Example 14.4 MLEs for Two-Parameter Weibull Distribution
This example considers a data set given in Lawless (1982). The data are the number of days it took rats painted with a carcinogen to develop carcinoma. The last two observations are censored. Maximum likelihood estimates (MLEs) and confidence intervals for the parameters of the Weibull distribution are computed. In the following code, the data set is given in the vector CARCIN, and the variables P and M give the total number of observations and the number of uncensored observations. The set 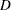 represents the indices of the observations.
represents the indices of the observations.
proc iml;
carcin = { 143 164 188 188 190 192 206
209 213 216 220 227 230 234
246 265 304 216 244 };
p = ncol(carcin); m = p - 2;
The three-parameter Weibull distribution uses three parameters: a scale parameter, a shape parameter, and a location parameter. This example computes MLEs and corresponding 95% confidence intervals for the scale parameter,  , and the shape parameter,
, and the shape parameter,  , for a constant value of the location parameter,
, for a constant value of the location parameter, 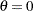 . The program can be generalized to estimate all three parameters. Note that Lawless (1982) denotes , , and
. The program can be generalized to estimate all three parameters. Note that Lawless (1982) denotes , , and 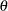 by
by  ,
, 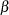 , and
, and 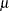 , respectively.
, respectively.
The observed likelihood function of the three-parameter Weibull distribution is
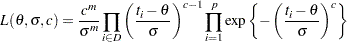 |
The log likelihood, 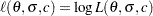 , is
, is
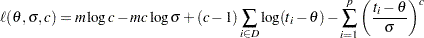 |
The log-likelihood function, 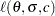 , for is the objective function to be maximized to obtain the MLEs
, for is the objective function to be maximized to obtain the MLEs 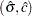 . The following statements define the function:
. The following statements define the function:
start f_weib2(x) global(carcin,thet);
/* x[1]=sigma and x[2]=c */
p = ncol(carcin); m = p - 2;
sum1 = 0.; sum2 = 0.;
do i = 1 to p;
temp = carcin[i] - thet;
if i <= m then sum1 = sum1 + log(temp);
sum2 = sum2 + (temp / x[1])##x[2];
end;
f = m*log(x[2]) - m*x[2]*log(x[1]) + (x[2]-1)*sum1 - sum2;
return(f);
finish f_weib2;
The derivatives of 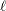 with respect to the parameters , , and are given in Lawless (1982). The following code specifies a gradient module, which computes
with respect to the parameters , , and are given in Lawless (1982). The following code specifies a gradient module, which computes 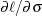 and
and 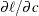 :
:
start g_weib2(x) global(carcin,thet);
/* x[1]=sigma and x[2]=c */
p = ncol(carcin); m = p - 2;
g = j(1,2,0.);
sum1 = 0.; sum2 = 0.; sum3 = 0.;
do i = 1 to p;
temp = carcin[i] - thet;
if i <= m then sum1 = sum1 + log(temp);
sum2 = sum2 + (temp / x[1])##x[2];
sum3 = sum3 + ((temp / x[1])##x[2]) * (log(temp / x[1]));
end;
g[1] = -m * x[2] / x[1] + sum2 * x[2] / x[1];
g[2] = m / x[2] - m * log(x[1]) + sum1 - sum3;
return(g);
finish g_weib2;
The MLEs are computed by maximizing the objective function with the trust-region algorithm in the NLPTR subroutine. The following code specifies starting values for the two parameters, 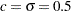 , and to avoid infeasible values during the optimization process, it imposes lower bounds of
, and to avoid infeasible values during the optimization process, it imposes lower bounds of 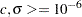 . The optimal parameter values are saved in the variable XOPT, and the optimal objective function value is saved in the variable FOPT.
. The optimal parameter values are saved in the variable XOPT, and the optimal objective function value is saved in the variable FOPT.
n = 2; thet = 0.;
x0 = j(1,n,.5);
optn = {1 2};
con = { 1.e-6 1.e-6 ,
. . };
call nlptr(rc,xres,"f_weib2",x0,optn,con,,,,"g_weib2");
/*--- Save result in xopt, fopt ---*/
xopt = xres`; fopt = f_weib2(xopt);
The results shown in Output 14.4.1 are the same as those given in Lawless (1982).
| Optimization Results | |||
|---|---|---|---|
| Parameter Estimates | |||
| N | Parameter | Estimate | Gradient Objective Function |
| 1 | X1 | 234.318611 | 1.33651E-9 |
| 2 | X2 | 6.083147 | -7.868212E-9 |
The following code computes confidence intervals based on the asymptotic normal distribution. These are compared with the profile-likelihood-based confidence intervals computed in the next example. The diagonal of the inverse Hessian (as calculated by the NLPFDD subroutine) is used to calculate the standard error.
call nlpfdd(f,g,hes2,"f_weib2",xopt,,"g_weib2"); hin2 = inv(hes2); /* quantile of normal distribution */ prob = .05; noqua = probit(1. - prob/2); stderr = sqrt(abs(vecdiag(hin2))); xlb = xopt - noqua * stderr; xub = xopt + noqua * stderr; print "Normal Distribution Confidence Interval"; print xlb xopt xub;
| Normal Distribution Confidence Interval |
| xlb | xopt | xub | |
|---|---|---|---|
| 215.41298 | 234.31861 | 6.0831471 | 253.22425 |
| 3.9894574 | 8.1768368 |