Example 14.7 A Two-Equation Maximum Likelihood Problem
The following example and notation are taken from Bard (1974). A two-equation model is used to fit U.S. production data for the years 1909–1949, where 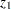 is capital input,
is capital input, 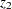 is labor input,
is labor input, 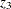 is real output,
is real output, 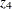 is time in years (with 1929 as the origin), and
is time in years (with 1929 as the origin), and 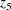 is the ratio of price of capital services to wage scale. The data can be entered by using the following statements:
is the ratio of price of capital services to wage scale. The data can be entered by using the following statements:
proc iml;
z={ 1.33135 0.64629 0.4026 -20 0.24447,
1.39235 0.66302 0.4084 -19 0.23454,
1.41640 0.65272 0.4223 -18 0.23206,
1.48773 0.67318 0.4389 -17 0.22291,
1.51015 0.67720 0.4605 -16 0.22487,
1.43385 0.65175 0.4445 -15 0.21879,
1.48188 0.65570 0.4387 -14 0.23203,
1.67115 0.71417 0.4999 -13 0.23828,
1.71327 0.77524 0.5264 -12 0.26571,
1.76412 0.79465 0.5793 -11 0.23410,
1.76869 0.71607 0.5492 -10 0.22181,
1.80776 0.70068 0.5052 -9 0.18157,
1.54947 0.60764 0.4679 -8 0.22931,
1.66933 0.67041 0.5283 -7 0.20595,
1.93377 0.74091 0.5994 -6 0.19472,
1.95460 0.71336 0.5964 -5 0.17981,
2.11198 0.75159 0.6554 -4 0.18010,
2.26266 0.78838 0.6851 -3 0.16933,
2.33228 0.79600 0.6933 -2 0.16279,
2.43980 0.80788 0.7061 -1 0.16906,
2.58714 0.84547 0.7567 0 0.16239,
2.54865 0.77232 0.6796 1 0.16103,
2.26042 0.67880 0.6136 2 0.14456,
1.91974 0.58529 0.5145 3 0.20079,
1.80000 0.58065 0.5046 4 0.18307,
1.86020 0.62007 0.5711 5 0.18352,
1.88201 0.65575 0.6184 6 0.18847,
1.97018 0.72433 0.7113 7 0.20415,
2.08232 0.76838 0.7461 8 0.18847,
1.94062 0.69806 0.6981 9 0.17800,
1.98646 0.74679 0.7722 10 0.19979,
2.07987 0.79083 0.8557 11 0.21115,
2.28232 0.88462 0.9925 12 0.23453,
2.52779 0.95750 1.0877 13 0.20937,
2.62747 1.00285 1.1834 14 0.19843,
2.61235 0.99329 1.2565 15 0.18898,
2.52320 0.94857 1.2293 16 0.17203,
2.44632 0.97853 1.1889 17 0.18140,
2.56478 1.02591 1.2249 18 0.19431,
2.64588 1.03760 1.2669 19 0.19492,
2.69105 0.99669 1.2708 20 0.17912 };
The two-equation model in five parameters 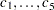 is
is
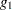 |
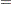 |
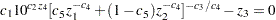 |
|||
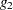 |
|
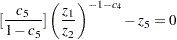 |
where the variables and are considered dependent (endogenous) and the variables , , and are considered independent (exogenous).
Differentiation of the two equations 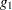 and
and 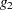 with respect to the endogenous variables and yields the Jacobian matrix
with respect to the endogenous variables and yields the Jacobian matrix 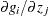 for
for 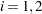 and
and 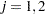 , where
, where 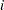 corresponds to rows (equations) and
corresponds to rows (equations) and 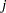 corresponds to endogenous variables (refer to Bard (1974)). You must consider parameter sets for which the elements of the Jacobian and the logarithm of the determinant cannot be computed. In such cases, the function module must return a missing value. Here is the code:
corresponds to endogenous variables (refer to Bard (1974)). You must consider parameter sets for which the elements of the Jacobian and the logarithm of the determinant cannot be computed. In such cases, the function module must return a missing value. Here is the code:
start fiml(pr) global(z);
c1 = pr[1]; c2 = pr[2]; c3 = pr[3]; c4 = pr[4]; c5 = pr[5];
/* 1. Compute Jacobian */
lndet = 0 ;
do t= 1 to 41;
j11 = (-c3/c4) * c1 * 10 ##(c2 * z[t,4]) * (-c4) * c5 *
z[t,1]##(-c4-1) * (c5 * z[t,1]##(-c4) + (1-c5) *
z[t,2]##(-c4))##(-c3/c4 -1);
j12 = (-c3/c4) * (-c4) * c1 * 10 ##(c2 * z[t,4]) * (1-c5) *
z[t,2]##(-c4-1) * (c5 * z[t,1]##(-c4) + (1-c5) *
z[t,2]##(-c4))##(-c3/c4 -1);
j21 = (-1-c4)*(c5/(1-c5))*z[t,1]##( -2-c4)/ (z[t,2]##(-1-c4));
j22 = (1+c4)*(c5/(1-c5))*z[t,1]##( -1-c4)/ (z[t,2]##(-c4));
j = (j11 || j12 ) // (j21 || j22) ;
if any(j = .) then detj = 0.;
else detj = det(j);
if abs(detj) < 1.e-30 then do;
print t detj j;
return(.);
end;
lndet = lndet + log(abs(detj));
end;
Assuming that the residuals of the two equations are normally distributed, the likelihood is then computed as in Bard (1974). The following code computes the logarithm of the likelihood function:
/* 2. Compute Sigma */
sb = j(2,2,0.);
do t= 1 to 41;
eq_g1 = c1 * 10##(c2 * z[t,4]) * (c5*z[t,1]##(-c4)
+ (1-c5)*z[t,2]##(-c4))##(-c3/c4) - z[t,3];
eq_g2 = (c5/(1-c5)) * (z[t,1] / z[t,2])##(-1-c4) - z[t,5];
resid = eq_g1 // eq_g2;
sb = sb + resid * resid`;
end;
sb = sb / 41;
/* 3. Compute log L */
const = 41. * (log(2 * 3.1415) + 1.);
lnds = 0.5 * 41 * log(det(sb));
logl = const - lndet + lnds;
return(logl);
finish fiml;
There are potential problems in computing the power and log functions for an unrestricted parameter set. As a result, optimization algorithms that use line search fail more often than algorithms that restrict the search area. For that reason, the NLPDD subroutine is used in the following code to maximize the log-likelihood function:
pr = j(1,5,0.001);
optn = {0 2};
tc = {. . . 0};
call nlpdd(rc, xr,"fiml", pr, optn,,tc);
print "Start" pr, "RC=" rc, "Opt Par" xr;
Part of the iteration history is shown in Output 14.7.1.
| Optimization Start | |||
|---|---|---|---|
| Active Constraints | 0 | Objective Function | 909.72691311 |
| Max Abs Gradient Element | 41115.729089 | Radius | 1 |
| Iteration | Restarts | Function Calls |
Active Constraints |
Objective Function |
Objective Function Change |
Max Abs Gradient Element |
Lambda | Slope of Search Direction |
||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 2 | 0 | 85.24836 | 824.5 | 3676.4 | 711.8 | -71032 | ||
| 2 | 0 | 7 | 0 | 45.14682 | 40.1015 | 3382.0 | 2881.2 | -29.683 | ||
| 3 | 0 | 10 | 0 | 43.46797 | 1.6788 | 208.4 | 95.020 | -3.348 | ||
| 4 | 0 | 17 | 0 | -32.75902 | 76.2270 | 1067.1 | 0.487 | -39.170 | ||
| 5 | 0 | 20 | 0 | -56.10951 | 23.3505 | 2152.7 | 1.998 | -44.198 | ||
| 6 | 0 | 24 | 0 | -56.95091 | 0.8414 | 1210.7 | 32.319 | -1.661 | ||
| 7 | 0 | 25 | 0 | -57.62218 | 0.6713 | 1232.8 | 2.411 | -0.676 | ||
| 8 | 0 | 26 | 0 | -58.44199 | 0.8198 | 1495.4 | 1.988 | -0.813 | ||
| 9 | 0 | 27 | 0 | -59.49591 | 1.0539 | 1218.7 | 1.975 | -1.048 | ||
| 10 | 0 | 28 | 0 | -61.01455 | 1.5186 | 1471.5 | 1.949 | -1.518 | ||
| 11 | 0 | 31 | 0 | -67.84243 | 6.8279 | 1084.9 | 1.068 | -14.681 | ||
| 12 | 0 | 33 | 0 | -69.86835 | 2.0259 | 2082.9 | 1.676 | -7.128 | ||
| 13 | 0 | 34 | 0 | -72.09162 | 2.2233 | 1066.7 | 0.693 | -2.150 | ||
| 14 | 0 | 35 | 0 | -73.68547 | 1.5939 | 731.5 | 0 | -1.253 | ||
| 15 | 0 | 36 | 0 | -75.52559 | 1.8401 | 712.3 | 0 | -1.007 | ||
| 16 | 0 | 38 | 0 | -89.36430 | 13.8387 | 5158.5 | 0 | -9.584 | ||
| 17 | 0 | 39 | 0 | -100.86225 | 11.4980 | 1195.9 | 0.615 | -11.029 | ||
| 18 | 0 | 40 | 0 | -104.82085 | 3.9586 | 3196.0 | 0.439 | -7.469 | ||
| 19 | 0 | 41 | 0 | -108.52444 | 3.7036 | 615.0 | 0 | -2.828 | ||
| 20 | 0 | 42 | 0 | -110.16244 | 1.6380 | 938.0 | 0.278 | -1.436 | ||
| 21 | 0 | 43 | 0 | -110.69114 | 0.5287 | 1211.0 | 0.242 | -0.692 | ||
| 22 | 0 | 44 | 0 | -110.74189 | 0.0508 | 405.9 | 0 | -0.0598 | ||
| 23 | 0 | 45 | 0 | -110.75511 | 0.0132 | 188.3 | 0 | -0.0087 | ||
| 24 | 0 | 46 | 0 | -110.76826 | 0.0131 | 19.1454 | 0.424 | -0.0110 | ||
| 25 | 0 | 47 | 0 | -110.77808 | 0.00983 | 62.9009 | 0 | -0.0090 | ||
| 26 | 0 | 48 | 0 | -110.77855 | 0.000460 | 27.8326 | 0 | -0.0004 | ||
| 27 | 0 | 49 | 0 | -110.77858 | 0.000036 | 1.1786 | 0 | -34E-6 | ||
| 28 | 0 | 50 | 0 | -110.77858 | 4.343E-7 | 0.0298 | 0 | -325E-9 | ||
| 29 | 0 | 51 | 0 | -110.77858 | 2.013E-8 | 0.0407 | 0 | -91E-10 | ||
| 30 | 0 | 52 | 0 | -110.77858 | 6.42E-10 | 0.000889 | 0 | -64E-12 | ||
| 31 | 0 | 53 | 0 | -110.77858 | 7.45E-11 | 0.000269 | 0 | -33E-14 | ||
| 31 | 0 | 54 | 0 | -110.77858 | 0 | 0.000269 | 0 | -29E-15 |
| Optimization Results | |||
|---|---|---|---|
| Iterations | 31 | Function Calls | 55 |
| Gradient Calls | 33 | Active Constraints | 0 |
| Objective Function | -110.7785811 | Max Abs Gradient Element | 0.0002692596 |
| Slope of Search Direction | -2.87287E-14 | Radius | 4.8698304E-7 |
The results are very close to those reported by Bard (1974). Bard also reports different approaches to the same problem that can lead to very different MLEs.
| Optimization Results | |||
|---|---|---|---|
| Parameter Estimates | |||
| N | Parameter | Estimate | Gradient Objective Function |
| 1 | X1 | 0.583884 | 0.000014451 |
| 2 | X2 | 0.005882 | 0.000269 |
| 3 | X3 | 1.362817 | 0.000001614 |
| 4 | X4 | 0.475091 | -0.000001293 |
| 5 | X5 | 0.447072 | 0.000015817 |