print C[rowname=ContinDist label="Continuous"];
Figure 24.299: Random Numbers from Various Distributions
| Discrete | ||||
|---|---|---|---|---|
| BERN | 1 | 0 | 1 | 0 |
| BINOM | 6 | 8 | 7 | 8 |
| GEOM | 22 | 29 | 132 | 4 |
| HYPER | 1 | 2 | 3 | 2 |
| NEGB | 1 | 1 | 1 | 3 |
| POISSON | 10 | 2 | 11 | 5 |
| TABLE | 2 | 2 | 2 | 2 |
| Continuous | ||||
|---|---|---|---|---|
| BETA | 0.9698912 | 0.9986741 | 0.9530356 | 0.9999999 |
| CAUCHY | -0.351223 | -79.19193 | -0.875086 | 0.2633447 |
| CHISQ | 16.501429 | 10.905074 | 21.223624 | 15.693628 |
| ERLANG | 3.9509215 | 3.9110053 | 12.242025 | 4.2987446 |
| EXPO | 0.1435695 | 0.6908117 | 0.2160011 | 1.41259 |
| F | 0.5212328 | 0.7306928 | 1.0089965 | 0.9442868 |
| GAMMA | 6.6019823 | 11.56066 | 10.237334 | 2.6774555 |
| LAPLACE | -0.084906 | 2.9727044 | 2.7944056 | -1.302167 |
| LOGISTIC | 0.1334806 | -1.613977 | -0.528595 | -0.418451 |
| LOGN | 1.2039346 | 1.5589409 | 0.2231522 | 0.1560639 |
| NORMAL | 1.2507254 | -0.779791 | -1.716859 | 0.091384 |
| NORMALMIX | 1.5133453 | 3.1300929 | 4.4290679 | 5.3063411 |
| PARETO | 1.2940105 | 1.0310942 | 1.4971162 | 1.2676456 |
| T | 0.2666685 | 0.2312119 | -0.047974 | -0.069328 |
| TRIANGLE | 0.3098931 | 0.3216791 | 0.7828233 | 0.6975677 |
| TWEEDIE | 0.0256424 | 1.7446859 | 2.8313134 | 0.6429287 |
| UNIFORM | 0.9101531 | 0.4957422 | 0.6919957 | 0.7501369 |
| WALD | 0.3298129 | 2.4390822 | 0.3872 | 1.6025807 |
| WEIB | 0.000166 | 62.455757 | 17.343105 | 0.0000656 |